There once was a machine-learning engineer by the name of Jack. Jack had a lofty goal: to build the most potent machine-learning model ever. He needed to gather a lot of data to train his model, which was a problem. And as we are all aware, data does not grow on trees.
Jack quickly realized that data collection was going to be his biggest challenge. He scoured the internet for data sets, hired a team of data collectors, and even considered selling his car to finance the project. But despite his best efforts, he was unable to gather enough data to appease his model's voracious appetite.
When all hope seemed lost, Jack discovered a secret that has the potential to change his data collection strategy. He came across an entirely new realm of efficient data collection techniques that he had not considered until now. He discovered how to make the most of already available data sources, streamline his data collection procedures, and even implement cunning techniques to produce more data without spending a dime.
And Jack was finally able to train his machine-learning model to perfection using these newly discovered techniques. The final outcome? The most potent machine learning model in the world, able to predict the future with unmatched accuracy.
Although the story may seem fictitious, it is a reality for many AI researchers and engineers. Therefore, if you're having trouble gathering data for your machine learning project like Jack, don't give up just yet. We're here to share the techniques that can help you realize your goals. So get ready to revolutionize your data collection game and stick it to the man (or woman, or non-binary person, or whoever's in charge of the data collection budget). The journey is about to start!
Let’s Face It!
Data collection for machine learning projects can be a real pain. It's time-consuming and tedious, and did we mention expensive? It's unfair that some machine learning projects never even begin because the cost of data collection can be so prohibitive.
Let's examine why data acquisition is so expensive, even though it shouldn't be. The cost of labor, infrastructure, quality control, pre-processing, data cleaning, and ethical considerations are just a few of the cost segments that are associated with data collection costs.
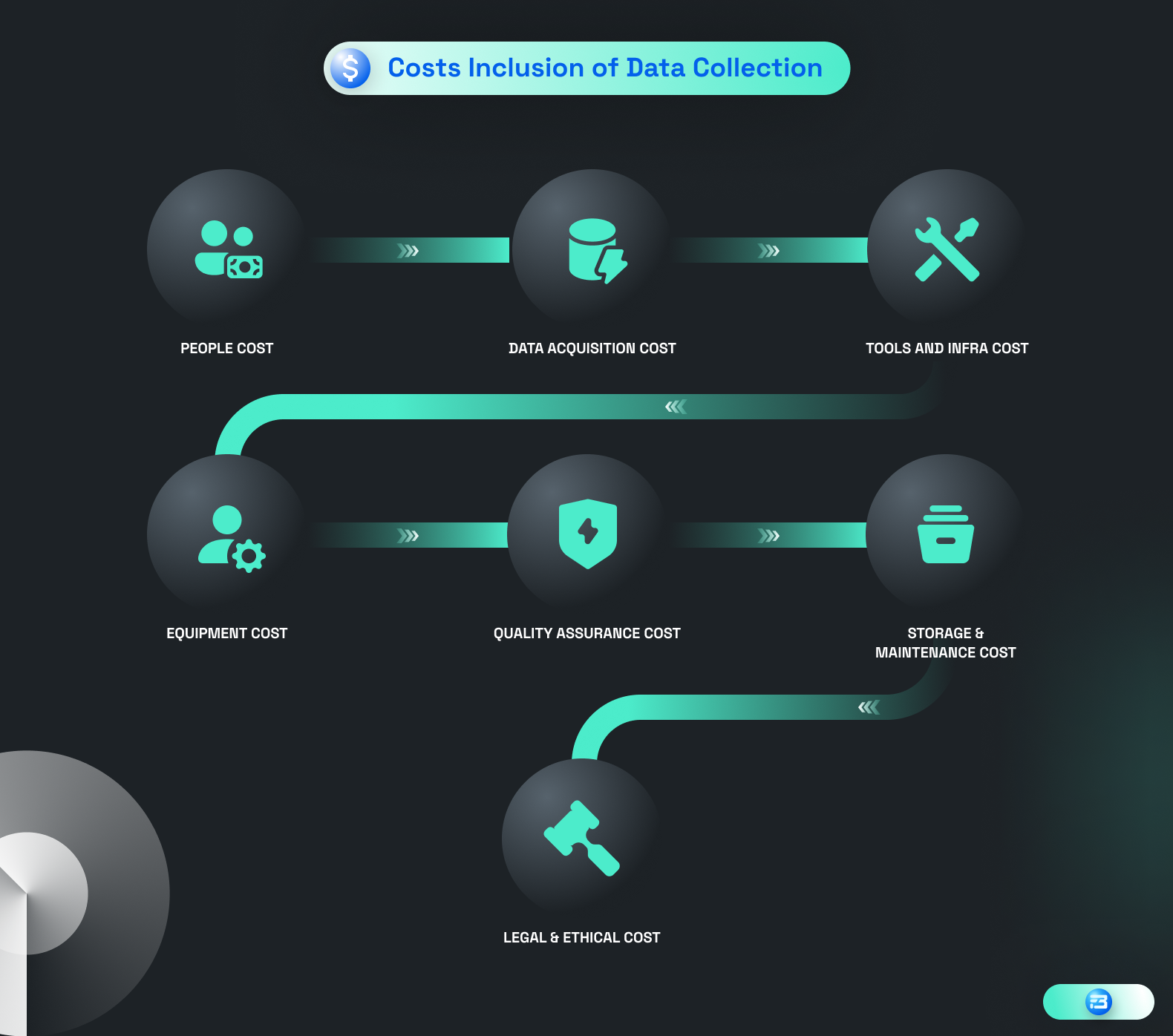 Now, it is definitely not a good idea to skip any of these segments, but the catch is that you can cut costs by making each data collection step as efficient as possible. We must ensure that our strategy includes more than just cost-cutting; we also need to ensure that the data we are gathering is of high quality!
Now, it is definitely not a good idea to skip any of these segments, but the catch is that you can cut costs by making each data collection step as efficient as possible. We must ensure that our strategy includes more than just cost-cutting; we also need to ensure that the data we are gathering is of high quality!
Let's start by examining how prioritizing quality can help with cost-effective dataset collection.
1) Prioritizing Quality over Quantity
 Any machine-learning model development process starts with gathering a training dataset. The process of gathering training data is not a one-time occurrence; rather, it can be repeated repeatedly throughout the entire period of developing a ground-breaking AI solution. While testing our model, if the efficiency of the model is not up to par in any scenario, then in order to train our model for that scenario, we need to collect new and more specific data in that case.
Any machine-learning model development process starts with gathering a training dataset. The process of gathering training data is not a one-time occurrence; rather, it can be repeated repeatedly throughout the entire period of developing a ground-breaking AI solution. While testing our model, if the efficiency of the model is not up to par in any scenario, then in order to train our model for that scenario, we need to collect new and more specific data in that case.
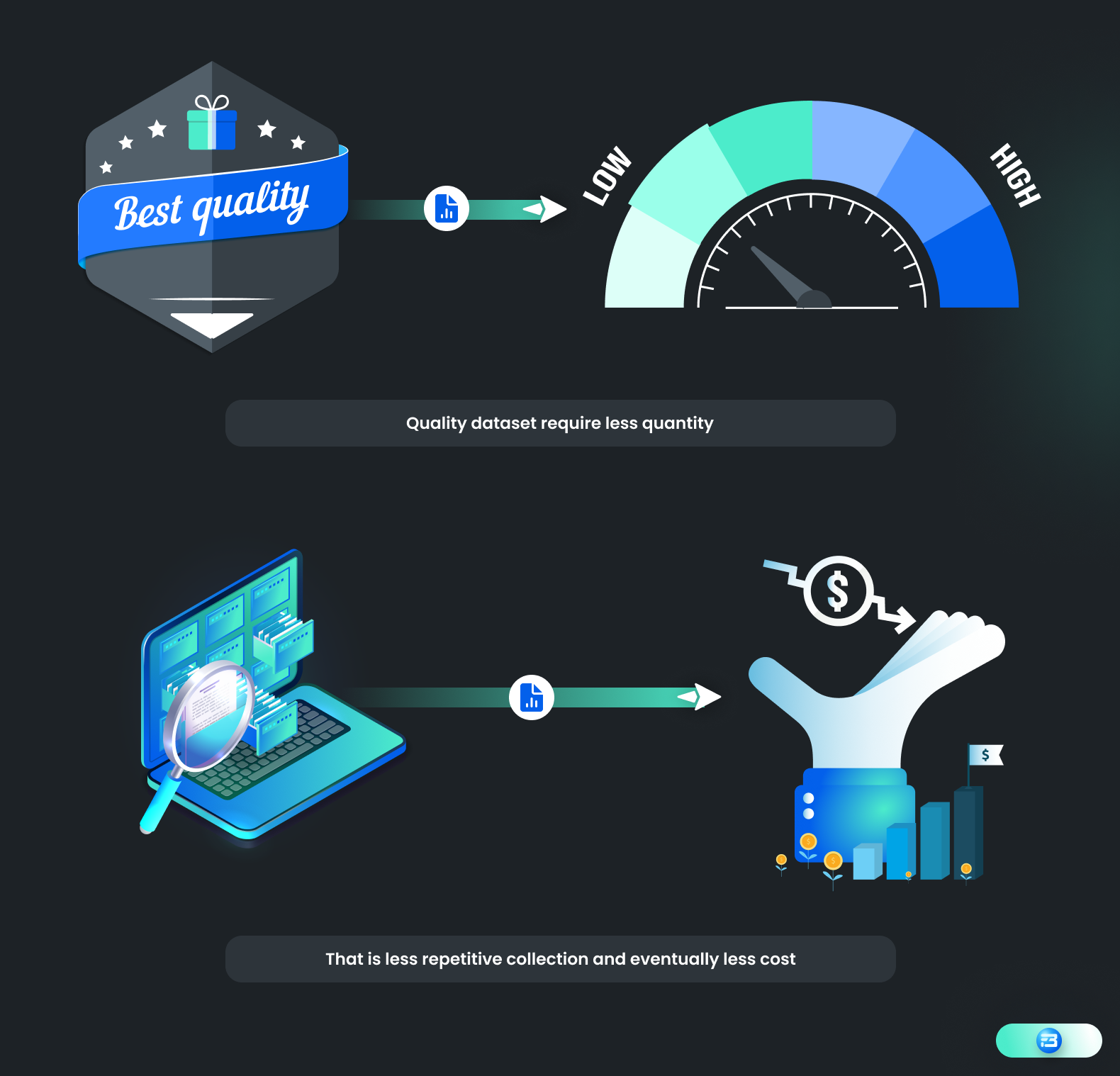
In order to lower the cost of data collection, our strategy should be to reduce this repetitive collection of new datasets. Now, the maxim "the more, the better" cannot apply to the collection of training datasets without paying attention to the dataset's quality. Also, it is obvious that the size of the dataset has a direct impact on the total cost of training data collection.
It can be expensive and time-consuming to gather a lot of training data, especially if the data needs to be labeled or annotated. However, collecting high-quality data, even if it's a smaller dataset, can actually help reduce overall costs in training data collection.
First off, by gathering high-quality data, we can avoid gathering redundant or irrelevant data that might not improve the performance of the machine learning model. As a result, it is less expensive to gather, store, and manage massive amounts of data.
Secondly, high-quality data can help reduce the time and cost associated with data cleaning and preprocessing. Cleaning and preparing the data for use in the machine learning model is easier when it is reliable and consistent.
Thirdly, a quality dataset can improve the performance of machine learning models, which in turn lessens the requirement for additional training data. As a result, there will be no need to collect extra data to make up for the model's shortcomings, which can help lower the overall cost of data collection.
In an ideal case, we must be clear about what we are expecting in terms of quality with any data collection process, and then finding the optimum balance between quality and quantity will significantly reduce the overall cost.
2) Leverage Human-in-the-Loop
 People are what make data collection possible. Depending on the use case, complexity, and volume, we have to onboard people from various places to gather the data. This is where most of the money goes when collecting data.
People are what make data collection possible. Depending on the use case, complexity, and volume, we have to onboard people from various places to gather the data. This is where most of the money goes when collecting data.
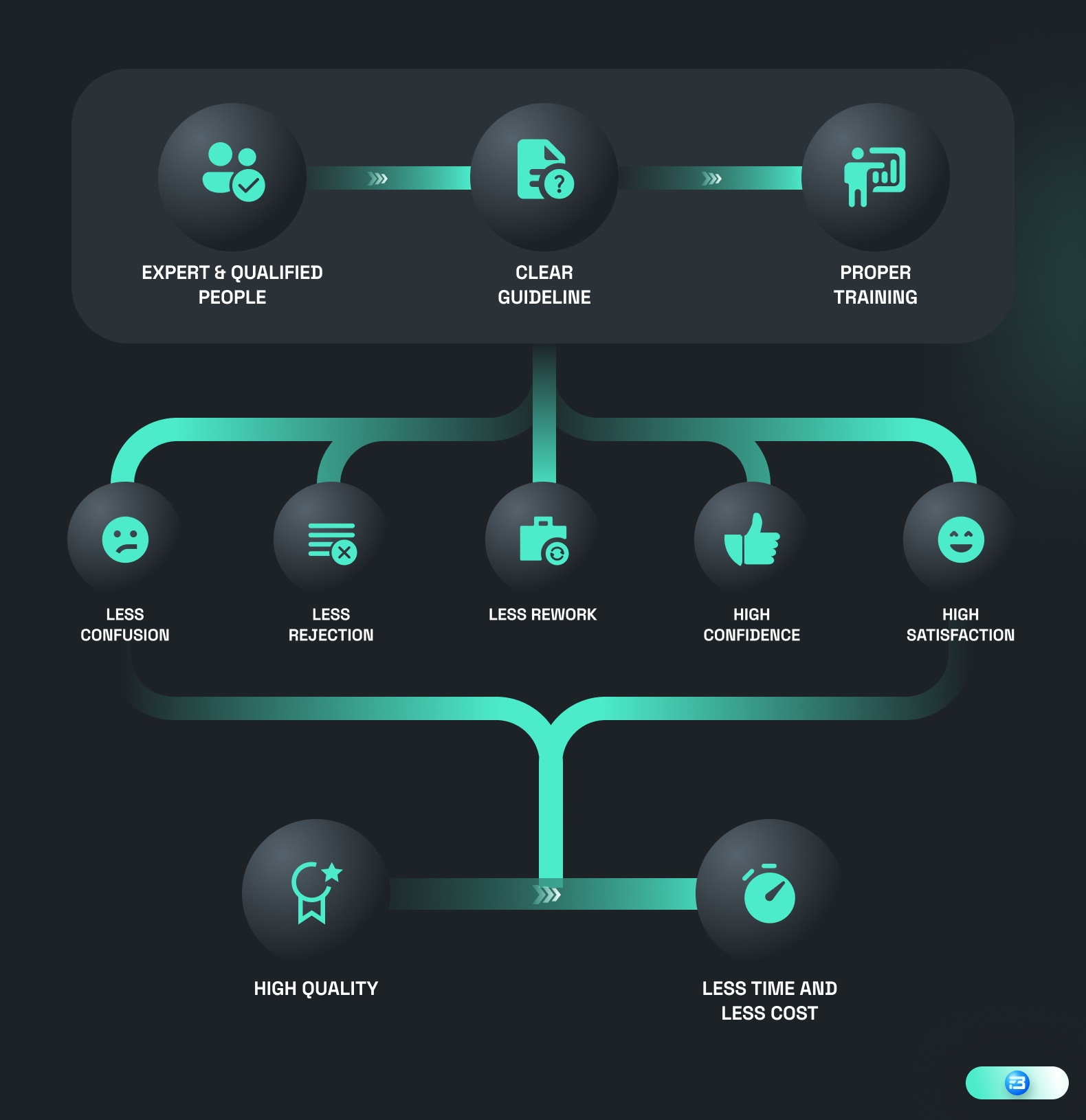
Recruiting qualified and knowledgeable crowds in accordance with the task at hand is the first step when dealing with the crowd in order to acquire a high-quality dataset. If you want German conversational speech data, then you must focus on onboarding native German people who already have experience working on similar projects. Simply because they have experience, they can easily comprehend your requirements and can help you more when it comes to gathering high-quality datasets.
Aside from that, all dataset requirements are distinctive in some way, and some dataset requirements can be particularly complicated. In these situations, it is strongly advised to spend some time developing appropriate guidelines and training materials in order to save money and time. It can be beneficial to have instructions and training materials in the native language.
If the guideline is clear from the start, then training people on it can be easy and can boost confidence in data providers. This also reduces the continuous back and forth in case of confusion over guidelines, which eventually saves more time and money.
Setting clear expectations can improve contributors' job satisfaction and lower their likelihood of giving it up. That reduces the cost and time associated with finding and onboarding new people.
An ideal guideline must have clear acceptance and rejection criteria for participants, which gives them a clear understanding of what to do and what not! This remarkably aids in lowering rejection and rework, which ultimately saves time and money.
Bonus tip
In case the use case you are working on is very novel and we are not sure about the guidelines, it is advisable to run a small-scale pilot project with whatever guidelines you have. Gather a minimum volume of data and test your model on it. Based on the process, experience, and results, rectify and finalize the need again and construct a clear guideline in that case.
Therefore, it is now obvious that any data collection effort's success is largely dependent on the accuracy and reliability of the training data collected, which in turn depends on the knowledge and experience of the crowd community.
As was already mentioned, dealing with a crowd-based community entails a variety of expertise-driven tasks. You can also collaborate with FutureBeeAI to lower costs overall by taking advantage of their global network of more than 10,000 crowd members and their time-driven SOPs, which will make it much easier for you to collect your ideal dataset.

3) Adopt Transfer Learning
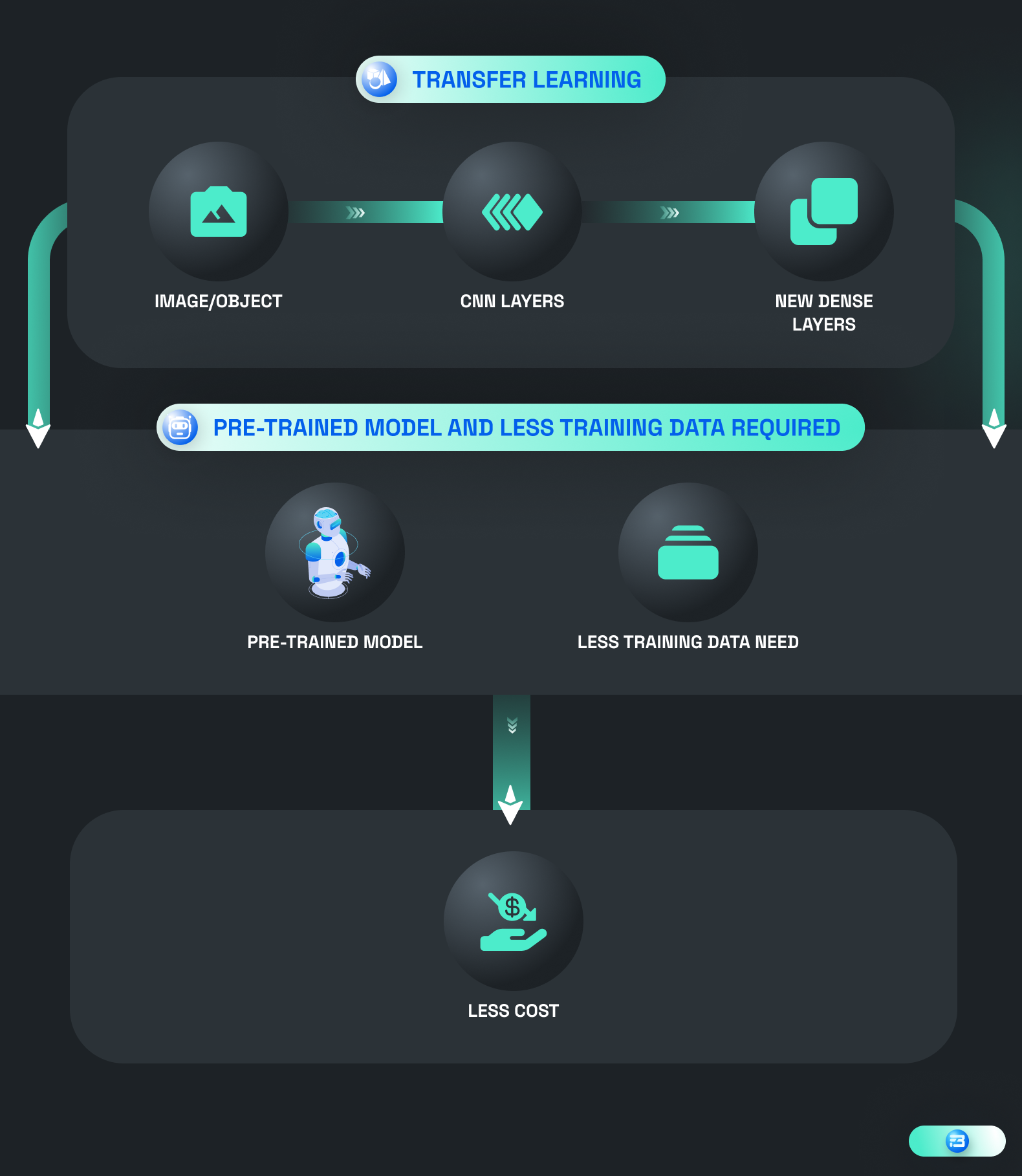 A pre-trained model is reused for a new task with less training data using the machine learning technique known as transfer learning. Transfer learning can lower the cost of gathering training datasets by lowering the quantity of new data that needs to be gathered and labeled.
A pre-trained model is reused for a new task with less training data using the machine learning technique known as transfer learning. Transfer learning can lower the cost of gathering training datasets by lowering the quantity of new data that needs to be gathered and labeled.
To train a model from scratch in conventional machine learning models, a significant amount of labeled data is needed. But with transfer learning, programmers can begin with a model that has already been trained and has picked up general features from a sizable dataset. Developers can quickly and effectively train a model that excels at the new task by fine-tuning the previously trained model on a smaller, task-specific dataset.
Let's say a business is creating a machine-learning model to find objects in pictures. They can use a pre-trained model like ResNet or VGG, which has already learned general features from a large dataset of images, rather than collecting and labeling a large dataset of images from scratch. The pre-trained model can then be fine-tuned using a smaller dataset of images relevant to their use case, such as pictures of industrial or medical equipment. The business can significantly reduce the quantity of fresh data that must be gathered and labelled while still creating a top-notch machine-learning model by utilising transfer learning.
Leveraging existing datasets is another way that transfer learning can assist in lowering the cost of training data collection. For instance, a developer can use the dataset from an earlier project as a starting point for a new machine learning project they are working on that is in a related field.
In conclusion, transfer learning is an effective method for cutting the expense of obtaining training data in machine learning. Developers can drastically reduce the amount of fresh data that must be gathered and labeled while still producing high-quality machine-learning models that excel at novel tasks by utilizing pre-trained models and existing datasets.
Making the decision to implement transfer learning can be difficult and crucial because there are numerous restrictions, such as
☑Fine-tuning might not be beneficial if a pre-trained model has already been created for the task that is not your primary concern.
☑Overfitting could occur if the model was developed using a sparse or unrelated dataset that is relevant to your task.
☑Fine-tuning can be expensive computationally if the pre-trained model is very large and requires a lot of computational resources.
4) Explore Readymade Dataset
 When working with large datasets, starting from scratch on a new dataset can be a daunting task. In this situation, a pre-made, or off-the-shelf (OTS) dataset might be a wise choice.
When working with large datasets, starting from scratch on a new dataset can be a daunting task. In this situation, a pre-made, or off-the-shelf (OTS) dataset might be a wise choice.
Finding an open-source training dataset that meets your needs can help you save time and money. Even though finding a perfectly structured dataset that meets your requirements in open source is extremely rare, there is no guarantee that it will be diverse and representative enough to support the development of reliable AI solutions.
Another option to acquire off-the-shelf datasets is through commercial licensing from organizations like FutureBeeAI. We already have more than 2,000 training datasets, including speech, image, video, and text datasets. There is a good chance that we have already created the dataset you need.

This pre-made dataset not only reduces collection time but also frees you from the hassle of managing crowds and aids in the scaling of your AI solution. Choosing an OTS dataset can make it very simple to adhere to compliances because the company has already taken all necessary ethical precautions. Finding the right partner and purchasing the appropriate off-the-shelf dataset can be a very economical solution.
 From our discussion up to this point, it is clear that the only opportunity to lower the cost of data collection is to find the most effective means of carrying out each of these minor yet important tasks. In this situation, using cutting-edge tools can be extremely helpful.
From our discussion up to this point, it is clear that the only opportunity to lower the cost of data collection is to find the most effective means of carrying out each of these minor yet important tasks. In this situation, using cutting-edge tools can be extremely helpful.
The cost of data preparation is another element on which we should concentrate. For the datasets to be ready for deployment after collection, proper metadata and ground truths are required. Now, manually generating this metadata can be a time-consuming and highly error-prone task. You can automate the creation of metadata and speed up the collection of structured datasets by using data collection tools.
In addition, collecting data without the proper tools only results in longer collection times, higher costs, and frustrated data collectors. Using data collection tools can greatly speed up the procedure and cut down on the total amount of time. This facilitates the participant's entire data collection task and can lower the overall budget!
You can read our blog post on "The Easiest and Quickest Way to Collect Custom Speech Dataset" for a better understanding of how incorporating the Yugo application can help with data collection in half the time and cost.
6) Data Augmentation
 The process of "data augmentation" involves applying different transformations to existing data in order to produce new training data. By enabling developers to produce more data from a smaller dataset, this technique can aid in lowering the overall cost of data collection for machine learning.
The process of "data augmentation" involves applying different transformations to existing data in order to produce new training data. By enabling developers to produce more data from a smaller dataset, this technique can aid in lowering the overall cost of data collection for machine learning.
Consider the case where you have gathered speech data for your ASR model. You can use data augmentation to expand your training dataset's overall size by:
Noise Injection: Adding different types of noises, like white noise, pink noise, babble noise, etc.
Environment Simulations: Different room environments can be simulated by adding room acoustics to the speech signal.
Pitch Shifting: Changing the pitch of the speech signal by increasing or decreasing the frequency of the signal.
Speed Perturbation: Changing the speed of the speech signal by increasing or decreasing the speed of the audio signal
Such transformations allow us to expand the dataset's size and add more data for a machine learning model's training. Here, there is also a cost savings because we can transfer the original labeling. In addition to saving money and time, it lessens the need for additional data and enhances the model's performance with the available dataset.
Data augmentation is a potent tool but also a complicated one. If not done properly, there are a lot of consequences. A dataset with many similar data points could result from its aggressive adoption, which could overfit models trained on the dataset. In a nutshell, it is a task that relies on expertise and should be approached with caution.
7) Ethical & Legal Consideration
 In the field of machine learning, the legal considerations surrounding training datasets are of critical importance. Developing and deploying machine learning models based on improperly sourced, biased, or discriminatory training datasets can have serious legal, ethical, and reputational consequences.
In the field of machine learning, the legal considerations surrounding training datasets are of critical importance. Developing and deploying machine learning models based on improperly sourced, biased, or discriminatory training datasets can have serious legal, ethical, and reputational consequences.
Several data privacy laws, including the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), govern the gathering and use of personal data. These regulations provide precise instructions for gathering, handling, and storing personal data. There may be penalties and legal repercussions if these rules are disregarded.
It is essential to abide by intellectual property laws when working with proprietary and copyrighted data; failing to do so could result in legal action. Such legal disputes between generative AI companies and artists have recently come to light.
Furthermore, it is crucial to compile a dataset that is unbiased, fair to all, and representative of the population. Legal action and reputational damage may result if the model is prejudicial or discriminatory toward any particular group.
Before collecting any personal data, it is advisable to review all the compliance requirements you must adhere to. In an ideal collection, make sure the data contributor is aware of the type of data he or she is sharing and what potential uses there are for it. Data providers must be aware of worst-case consequences as well. To prevent any further issues, make sure your data collection procedure is consensual and includes obtaining written consent from each data provider. Remember, loss avoided is money saved!
You might find this to be overwhelming, but we're here to help. By collaborating with FutureBeeAI, you can eliminate all the stress associated with data collection, crowd management, enabling cutting-edge tools, and taking all ethical and legal considerations into account.
Please feel free to contact our data expert to scale these strategies, regardless of where you are in the training data acquisition process.






