Word Error Rate
ASR
Breaking Down Word Error Rate: An ASR Accuracy Optimization
The word error rate measures how many word errors are present in ASR transcription compared to human transcription or ground truth. Explore WER deeply.
Word Error Rate
ASR
The word error rate measures how many word errors are present in ASR transcription compared to human transcription or ground truth. Explore WER deeply.

When it comes to automatic speech recognition, accuracy is key. However, achieving high accuracy rates is easier said than done. One of the most critical factors that can impact ASR accuracy is the Word Error Rate. Word Error Rate measures the percentage of words misrecognized by the ASR system compared to the original transcript. Understanding and optimizing WER is essential to achieving high ASR accuracy rates.
In this blog, we will break down WER and explore the factors that contribute to it.
In simple words, the word error rate measures how many word errors are present in ASR transcription compared to human transcription, or ground truth. The lower the word error rate, the higher the accuracy of an automatic recognition system.
The word error rate is a widely used metric to measure the accuracy of ASR systems. It is a relatively simple but actionable metric that allows us to compare ASR systems to one another and evaluate an individual ASR system’s accuracy over time.
So, if you are building an ASR model or are a user looking to use any ASR model for your operations, you must be aware of the WER for that ASR system.
Now that we understand what the word error rate is, let’s jump into how to calculate the word error rate.
Calculating the word error rate is simple and straightforward, involves comparing the speech transcription generated by an Automatic Speech Recognition system to a human-made transcript (Ground Truth) and then counting the number of errors. These errors include substitution, insertion, and deletion.
All these word errors are added up and divided by the total number of words in the ground truth.
 S stands for substitutions, taking care of replaced words. For example “What time is the meeting” is transcribed as “What time is the greeting.”
S stands for substitutions, taking care of replaced words. For example “What time is the meeting” is transcribed as “What time is the greeting.”
(Word Meeting transcribed as Greeting)
I stands for insertions, taking care of added word that is not said. For example “What time is the movie” is transcribed as “What time is the new Movie.”
(Word “New” transcribed that is not said)
D stands for Deletions, take care of the left word that is said. For example “I need to buy some fruits” is transcribed as “ I need to buy fruits.”
(Word “Some” not transcribed that is said)
N stands for the total number of words that are actually said.
Let’s calculate a WER with an example
“Ground truth: Today I am going to Silicon Valley to attain a meeting on how high-quality and diverse data can help ASR models to improve accuracy.” (N=25)
“ASR Model transcription: Today I am going to the Silicon Valley to attain a greeting on high-quality diverse data can help our ASR models to improve accurately.”
As you can see here
S= 2 (greeting, accurately)
I= 2 (the, our)
D= 2 (how, and)
Now, WER= (2+2+2)/25 = 0.24
This particular ASR system have WER of 24%.
Similarly, we can calculate the WER of different ASR systems and compare their accuracy. But before calculating WER for any speech recognition model we have to do normalization.
For calculating the most accurate word error rate, we must have to set guidelines around how to format Ground Truth and ASR transcripts before the comparison begins. This process is called normalization.
Normalization involves transforming the text into a predefined standard to remove variations in formatting, style, and other differences between ASR models. Each ASR model has its own way of transcribing words and numbers, and if we compare two models' outputs without normalization, the WER will incorrectly penalize one or both models for having stylistic differences, rather than for true errors. This can lead to inaccurate and unreliable WER scores that do not reflect the true performance of the ASR models.
Normalizing is consist of,
By normalizing, we can get the most accurate WER for any ASR model.
Ground truth before Normalization: “We wanna build uh, a great organization that can support Artificial Intelligence to grow and serve 7 billion people in a better way.”
After Normalization: “we want to build a great organization that can support artificial intelligence to grow and serve seven billion people in a better way."
Now you can compare this ground truth with ASR model transcripts to get a better view of their accuracy.
The word error rate is an important measure of any ASR accuracy and we should know what are the variable responsible for the word error rate. According to Microsoft a WER of 5-10% is considered to be good quality and is ready to use. A WER of 20% is acceptable, but you might want to consider additional training. A WER of 30% or more signals poor quality and requires customization and training.
ASR systems may find it difficult to recognize speech accurately in the presence of background noise. Noise can interfere with the sound quality of speech, leading to word errors because the machine will not be able to differentiate between noise and the human voice if not properly trained with real-life speech data.
There are many organizations working especially on removing background noise, and one well-established team is Krisp AI. If you are an ASR developer, I recommend you to connect with the Krisp AI team to get insights into how they are doing it.
Different speakers may have different accents, and ASR systems may struggle to recognize speech accurately if they are not trained in those accents.
In India, every 30-40 km accents of people speaking the same languages is different and this is one of the reasons India is the most diverse country in the world.
If your ASR model is not trained on diverse data then it may have substitutions, insertions, and deletions, making it a poor accuracy model.

ASR systems are trained on a specific set of words, and if a spoken word is not in the system's vocabulary, it may replace it with a similar-sounding word or produce an error. An ASR model cannot transcribe industry-specific jargon if it is not trained on data with industry-specific vocabulary.
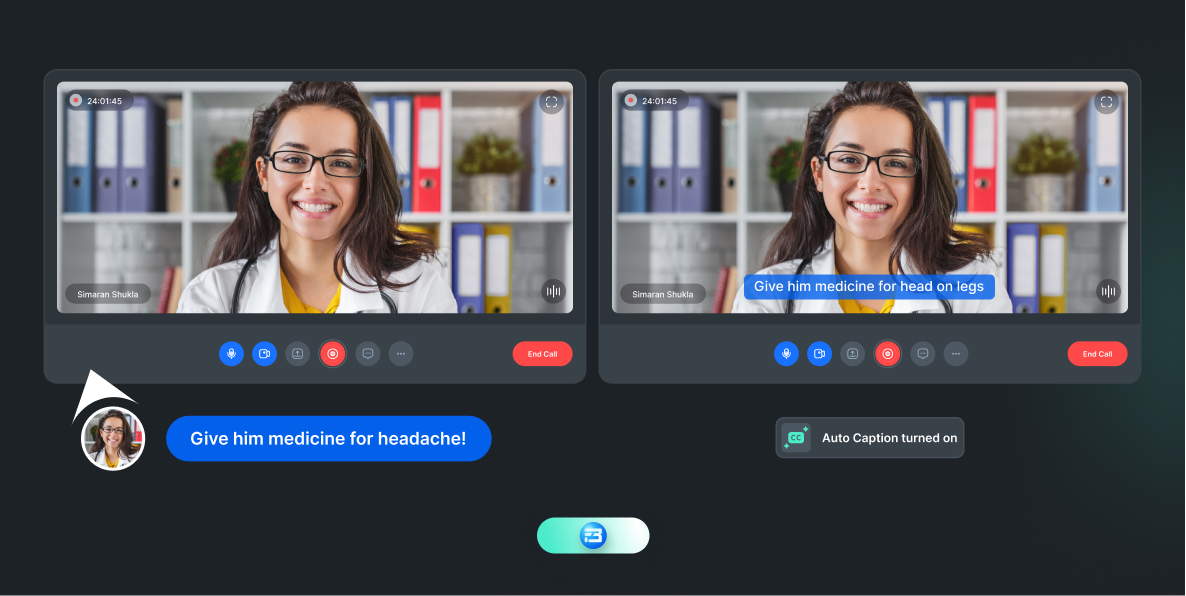
For instance, the doctor might say "The patient is suffering from aortic stenosis," but the ASR system might transcribe it as "The patient is suffering from aortic sclerosis," as it does not have the term "aortic stenosis" in its vocabulary. This can lead to incorrect medical diagnoses and treatment decisions based on inaccurate transcriptions.
 Speech Rate
Speech RateSpeaking too quickly or slowly can also lead to word errors. ASR systems may not be able to recognize all the words correctly if the speech rate is too fast or too slow.
 Speech Style
Speech StyleDifferent speaking styles, such as conversational speech or formal speech, can also affect the accuracy of ASR systems. Some styles may be more difficult for the system to recognize accurately.
Speech AI models are trained on different speech data to overcome this error like general conversations (Informal, general, between friends, family), contact center conversations (customer service calls, etc), etc.
Informal: Example sentence: "Um, I went to the store yesterday, and, you know, I saw this really cute dress, and, um, I decided to buy it."
Formal: The purpose of this presentation is to provide an overview of the current market trends and outline our strategy for the coming year."
Audio quality is one of the factors that can affect the word error rate in ASR systems. Poor audio quality can make it difficult to recognize speech accurately due to background noise, reverberation, microphone quality, or signal loss.
The presence of multiple speakers can impact the word error rate in speech recognition systems by making it difficult for the system to differentiate between speakers and recognize speech accurately. This can lead to overlapping speech, speaker identification issues, and speaker variation challenges.
 These are some variables responsible for word error rate in automatic speech recognition models. The good thing is we can overcome all these issues to an extent, so let’s dive into how we can reduce the word error rate.
These are some variables responsible for word error rate in automatic speech recognition models. The good thing is we can overcome all these issues to an extent, so let’s dive into how we can reduce the word error rate.
One can avoid the word error rate to some extent if enough research has been done before model training. If you are aware of the target audience and then you can get an idea about the different accents, vocabulary, jargon, and industry.
By doing this you are now in a situation to collect high-quality training data which can lead to a lower word error rate.
While thinking about the process, it may not sound very complex, but while working, users have to do lots of things. Through this process, recording a single prompt of 8–10 seconds was taking almost a minute.
At this stage, you should be deciding
All these things can be done in a better way with us at FutureBeeAI, We can help you to collect high-quality speech data in multiple languages and can also help you to transcribe with an expert team of transcribers.
After training the model with this high-quality training data you can measure the word error rate and decide what variable still has scope to overcome the WER. Although it is a very complex process to check which variable is responsible for WER and it requires careful analysis of the speech recognition system and its input data.
Identifying the specific cause of the Word Error Rate can be a complex process that requires careful analysis of the automatic speech recognition system and its input training data. Here are some general steps you can follow to help determine the main cause of word error rate:
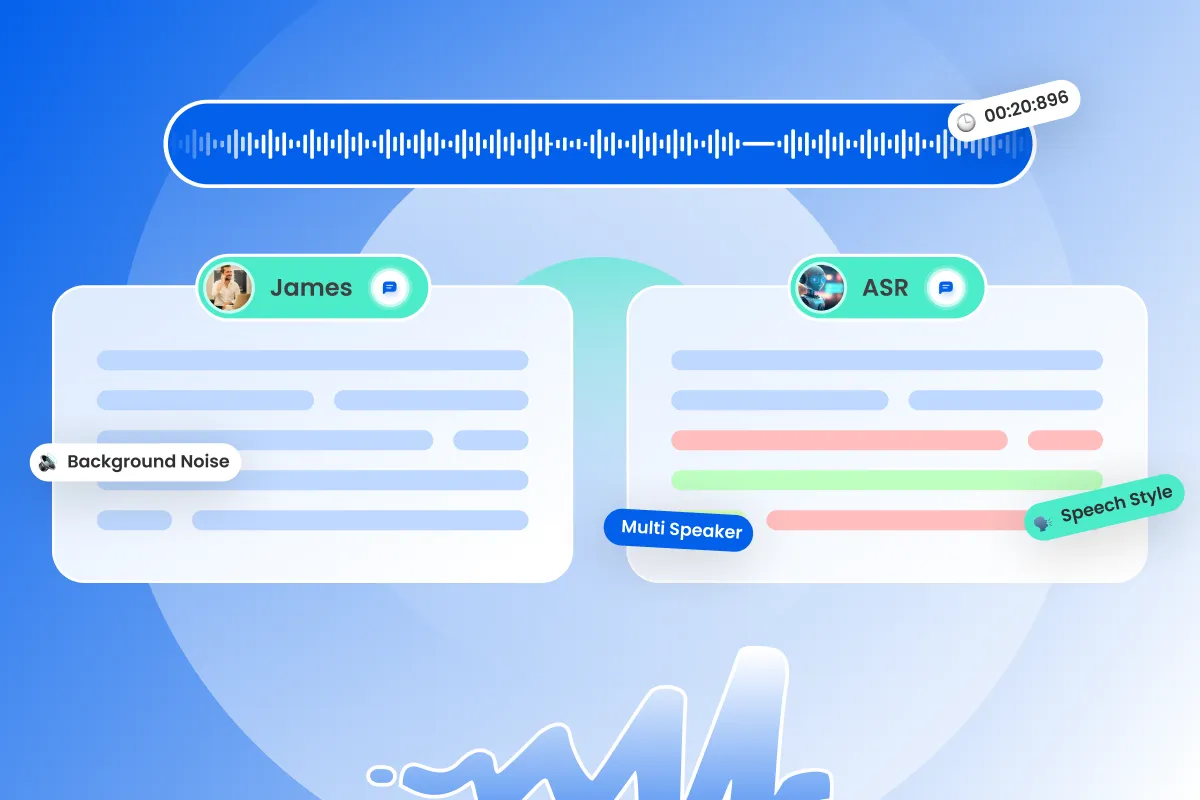
Look at the types of errors that are occurring in the system-generated transcriptions. For example, are there frequent substitutions of one word for another, or are there omissions or insertions of words? This can give you clues about which component of the system might be responsible for the errors.
Compare the system-generated transcriptions with a human-generated (ground truth) transcription of the same audio. This can help you identify errors that are specific to the speech recognition system, as opposed to errors in the input data.
Examine the settings and configuration of the speech recognition system, such as the language model, acoustic model, and post-processing techniques. Look for any settings that might be contributing to errors in the transcription.
Consider the characteristics of the input data, such as the quality of the audio, the speaking style of the speaker, and the vocabulary used. Look for any patterns or outliers that might be contributing to errors in the transcription.
Once you have identified the cause, you can take steps to address it, such as fine-tuning the language or acoustic models, adjusting the system settings, or improving the quality of training data.
Useful links:
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!


-data-collection/thumbnails/card-thumbnail/top-resources-to-gather-speech-data-for-speech-recognition-model-building.webp)

