Speech recognition technology has revolutionized the way we interact with computers and devices. From virtual assistants to transcription services, automatic speech recognition (ASR) models play a vital role in converting spoken language into written text. However, building an accurate and robust ASR model requires careful preparation of training data.
So, if you are building an ASR from scratch or fine tuning any pre-training model, then this blog is for you to understand all the required steps. Let’s start with the basics of Speech Recognition.
What is Speech Recognition?
Speech recognition (SR) is an impressive technology that empowers computers to understand spoken language. To achieve this feat, SR models undergo rigorous training on vast datasets of audio recordings and their corresponding text transcriptions. The process of speech recognition involves several intricate steps, each contributing to the model's ability to comprehend spoken words seamlessly.
Speech Signal Processing
The journey begins with speech signal processing, where the audio recording undergoes meticulous analysis to extract essential acoustic features. These features include pitch, loudness, and duration, all of which play a crucial role in understanding the nuances of speech.
Feature Classification
Once the acoustic features are extracted, they are skillfully classified into phonemes, the elemental building blocks of speech. Phonemes represent distinct sound units that form the foundation of language.
Word Decoding
With the phonemes at hand, the next challenge is to decode them into meaningful words. This is where a language model comes into play. The language model is a sophisticated statistical model that predicts the probability of a word occurring based on the context of the previous words in the sentence. It helps the system make educated guesses about the intended words, enhancing accuracy and understanding.
If you are an ASR developer, you might be aware of these steps and their complexity. The training journey of any ASR model starts with Speech signal processing if you have the training data. If you don’t have use case specific training data, you will not be able to start the training process. On the other hand poor quality data will give results with high word error rate and may not be suitable to your use case.
Let’s take a deep dive into data preparation for the ASR model for Banking use case.
Training Data Preparation Process for ASR
Training data preparation starts after finalizing use cases, stakeholders, language, difficulties, availability or hardware, etc. Let’s assume we have all the hardware, expert developers and we have finalized a Banking use case that can handle queries in Bulgarian language.
Now we want our model to understand Bulgarian languages and banking related terminology for different services and issues. For this training data prepation will need a few steps:
Understand Domain: In our case It’s Banking
In the context of our banking application, it's important to consider that our users primarily engage with the bank's services through their mobile devices. This means that the quality of audio interactions can vary depending on the specific devices they are using. To ensure the best possible experience for our customers, we should tailor our model training to accommodate these factors.
Given that our customers rely on mobile devices for their interactions, it's advisable to train our audio processing model using audio samples that have a sample rate of 8 kHz or a maximum of 16 kHz. This choice of sample rate aligns with the audio capabilities of typical mobile devices and allows our model to better capture and process the nuances of the audio data it will encounter during real-time interactions.
Also, in the Banking domain the ASR model needs to handle queries related to account opening saving, current or joint, credit and debit card queries, transaction issues, home loan queries, interest rate, fixed deposits, etc.
To make our speech model understand all the above mentioned terminology we will need data especially curated for this use case.
Define Data Type, Guidelines and Diversity
We want to build an ASR that can handle banking queries so we will need speech data with transcription. In general we define domain specific datasets as contact center or call center speech datasets. For collecting banking specific data we can buy data from contact centers and then we can transcribe them, but in most cases real call centers are not allowed to sell their data because of data privacy issues. So, the only option we left with is to collect new data.
The language we are working on is Bulgarian, the only official language of Bulgaria. Approx 5 million speaks Bulgarian that includes all age groups, and genders. So, before we design the distribution we should know the demographic distribution and in countries like Bulgaria all genders use baking services equally, so depending on that we can choose a 50:50 ratio for gender distribution.
In some use cases maybe the female users are more compared to male users then we can alternet the gender ratio. Let’s make a table that can give a better idea,
Age Group
Female Count
Male Count
Total Count
Gender ratio
18-30
1200
1200
2400
1:1
30-40
1500
1500
3000
1:1
40-50
1500
1500
3000
1:1
50-60
1200
1200
2400
1:1
60+
500
500
1000
1:1
Total
5900
5900
11800
1:1
Here you can see we have distributed the collection of the data over different age groups with different numbers of participants. This distribution totally depends on demographic information, use case complexity and the technology.
So, finally we have chosen the languages, data type and distribution.
Use case
Banking
Language
Bulgarian
Data Type
Speech Data with Transcription
Demographic Distribution
Total 11800 participant with gender ratio 1:1
Based on the distribution we can choose a data partner or can collect the data internally.
Data Sources
Now as we have our distribution ready, we can look for different data sources. We can take help from contact centers to provide us with the required data but we still need someone to transcribe the data. Also there is less possibility that the call centers will give you their data because of privacy concerns. In this case we can take help from data service providers.
Data providers like FutureBeeAI have predefined guidelines for collecting use case specific datasets. We can take advantage of data providers' experience and can solve this data challenge.
Data collection is not an easy task and needs expertise, tools and human in loop to collect high-quality datasets. After choosing the right data partner or deciding to collect data internally the next step is collect the data.
 Data Collection
Data Collection
In this step the data providers will give proper training to participants and define how an agent and customer should behave. They will also define the final outcomes of the calls like positive, negative and neutral.
As a data provider, we understand the value of high quality data: according to us a high-quality data includes specific terminologies to related to use case, all related accents and dialects, voice from all age groups, gender ratios depend demographic distribution, high quality transcription with all necessary details like time stamp, speaker IDs, labeling of parts other than speech, etc.
Transcription and Annotation
Once the audio data is collected, it needs to be transcribed into text format or we need to Annotate the transcriptions with timestamps and word-level alignments to create the ground truth for training. This step is crucial for supervised learning-based ASR models.
To make the transcription effective and more informative, in our case we can perform speaker diarization to separate individual speech segments. This helps the model better understand the context and intent of each speaker.
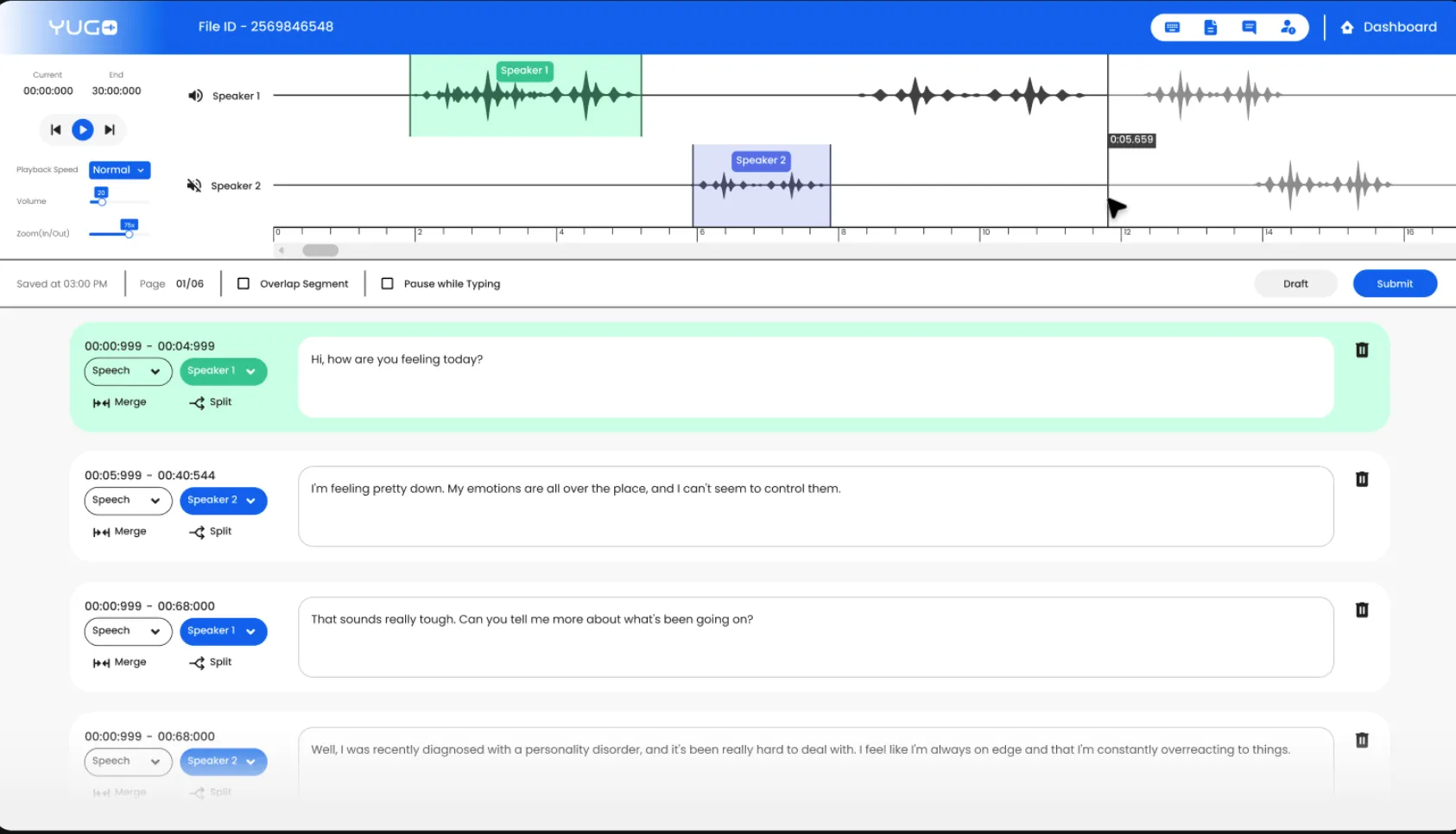 Annotate Banking Terminology
Annotate Banking Terminology
We can make our data more informative by Identifying and annotating specific banking-related terms and phrases that might be unique to the domain. This will help the ASR model recognize and understand these specialized terms during training.
Data Split
Once we collect the data, we have to split the dataset into training, validation, and testing sets. The training set is used to train the ASR model, the validation set helps in tuning hyperparameters, and the testing set is used to evaluate the final model's performance.
Once we are ready with datasets we can start the training of our model.
Model Training and Evaluation
In this step, the ASR model is trained using the prepared training data. The goal of model training is to teach the ASR model to recognize patterns and acoustic features in the speech data and learn to associate them with the corresponding text transcriptions.
After training the ASR model and tuning its hyperparameters, it is evaluated on a separate testing set that the model has never seen during training.The model's performance is assessed by comparing its predicted transcriptions to the ground truth transcriptions in the testing set.
We can use different common evaluation metrics for speech recognition models including Word Error Rate (WER), Character Error Rate (CER), and Sentence Error Rate (SER).
The evaluation helps to measure how accurately the ASR model can convert spoken language into written text in the banking domain.
Iterative Improvement:
The evaluation results provide valuable insights into the ASR model's strengths and weaknesses.If the model's performance is not satisfactory, the process goes through iterations of improvement.
Developers analyze the errors made by the model and identify patterns of mistakes. Based on the analysis, adjustments can be made to the training data preparation, hyperparameters, or model architecture to improve performance.
The training data might be augmented with more diverse samples or corrected for errors. Hyperparameter tuning may be refined, or even the architecture of the model can be modified.
The iterative improvement process continues until the desired level of accuracy and effectiveness in recognizing Bulgarian speech and banking-related terminology is achieved.
Conclusion: Training Data Preparation Process
In conclusion, preparing training data for ASR models is a complex and iterative process that requires careful consideration of domain-specific requirements, demographics, and language nuances. By following the steps outlined in this blog, ASR developers can build accurate and robust models that effectively understand and transcribe spoken language in the targeted domain, such as banking in Bulgarian, paving the way for more seamless and efficient interactions between humans and technology.






