Transcription
Transcription:The Key to improving Automatic Speech Recognition
Quality transcription is an essential part of any robust and unbiased speech recognition model. Explore the importance of human-in-the-loop for transcription
Transcription
Quality transcription is an essential part of any robust and unbiased speech recognition model. Explore the importance of human-in-the-loop for transcription

Automatic Speech Recognition (ASR) has become an integral part of our daily lives, from virtual assistants like Siri and Alexa to voice-controlled devices like smart speakers and smartphones. We rely on automatic speech-to-text solutions so much that we use them to transcribe lectures and corporate team meetings!
While using these AI-enabled ASR applications in our daily lives, we must have realized that they don’t perform accurately all the time. Many times, virtual assistants are unable to understand us when we ask for something unique or when we give them a command in a noisy environment. Lots of times, automatic caption generators or automatic speech-to-text applications don’t perform to their fullest with different languages, accents, and background noises.
Before we dive deep into what causes these malfunctions in any speech recognition model, let us quickly figure out the basics of training an ASR model.
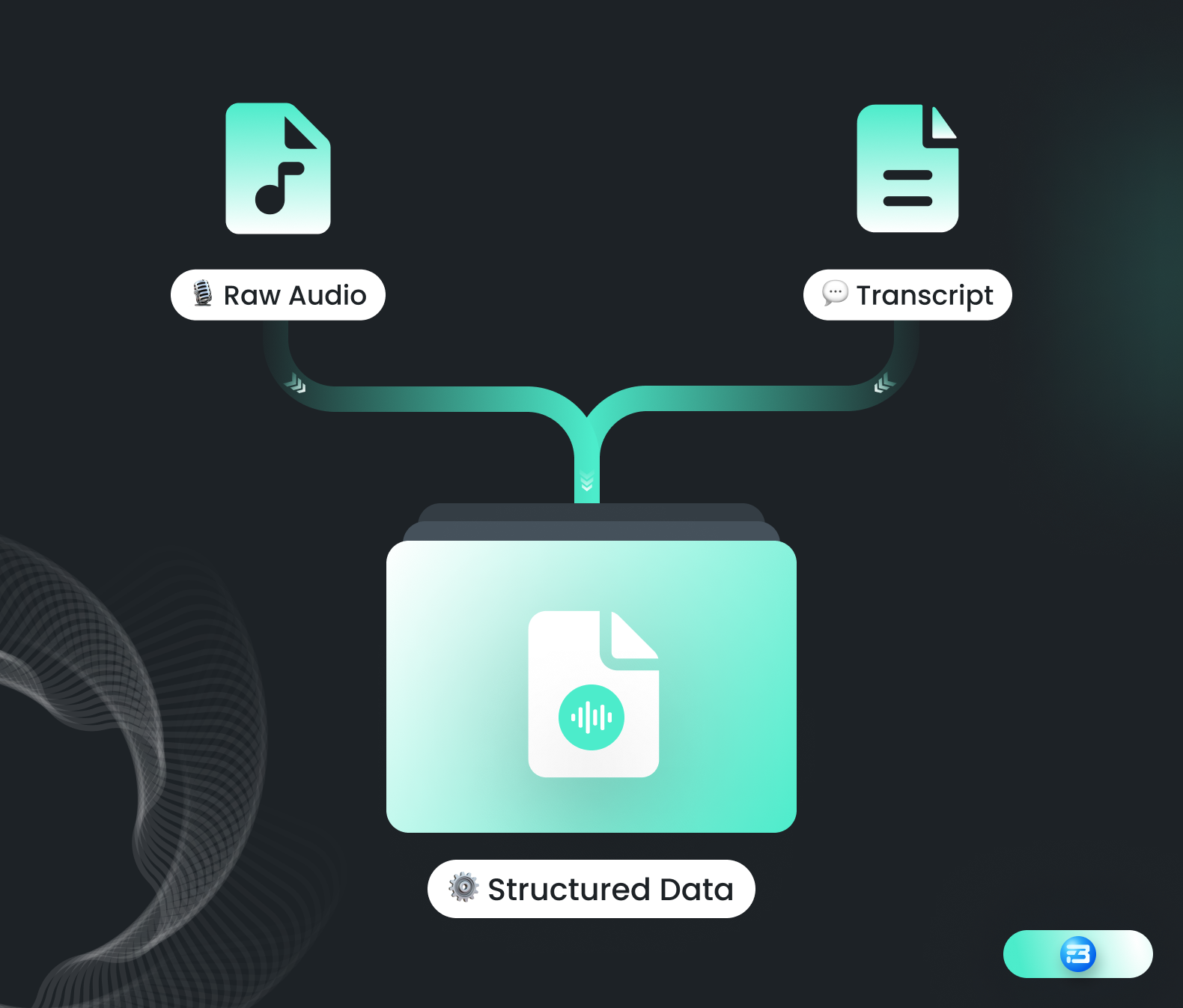
The accuracy of any AI model depends on how extensively it has been trained to accommodate diverse possibilities. It is often said that AI systems, including Automatic Speech Recognition (ASR) models, can only see or understand the world as it is represented in their training data. So acquiring a quality training dataset is one of the most crucial parts of training any automatic speech recognition model! A training dataset for a speech recognition model consists of raw audio/speech data and the corresponding transcript.
In our previous blog, "Revolutionizing Communication with Automatic Speech Recognition: A Guide to ASR and Speech Datasets Types," we stated that depending on the use case of the speech recognition model, we need different types of speech datasets! What is equally more important for these speech data to make it ready to deploy is creating a transcript of that particular audio file.
During the training process, the model is presented with a large dataset of audio recordings and their corresponding transcripts. The model then uses this dataset to learn the relationship between the sounds in the audio and the words in the transcript. The more data the model is trained on, the better it will be able to generalize to new audio recordings.
Transcriptions can also be used in the training of Automatic Speech Recognition (ASR) systems to improve their accuracy. This process is called "transcription-based training," and it uses a large dataset of transcribed speech to train the model. The transcriptions serve as "ground truth," or the correct version of the speech, against which the model can compare its own transcriptions. By repeatedly comparing its own transcriptions to the human generated accurate transcriptions, the model can learn to recognize patterns in speech and improve its accuracy over time.
After the training process, the ASR system can be used to transcribe new audio recordings, and the results can be analyzed to evaluate the model's performance. If the model's transcriptions are not accurate enough, it may be necessary to retrain the model with additional data or to adjust the model's parameters.
So the transcripts play a crucial role in training the ASR models by providing the ground truth for the model to learn from and a way to evaluate the model's performance on new audio recordings.
The quality of the dataset defines the accuracy of any AI models, and the same goes with speech recognition models as well. In the case of speech recognition models, the quality of the speech dataset and speech transcription can define how accurately the model will function in a particular scenario. As a result, speech transcription is a critical component of developing a robust speech recognition AI model.
There are different types of transcription out there. Let’s understand them briefly.
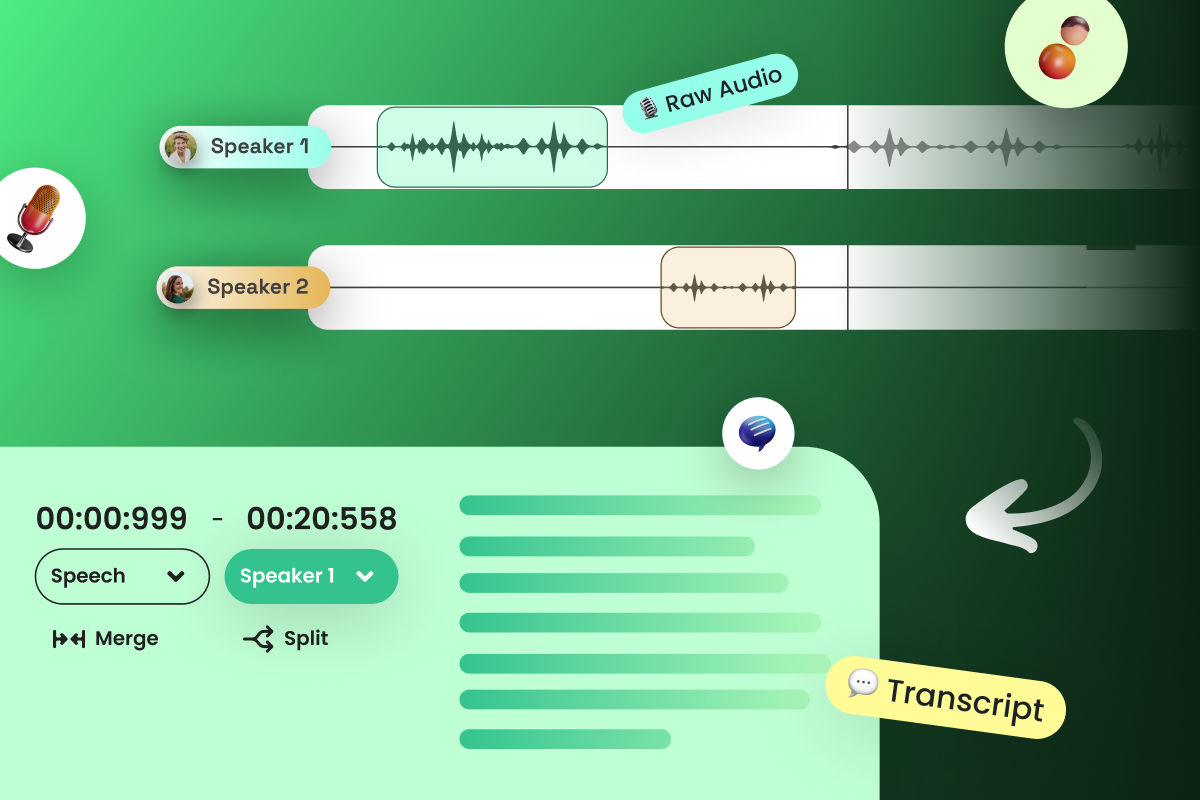
In simple words, we can define transcription as writing whatever is being spoken. In the context of Automatic Speech Recognition (ASR), transcription refers to the process of converting speech audio recordings into written text containing all the nuances of the audio like speaker identification, background noise labels, filler words, etc.
There are several types of transcription, each with its own unique characteristics and uses. Some of them, based on the method, are
Let’s explore each one of them.
Verbatim transcription is a type of transcription that includes everything that is said in the speech audio recording. This type of transcription is considered a word-for-word representation of the speech, capturing every detail of the spoken language.
Apart from being used in the training of speech recognition models, verbatim transcription is also used for legal or other official purposes, as it provides an accurate and detailed record of the speech.
The verbatim transcription also captures the different nuances of the language such as filler words, false starts, repetitions, and other nonverbal cues, which can help to improve the robustness of the model. This can be beneficial for ASR models that will be used in real-world scenarios where the speech is not always clear and may contain background noise or other disturbances.
Verbatim transcription is useful to train speech recognition models by linking each word sound with its corresponding text. In verbatim transcription we are focused on how the thing is being said along with what is being said.
Example of such Verbatim transcription can be:
[Speaker 1 ]: "Um, so, welcome everyone, today we are going to be talking about, um, the latest advancements in AI dataset providers, right? As many of you know, having high-quality data is, like, crucial for building accurate and reliable AI models. And one company that has been, like, making waves in the industry is FutureBeeAI, the AI dataset provider, you know?
[Speaker 2]: "Yeah, FutureBeeAI has been, uh, providing some of the most diverse and high-quality datasets available, you know? They, uh, offer datasets for a wide range of industries, including healthcare, finance, and transportation, right?
[Speaker 1 ]: "That's right. And one of the things that sets FutureBeeAI apart is their emphasis on diversity and inclusion. They ensure that their datasets are representative of a wide range of populations, which helps to, like, reduce bias in AI models, you know?
[Speaker 2]: "Exactly. And they also offer a wide range of annotation options, which helps to make the data more useful for different types of AI models, you know? And, uh, (background noise) I mean, they are, like, one of the best in the market. (sighs)
[Speaker 1 ]: "Yeah, that's true. And, um, (wrong start) I think it's important to note that, uh, their datasets are constantly updated and, like, they always strive to improve their offerings, you know? (repeats)
Intelligent transcription is a type of transcription that includes some level of editing to improve readability and clarity. This type of transcription is often used for business or legal documents, interviews, and other types of content where a high degree of accuracy and professionalism is required.
Verbal fillers, such as "um, " "ah, " and "you know, " and repetitions are removed from the transcript to make it more readable and professional.
In the context of ASR (Automatic Speech Recognition) model training, intelligent transcription can be useful in a number of use cases where a high degree of accuracy and readability is required. Some examples include business meetings, legal proceedings, interviews, medical dictation, media, and entertainment.
To train a model for a use case where what is being said is more important than how it is being said, we can use intelligent transcription to train such a model. These models can listen to your entire meeting, remove all unnecessary parts like filler words, repetitions, etc., and provide you with a clear transcript of the meeting.
An example of intelligent transcription is:
[Speaker 1] : "Welcome everyone, today we will discuss the latest advancements in AI dataset providers. As you know, having high-quality data is crucial for building accurate and reliable AI models. One company that has been making a significant impact in the industry is FutureBeeAI, the AI dataset provider.
[Speaker 2 ]: "Yes, FutureBeeAI provides some of the most diverse and high-quality datasets available. They offer datasets for various industries, including healthcare, finance, and transportation.
[Speaker 1]: "That's right. FutureBeeAI is known for their emphasis on diversity and inclusion in their datasets, which helps to reduce bias in AI models.
[Speaker 2 ]: "Exactly. They also offer a wide range of annotation options, which makes the data useful for different types of AI models. FutureBeeAI is one of the best in the market.
[Speaker 1]: "Yes, it's important to note that their datasets are regularly updated, and they always strive to improve their offerings.
A summarized transcription is a condensed version of an audio or video recording that captures the main points and key takeaways of the original content. It typically includes the most important information and leaves out less relevant details. The goal of a summarized transcription is to provide a quick and easy way to understand the main ideas of the original content.
The process of creating a summarized transcription typically involves listening to or watching the original recording, taking notes on the main points and then condensing the information into a shorter, more concise version. This is generally done by human transcribers.
A summarized transcription can be useful in training an automatic speech summarization model for a variety of situations, such as when the original recording is too long to review in its entirety, when the main ideas need to be quickly communicated to others, or when the original recording is in a language that is not understood by the reader. It can also be used for research, media, education, and many other use cases.
Example of such summarized transcription can be:
[Speaker 1 ]: "FutureBeeAI is an AI dataset provider that offers diverse and high-quality datasets for various industries, including healthcare, finance, and transportation. They focus on diversity and inclusion to reduce bias in AI models. They also offer a wide range of annotation options and regularly update their datasets to improve their offerings.
[Speaker 2]: "FutureBeeAI is known to be one of the best in the market, and their datasets are considered crucial for building accurate and reliable AI models."
An audio file is typically transcribed into the JSON (JavaScript Object Notation) file format. This JSON component may contain the following elements:
Each of these parameters can be crucial for the training purpose of the ASR model. It is worth noting that depending on the tool we use this list can be more or less extensive.
Similar to any other expertise-driven AI task, transcription also required trained people, state-of-the-art tools, and the most efficient process. There are many nuances in transcription that require human assistance to deal with. Let’s discuss some of the reasons why human assistance is required in transcribing audio files:
 Machine-generated Transcripts can Lead to Overfitting!
Machine-generated Transcripts can Lead to Overfitting!Automatic transcription can be helpful to some extent while creating a dataset for training a speech recognition model, but a layer of human review and editing is a must to make sure that the final transcription is of high quality! Existing speech-to-text models may not be fully trained to take up all the nuances like accent, language, and background noise in the audio file. So, the idea of using machine-generated transcription to train other speech-to-text models is similar to AI training AI, and it can’t produce good results! It can lead to the overfitting of models.
Apart from that, speech-to-text applications are not fully developed in all global languages. Except for a few dominant languages, speech recognition models perform with comparatively less accuracy in other regional languages. So when you are focusing on creating speech recognition models for any of these regional languages, "human-in-the-loop" is very essential for transcription.
Human transcribers are able to understand and transcribe the nuances of speech, such as regional accents, dialects, and colloquialisms, which can be difficult for software to accurately transcribe.
Our aim while building speech recognition models is to make sure that they work in all possible real-life circumstances. In real life, our model may incorporate multiple speakers, so we must train it for that. Human intelligence is crucial in identifying and labeling different speakers and their gender and age in the audio file. Human transcribers can also add context and meaning to the transcription, for example, by identifying speakers, transcribing nonverbal cues, and indicating when speakers are not audible.
To build a speech recognition model that can work flawlessly for bilingual speakers, we have to train a model with a speech dataset where users are frequently changing their language naturally. Human transcribers can tackle such bilingual audio in transcription and can label and transcribe both of these languages. This can help us create a quality dataset.
As discussed earlier, our speech model has to work in real life with various background noises as well, and to train the model for that, we need speech data with different kinds and levels of background noise. Human transcribers can label such noises and transcribe the speech part even in noisy environments.
Building a speech recognition model that can transcribe doctors voice notes has to train on such specific subject speech data. Transcribers with subject matter expertise can play a big role in creating quality speech datasets for such use cases.
Along with the transcribers that actually transcribe the speech data, one more segment of people is equally, if not more, important: project partners like FutureBeeAI! In the process of running your transcription project, there are so many steps where you need expert advice, and a project partner like FutureBeeAI can be your best possible support.

Defining transcription guidelines is crucial because it ensures consistency and accuracy in the transcribed text. It also helps to minimize errors and ambiguities in the transcription process.
Before starting a transcription project for automatic speech recognition (ASR), it is important to understand several key elements to ensure that the project is set up for success. Having a clear idea about the use case of the model, the target audience who will use the model, the target audience's age, gender, and demography, along with probable edge use cases, can help you clearly define the guideline.
Understanding the clear requirements can be helpful in proposing proper budgets and defining proper transcription guidelines. We can clarify all crucial aspects, like how to assist with filler words, what tags we should use, what to do when a speaker changes the language, etc. Clearly defining all these elements will improve the accuracy, reduce rejection, boost the confidence of transcribers, and, most importantly, reduce the overall time of the project.
Putting the right people on the transcription task is very essential. You can leverage people from all over the world in most languages by joining the FutureBeeAI community. FutureBeeAI can assist you with all the crucial tasks, like: developing clear job requirements; screening and testing candidates; providing training and support; monitoring and evaluating performance; encouraging feedback and collaboration; and leveraging technology.
We can assist clients with various quality checks by native language experts, depending on their needs. A quality check layer can significantly improve the overall quality score of the dataset. Onboarding native and trained transcribers for quality assurance is a very critical stage to make sure we are getting what we are expecting.
FutureBeeAI can assist you with overall project management to ensure that your AI feels no bottleneck due to data shortage. FutureBeeAI handles all crucial tasks of transcription project management so you can focus on building AI!
Feel free to get in touch with our dataset expert, no matter at what stage you are in your speech recognition model.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!