Physical AI
AI Data Quality
How to Ensure Physical AI Data Is Unbiased and Representative
Most Physical AI data teams think diversity means demographics. It doesn't. There are 5 dimensions of bias and most teams only address one.
Physical AI
AI Data Quality
Most Physical AI data teams think diversity means demographics. It doesn't. There are 5 dimensions of bias and most teams only address one.

The bias frameworks teams are using and why they're incomplete for Physical AI
When teams start thinking about bias in Physical AI, they typically reach for the same frameworks they developed for language models and computer vision. Who are the demonstrators? Is there demographic diversity? Are different genders, ages, and backgrounds represented? These are legitimate questions. They're also the wrong starting questions for Physical AI, not because they don't matter, but because they address one dimension of a five-dimensional problem.
The biased thinking that the AI industry developed over the past decade was shaped almost entirely by language data. In language models, bias is primarily about what is in the training corpus: whose language, whose perspectives, whose experiences appear and which are underrepresented or absent. Fixing language model bias means widening the set of voices and contexts the model learns from.
Physical AI is different in a specific way that this framework doesn't account for. The robot doesn't just need to understand a diverse range of perspectives, it needs to operate in a diverse range of physical conditions. And physical conditions have their own bias dimensions that are entirely separate from who was in the room during data collection. A system trained with two hundred demographically diverse demonstrators in a single well-lit lab still has a significant bias problem, it just isn't the kind of bias teams are usually checking for.
The failure mode this creates is predictable. Teams run demographic audits on their demonstration data, satisfy themselves that the diversity boxes are checked, and deploy a system that breaks the first time it encounters a worn floor surface, inconsistent lighting, or an object placement it never saw during training. The post-mortem almost never says "we should have had more diverse demonstrators." It says something like "the deployment environment was different from what we trained on." That observation is pointing directly at a condition coverage gap but it isn't being named as a bias problem, so teams tend to treat it as a one-off edge case rather than a systematic gap in how they thought about representativeness.
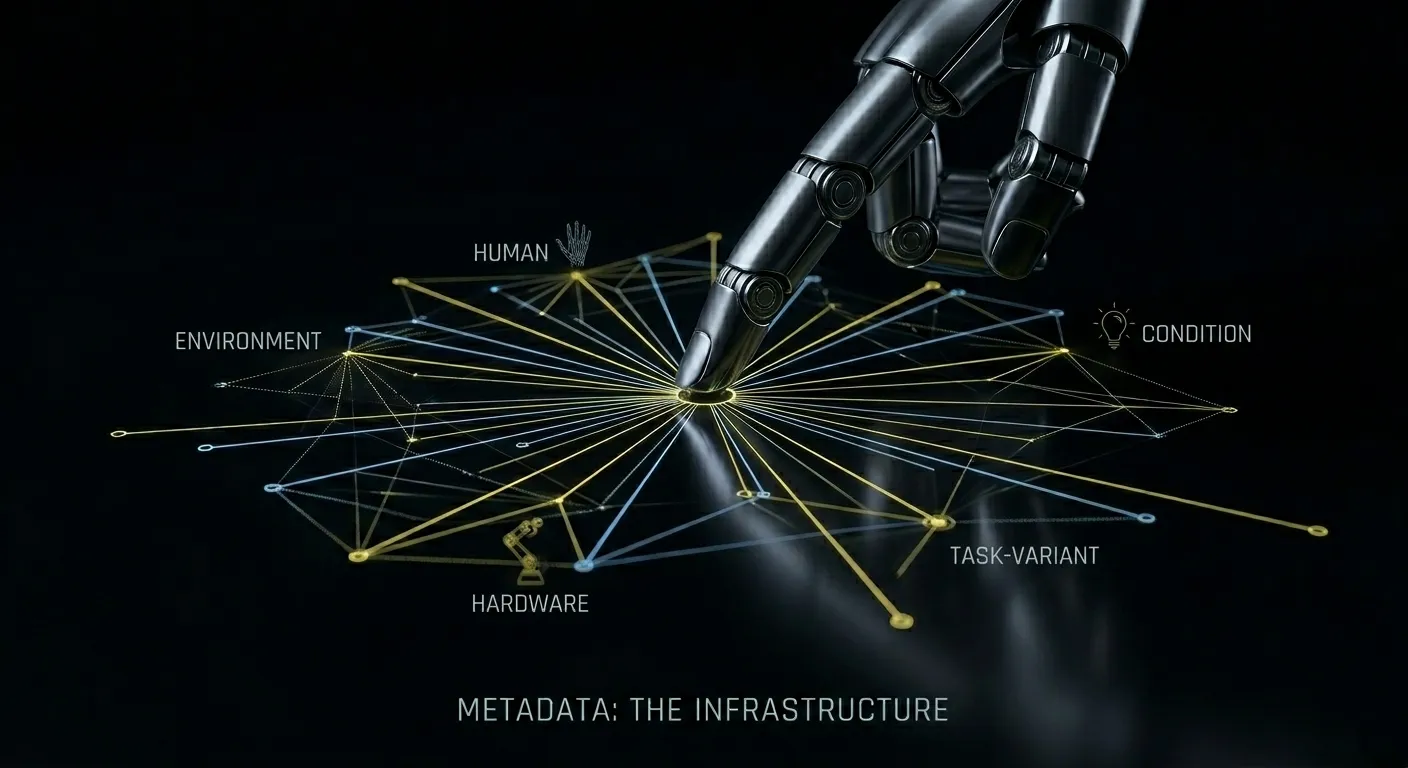
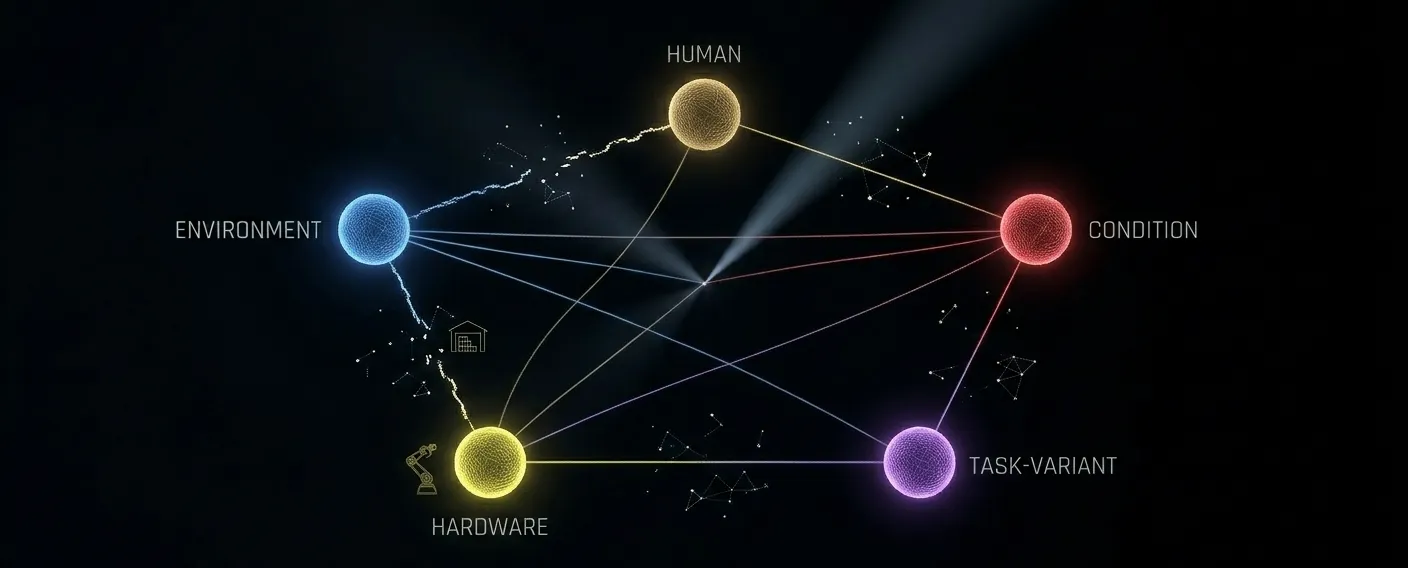
Physical AI systems require training data that reflects the full range of conditions they'll encounter in deployment. That range has five distinct dimensions and each one operates independently. A gap in any one of them can cause deployment failures that the other four won't compensate for.
Environmental bias is the most common and in some ways, the most invisible. It describes the mismatch between the environments where data was collected and the environments where the system will be deployed. Most Physical AI data collection happens in spaces that are convenient: a lab, a test facility, a dedicated studio space. These environments have controlled lighting, clean surfaces, predictable spatial layouts and minimal ambient interference. Real deployment environments are none of these things. A warehouse floor has scuff marks, inconsistent overhead lighting, boxes in unexpected positions and humidity variations. A home environment has rugs, narrow doorways and objects left on the floor by people who weren't thinking about the robot's needs. When the training data came exclusively from controlled environments, the system has learned to operate in a world that doesn't exist outside the lab.
Demonstrator-physical bias is subtler but matters significantly for manipulation tasks and any interaction that depends on the physical characteristics of the human body. Whose hands demonstrated the task? Whose reach envelope defined the approach trajectory? Whose grip strength was encoded as the baseline for how objects are picked up and placed? If the demonstration dataset skews toward one physical profile, tall workers, right-handed workers, workers in a particular age range then the system has learned patterns that may not transfer well to users or operators with different physical characteristics. This isn't about fairness in the abstract. It's about whether the system can actually complete tasks correctly when operated by the full range of people who will use it.
Hardware bias gets less attention than the others, but it's a real issue for teams deploying across multiple robot units or across hardware generations. Data collected on one specific robot with that robot's particular joint response characteristics, sensor noise profile and actuator timing produces a model that is subtly optimized for that robot's specific physical behavior. When that model runs on a different unit, even one from the same product family, small differences in hardware behavior can accumulate into meaningful performance gaps. Teams that test extensively on a single robot before deploying across a fleet sometimes discover that the fleet's overall performance is lower than the test unit's, and it's not obvious why. Hardware variance in the training data is one of the less-discussed causes.
Condition bias is perhaps the most impactful of the five dimensions for systems that will operate in dynamic, real-world environments. Training data collected under consistently ideal conditions like stable lighting, clean surfaces, objects in expected positions, no background interference. This teaches the model what the world looks like when everything is going well. Deployment is rare when everything is going well. Lighting changes throughout the day. Surfaces accumulate wear. Objects aren't where they're supposed to be. When the model has never encountered these states during training, it hasn't developed the robustness to handle them gracefully. FBAI's experience with in-car speech data shows the same principle. Audio recorded exclusively in quiet driving conditions produces ASR systems that fail reliably in city traffic, rain or when multiple passengers are speaking. The system isn't wrong; it just learned a world that only partly resembles where it was deployed.
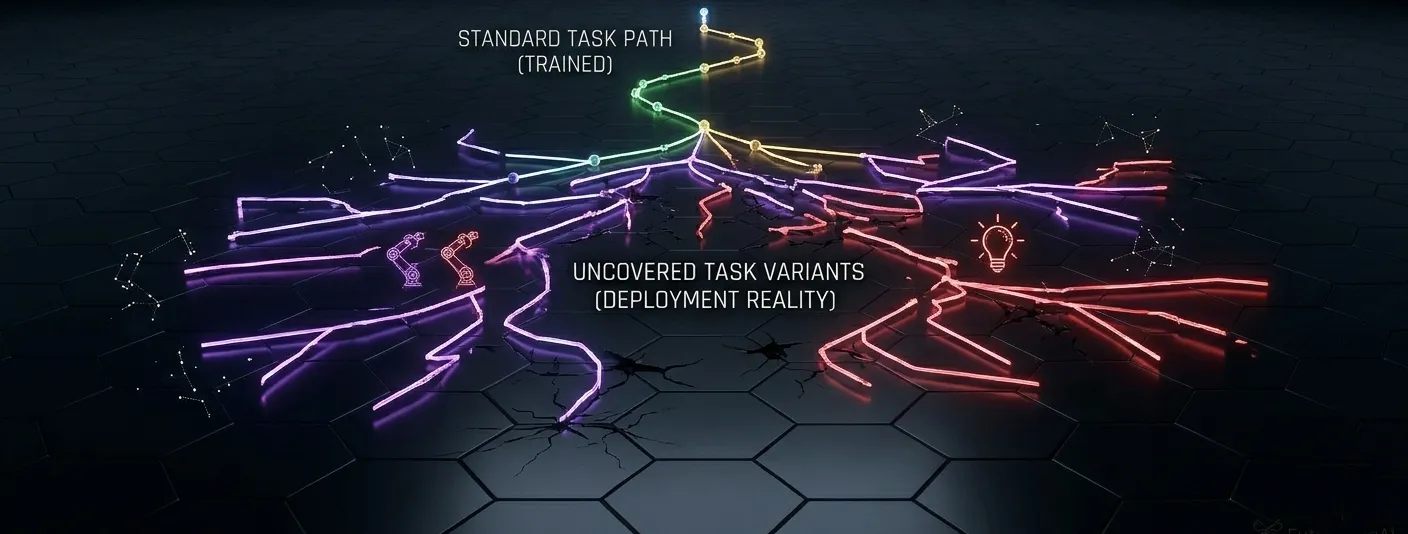
Task-variant bias is about the difference between the standard execution path and the full range of executions that real users produce. When data collection focuses on clean, successful demonstrations of the most common task sequence, it misses the recovery behaviors, the partial failures, the awkward approaches, the slower or faster executions that happen constantly in production. The model learns that tasks go smoothly. Users discover that when tasks don't go smoothly, the system doesn't know what to do.
Auditing for condition coverage gaps requires different tools than demographic audits. The core question isn't "who is in the data", it's "where and how was the data collected and what range of conditions does it represent?"
The coverage map approach is the practical starting point. Create a simple grid with the five dimensions as columns. For each dimension, document what you actually know about the range represented in your current data. Under Environmental, list the collection venues and their characteristics. Under Condition, note whether you have data from varying lighting, surface states, object placement variability, and ambient interference. Under Hardware, list which robot units or configurations contributed data. Under Demonstrator-physical, document what you know about the physical profiles of demonstrators in terms of the characteristics that matter for your specific task. Under Task-variant, note which execution patterns are represented and which aren't.
The gaps in this grid are your bias exposure. They don't all need to be filled before deployment, some gaps may be acceptable, given the actual deployment conditions but they need to be visible. The teams that get surprised by deployment failures are almost always the teams where this grid has never been built.
Metadata as the infrastructure for bias auditing is the structural prerequisite that most teams skip. The coverage map can only be built if the metadata exists. For Physical AI data to be auditable for condition coverage, each recording session needs to capture: the collection environment (type, dimensions, surface state, lighting conditions), demonstrator profile characteristics relevant to the task, hardware configuration (unit identifier, sensor array version), ambient condition state (lighting level, surface cleanliness, object placement regularity), and task variant type (standard execution versus recovery or edge case). Without this metadata, you can collect diverse data and have no way to verify that it's diverse in the dimensions that matter. The collection happened; the evidence didn't get captured.
Building this metadata schema before a collection project begins is far cheaper than trying to reconstruct it afterward. A project that completes 2,000 hours of demonstration data and then discovers the session metadata is incomplete has a problem that retrospective annotation can't fully solve.
Representative data for Physical AI covers the five dimensions adequately for the actual deployment context. The key word is adequately. There's no universal standard for how much environmental variation or how many task variants are required, because the right answer depends entirely on what the system will be asked to do and where.
What representative data is not: a large dataset collected in a single controlled environment, regardless of how many diverse demonstrators contributed to it. Demographic diversity and condition diversity are not the same thing and do not substitute for each other. A dataset with 500 demographically balanced demonstrators, all working in the same lab under the same conditions with the same hardware, is meaningfully biased toward lab conditions and that bias will express itself in deployment.
What representative data is not: a collection that optimizes for the most common case. The most common execution path is the easiest to collect and the easiest to validate. It's also not what breaks systems in production. Edge cases, failures, recovery behaviors, and variant conditions are harder to collect and harder to label consistently, which is exactly why they tend to be underrepresented. They're also the conditions that determine whether a system is genuinely robust or just good in the demo.
The practical framing that's useful in collection design: for each of the five dimensions, ask where you would expect deployment to take the system and work backward to what collection needs to cover. If the system will operate in warehouses, the collection needs warehouse-like conditions, different floor surfaces, variable lighting, and working clutter. If the system will be operated by people across a wide age range, the demonstration data needs to reflect the physical patterns of that range. If the system will run on multiple hardware units, the collection needs to include multiple units. The question is always: does our training data reflect the world the system will actually be deployed into or does it reflect the world we were able to conveniently collect in?
The fastest first step is extracting what metadata already exists. Most data collection systems capture some metadata automatically like timestamps, hardware identifiers, operator IDs. Start there. Map what you have against the five dimensions. Where you have coverage metadata, build the grid. Where you don't, flag those dimensions as blind spots.
A blind spot isn't necessarily a crisis. It means you don't know what your coverage is for that dimension which is different from knowing that your coverage is inadequate. Sometimes retrospective characterization is possible: if you know a project using a single lab environment, you can infer that environmental coverage is narrow. If you know demonstrators were recruited from a specific facility's staff, you can make reasonable inferences about physical profile characteristics. This kind of retrospective assessment, while imperfect, is better than proceeding without any model of what your coverage looks like.
The output of this first audit is a realistic picture of where the data is well-covered and where it's thin or unknown. That picture becomes the input to collection planning: what additional data needs to be gathered before the next deployment, and which dimension gaps are most likely to affect performance given the actual deployment context.
A Physical AI project that designs its data collection around the five coverage dimensions before the first recording session begins has a fundamentally different relationship with deployment risk than one that discovers gaps after deployment fails. The dimensions like environment type, physical conditions within environments, demonstrator profiles, hardware configurations and task variants are not a post-hoc audit framework. They're a design input. The coverage map built from them is what converts "we collected 2,000 hours" from a confidence signal into an actual quality signal.
The projects that work are the ones that were designed to work. That means knowing, before collection begins, which environments and conditions the system will need to navigate, which physical profiles will operate it, which hardware it will run on, and which task variants it will encounter. Collecting that range is harder than collecting in a single controlled venue. It is also the only way to build a system that doesn't break the first time it leaves the facility it was trained in.
At FutureBeeAI, coverage design is how we scope every Physical AI data collection we work on. In Physical AI collections we've worked on for manipulation and interaction tasks, the coverage gap that most consistently surfaced during deployment wasn't who was in the data, it was what conditions the data was collected under. Staging areas in controlled phases produce clean, structured data. Real deployment environments have worn surfaces, variable overhead lighting, objects out of position, and ambient noise that nobody specifically planned for. Adding deliberate condition variability to collection design explicitly recruiting recording sessions across surface states, lighting ranges and working clutter levels consistently closed the deployment gap that demographic diversity alone didn't address.
If you're designing a Physical AI data collection and want to build a coverage map for your specific deployment context, talk to the FutureBeeAI team.
Q. What is the difference between environmental bias and condition bias in Physical AI data?
A. Environmental bias describes the type of location where training data was collected, a lab versus a warehouse versus a home. Condition bias describes the physical state of that location during collection like lighting level, surface wear, object placement, ambient interference. They require different fixes: environmental bias is addressed by collecting in more types of locations; condition bias is addressed by collecting across the range of physical states within any location. A team can address environmental bias (adding warehouses to their collection venues) while still having significant condition bias (collecting in those warehouses only under ideal, freshly-cleaned conditions).
Q. Why doesn't demographic diversity among demonstrators solve the representativeness problem in Physical AI data?
A. Demographic diversity addresses one of the five condition coverage dimensions demonstrator-physical bias but leaves the other four untouched. A dataset with demographically balanced demonstrators can still be heavily biased toward the environments those demonstrators worked in, the hardware they worked with, the conditions that were present during collection, and the task execution paths they were asked to demonstrate. In Physical AI deployments, the failure modes that surface most often trace back to condition coverage gaps rather than demographic gaps. Both matter, but treating demographic diversity as sufficient for representativeness is the most common way Physical AI teams leave systematic bias unaddressed.
Q. How do you build a coverage map for Physical AI training data?
A. A coverage map is a five-column grid, one column per bias dimension (environmental, demonstrator-physical, hardware, condition, task-variant). For each dimension, document the actual range represented in the dataset: what environments were used, what demonstrator profiles were included, which hardware configurations contributed data, what condition states were captured, and which task execution variants are present. Gaps in the grid are the bias exposure. The coverage map doesn't require a dataset to be complete before it can be started, it can be built iteratively as data accumulates, and it becomes the input to collection planning when gaps need to be filled.
Q. What metadata should be captured during Physical AI data collection to enable bias auditing?
A. The minimum viable metadata set for condition coverage auditing: recording environment (space type, floor surface, spatial dimensions, clutter level), lighting state (level, source type, consistency), demonstrator profile (height bracket, dominant hand, age range, any physical characteristics relevant to the task), hardware configuration (robot unit ID, sensor array version, actuator firmware version), ambient conditions (background noise level, temperature if relevant, object placement regularity), and task variant type (standard execution, recovery from failure, edge case, slower/faster variant). Without this metadata per session, the dataset cannot be audited for the dimensions that matter most. Capturing it at collection time costs almost nothing. Reconstructing it retroactively, if possible at all, costs significantly more.
Q. Will adding more data without changing the collection design reduce Physical AI bias?
A. No. Adding volume does not address coverage gaps, it amplifies existing patterns. A dataset with 1,000 hours of lab-condition recordings and 500 additional hours of the same lab-condition recordings has the same environmental and condition bias as the original; it just has more of it. Bias reduction requires deliberate collection targeting the underrepresented dimensions, not more of what's already there. The coverage map makes this explicit: if environmental coverage shows 95% lab and 5% warehouse, adding 500 more lab-condition hours moves that ratio to 96/4, not toward balance. The design has to change, not just the volume.
Q. How does the consequence chain in Physical AI affect how training data bias expresses itself?
A. In Physical AI, perception, decision and action form a consequence chain, failures at perception propagate through decision into physical action. This means bias in the training data doesn't just reduce performance at the stage where it exists; it amplifies at each downstream stage. Condition bias in perception training produces uncertain perception outputs in degraded conditions. Those uncertain outputs trigger uncertain decisions. Those uncertain decisions execute as physical actions with real-world consequences. The physical consequence is what gets observed and reported but the root cause is a perception training gap three steps upstream. This is why bias in Physical AI training data is more consequential than bias in language AI training data: the failure mode isn't a bad recommendation, it's a physical outcome that can't be undone.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





