Sample Rate
Detailed Guide on Sample Rate for ASR! [2023]
Explore the intricacies of audio sample rates and their impact on ASR model development. Understand how to choose the right sample rate
Sample Rate
Explore the intricacies of audio sample rates and their impact on ASR model development. Understand how to choose the right sample rate

In our blog, we love exploring a bunch of cool AI stuff, like making computers understand speech, recognize things in pictures, create art, chat like humans, read handwriting, and much more!
Today, we're diving deep into a crucial aspect of training speech recognition models: the sample rate. We'll keep things simple and explain why it's a big deal.
By the end of this blog, you'll know exactly how to pick the perfect sample rate for your speech recognition project and why it matters so much! So, let's get started!
Automatic Speech Recognition, or ASR for short, is a branch of artificial intelligence dedicated to the conversion of spoken words into written text. For an ASR model to effectively understand any language, it must undergo rigorous training using a substantial amount of spoken language data in that particular language.
This speech dataset comprises audio files recorded in the target language, along with their corresponding transcriptions. These audio files consist of recordings featuring human speech, and a crucial technical aspect of these files is the sample rate along with bit depth, format etc. We will discuss other technical features later in the future.
When training our ASR model, we have two main options: utilizing open-source datasets, off-the-shelf datasets, or creating our own custom training dataset. In the case of open-source or off-the-shelf datasets, it is essential to verify the sample rate at which the audio data was recorded. For custom speech dataset collection, it is equally vital to ensure that all audio data is recorded at the specified sample rate.
In summary, the selection of audio files with the required sample rate plays a pivotal role in the ASR training process. To gain a deeper understanding of sample rate, let's delve into its intricacies.
Let's dive into the concept of sample rate. In simple terms, sample rate refers to the number of audio samples captured in one second. You might also hear it called sampling frequency or sampling rate.
To measure the sample rate, we use Hertz (Hz) as the unit of measurement. Often, you'll see it expressed in kilohertz (kHz) in everyday discussions.
Now, let's visualize what the sample rate looks like on an audio graph.
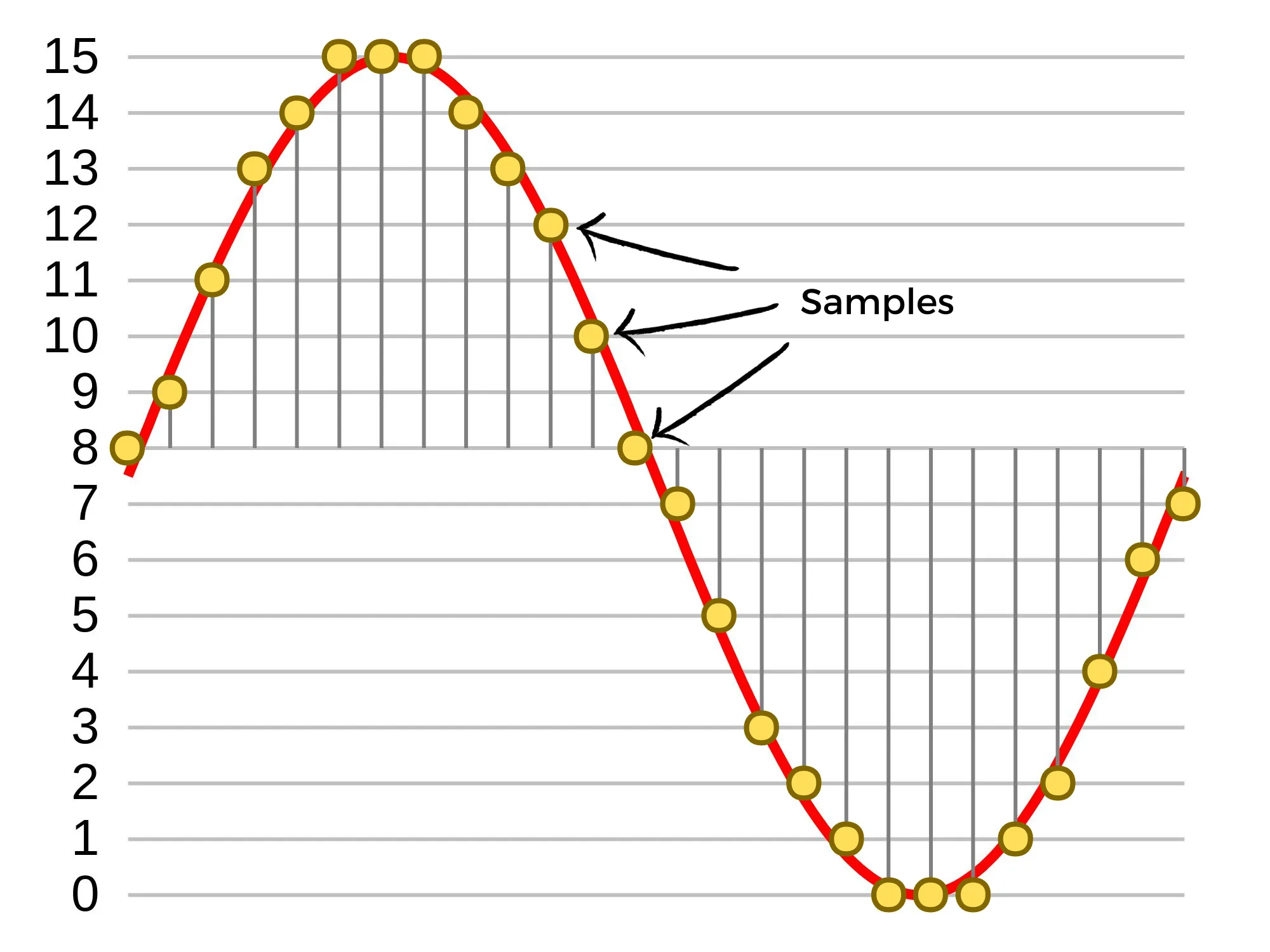 The red line in the graph represents the sound signal, while the yellow dots scattered along it represent individual samples. Think of sample rate as a measure of how many of these samples are taken in a single second. For instance, if you have an audio file with an 8 kHz sample rate, it means that 8,000 samples are captured per second for that audio file.
The red line in the graph represents the sound signal, while the yellow dots scattered along it represent individual samples. Think of sample rate as a measure of how many of these samples are taken in a single second. For instance, if you have an audio file with an 8 kHz sample rate, it means that 8,000 samples are captured per second for that audio file.
Now, imagine you want to recreate the sound signal from these samples. Which scenario do you think would make it easier: having a high sample rate or a low one?
To clarify, think of the graph again. If you have more dots (samples), you can reconstruct the sound signal more accurately compared to having fewer dots. Essentially, a higher sample rate means a more detailed representation of the audio signal, allowing you to encode more information and ultimately resulting in better audio quality.
So, if you have two audio files, one with an 8 kHz sample rate and another with a 48 kHz sample rate, the 48 kHz file will generally sound much better.
Let's dive into why a higher sample rate allows for more information to be encoded.
Picture trying to capture images of a fast-moving car on a road. Your frequency of capturing images can be likened to the sample rate. If your capture frequency is too low, you'll miss important moments because the car is moving too quickly.
But if your capture frequency is high, you can capture each crucial moment, making it possible to faithfully reproduce the visual.
This same principle applies to audio. If your sample rate is low, meaning you're capturing fewer sound signals in a given time, you might miss subtle nuances in speech. Consequently, when you attempt to reproduce the audio, it won't match the original quality.
However, when you have a high enough sample rate, you capture all the nuances of speech, enabling accurate audio reproduction.
In fact, with a sufficiently high sample rate, you can reproduce audio so accurately that humans can't distinguish it from the original.
But what qualifies as a "high enough" sample rate? Does this mean that a higher sample rate is always better?
Not necessarily. Using the image analogy again, if your capture frequency is excessively high, you might end up with duplicate images. Similarly, in audio, an excessively high sample rate can capture unnecessary background noise and other irrelevant details.
To determine the right sample rate, we turn to Nyquist's theorem. This theorem suggests that to avoid aliasing and accurately capture a signal, you should sample it at a rate at least twice the highest frequency you want to capture.
For humans, our ears are sensitive to frequencies between 20 Hz and 20 kHz. Following Nyquist, the optimal sample rate for us would be 40 kHz. This is why most music CDs are recorded with sample rates of 44 kHz to 48 kHz, with the additional 4 kHz to 8 kHz serving as a buffer to prevent data loss during the analog-to-digital conversion process.
However, despite its high audio quality, a 48 kHz audio file may not be suitable for training Automatic Speech Recognition (ASR) models due to several reasons:
1.Computational Power:
High sample rates require more computational power, making them less practical for certain applications.
2.Power Consumption:
Increased computational demands result in higher power consumption, leading to a larger carbon footprint.
3.File Size:
Audio files with higher sample rates have larger file sizes, necessitating more storage space.
4.Data Transmission:
Larger file sizes also mean slower data transmission between modules.
5.Noise Amplification:
As discussed earlier, higher sample rate the audio signal will try to contain more information and it sometimes captures the background noise as well which can lead to noise amplification as well.
6.Compatibility:
Not all ASR systems or AI modules support high sample rates, which can limit interoperability.
Now the question is, then how to choose the optimal sample rate for the ASR system? Let’s find out its answer.
It primarily depends on the use case and the frequency range of human speech. Human speech intelligibility typically falls within the range of 300 Hz to 3400 Hz. Doubling the upper limit according to Nyquist, a sample rate of around 8000 Hz is sufficient to capture human voice accurately. This is why 8 kHz is commonly used in speech recognition systems, telecommunication channels, and codecs.
With enough quality 8 kHz also brings the advantages of lower computational power, power consumption, and lower amount of data that needs to be transferred. But that doesn’t mean 8 kHz is the best quality, it’s rather a sweet spot between the tradeoff of quality and limitation.
As mentioned earlier choosing the right sample rate also depends upon the use case. Many HD voice devices use 16 kHz as it provides more accurate high-frequency information compared to 8 kHz. So it’s like if you have more computational power to train your AI model you can choose 16 kHz in place of 8 kHz.
In most cases, ASR models for voice recognition tasks often do not require sample rates exceeding 22 kHz. On the other hand, in scenarios where exceptional audio quality is essential, such as music and audio production, a sample rate of 44 kHz to 48 kHz is preferred.
For Text-to-Speech (TTS) applications, which require detailed acoustic characteristics, sample rates of 22.05 kHz, 32 kHz, 44.1 kHz, or 48 kHz are used to ensure accurate audio reproduction from text.
We are clear till now that choosing the optimal sample rate depends on your use case. Below are some of the common ASR use cases and generally used sample rates for them.
Voice Assistants (e.g., Siri, Alexa, Google Assistant):
- Optimal Sample Rate: 16 kHz to 48 kHz
- These applications prioritize high-quality audio for natural language understanding. Sample rates between 16 kHz and 48 kHz are often used to capture clear and detailed voice input.
Conversational AI, Telephony, and IVR Systems:
- Optimal Sample Rate: 8 kHz
- Traditional telephone systems, Interactive Voice Response (IVR) systems, and call center asr solutions typically use an 8 kHz sample rate to match telephony standards.
Transcription Services (e.g., Speech-to-Text):
- Optimal Sample Rate: 16 kHz to 48 kHz
- When transcribing spoken content for applications like transcription services, podcasts, or video captions, higher sample rates in the range of 16 kHz to 48 kHz are often preferred for accuracy.
Medical Transcription and Dictation:
- Optimal Sample Rate: 16 kHz to 48 kHz
- Medical transcription and dictation applications typically benefit from higher sample rates to capture medical professionals' detailed speech accurately.
Remember that the optimal sample rate can vary based on the specific requirements and constraints of each ASR use case. It's essential to conduct testing and evaluation to determine the best sample rate for your application while considering factors like audio quality, computational resources, and the intended environment.
We at FutureBeeAI assist AI organizations working on any ASR use cases with our extensive speech data offerings. With our pre-made datasets including general conversation, call center conversation or scripted monologue you can scale your AI model development. All of these datasets are diverse across 40+ languages and 6+ industries. You can check out all the published speech data here.
 Along with that with our state-of-the-art mobile application and global crowd community, you can collect custom speech datasets as per your tailored requirements. Our data collection mobile application Yugo allows you to record both scripted and conversational speech data with flexible technical features like sample rate, bit depth, file format, and audio channels. Check out our Yugo application here.
Along with that with our state-of-the-art mobile application and global crowd community, you can collect custom speech datasets as per your tailored requirements. Our data collection mobile application Yugo allows you to record both scripted and conversational speech data with flexible technical features like sample rate, bit depth, file format, and audio channels. Check out our Yugo application here.
Feel free to reach out to us in case you need any help with training datasets for your ASR use cases. We would love to assist you!
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





