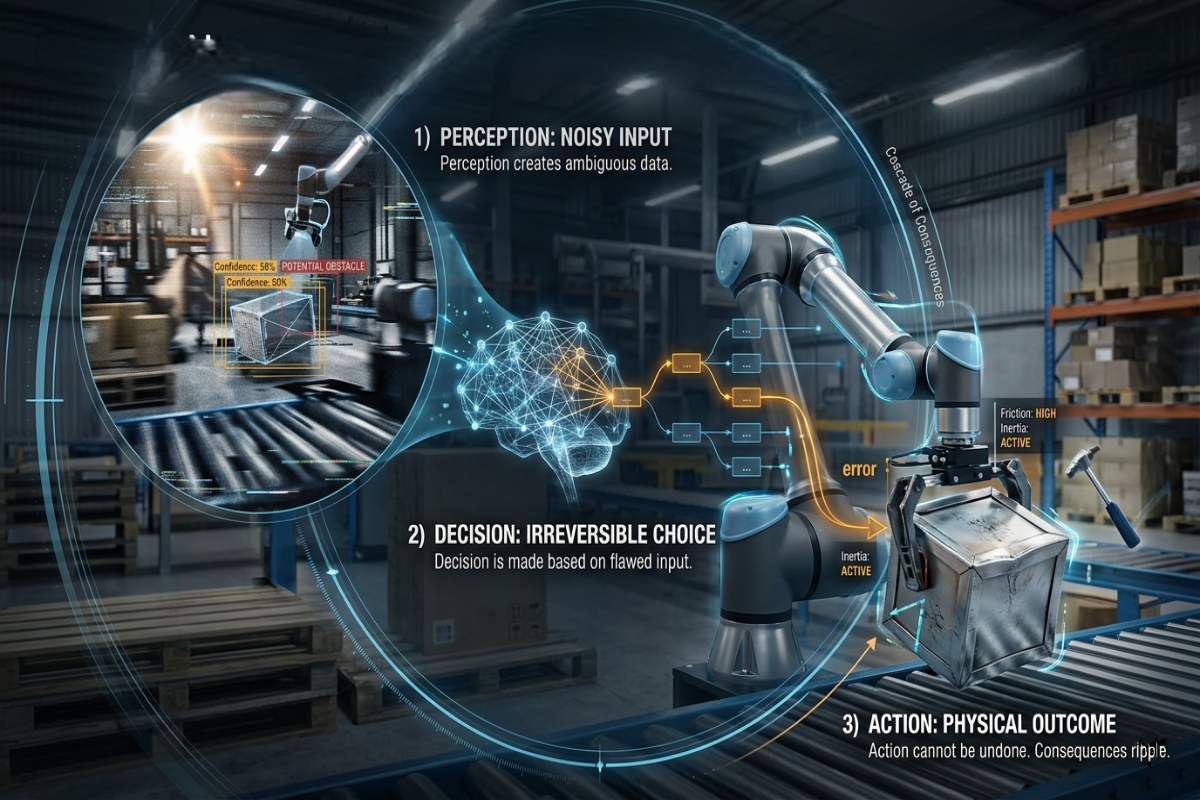
The perception-decision-action framework has been a fixture of AI agent architecture thinking for years. If you've worked on autonomous systems, intelligent agents, or robotic pipelines, you know these three as the fundamental capabilities that let a system function in the world: perceive what's around it, decide what to do, take action. The framework is correct. What changes when AI gets a physical body is what each of those words actually means.
In digital AI, the three capabilities describe a clean pipeline. The system receives inputs, processes them into a representation, reasons over that representation to make a choice, and produces an output. The output is information text, a recommendation, a classification, a plan. Each stage can be evaluated and optimized somewhat independently. Better perception improves the input quality. Better decision-making produces better choices given the same input. Better action generation produces better outputs given the same choice. Clean separability.
Physical AI breaks each of those three stages into a different problem and then breaks the separability assumption entirely.
What each capability actually means in physical environments
Perception interpreting a world that doesn't cooperate
Digital AI perception works with structured inputs. Camera images in standard formats. Text that's already been processed. Sensor readings that have been cleaned and normalized. The input arrives in a form that's been prepared for the model.
Physical AI perception works with what sensors actually capture in real environments which is partial, noisy, ambiguous, and constantly changing. A camera sensor in a warehouse doesn't deliver "the scene." It delivers light hitting a sensor array, with glare from overhead lights, with objects partially occluding each other, with movement blurring certain frames, with shadows creating false edges. The perception task isn't to process good data, it's to construct a usable understanding from imperfect data. That's a fundamentally different problem than digital perception, and it fails in different ways.
Decision: choosing when consequences can't be undone
A language model that generates a wrong answer can be corrected. You ask again, you rephrase, you get a better response. The cost of a wrong decision is regeneration time and some user frustration. That's a recoverable failure.
A physical agent that makes a wrong decision moves hardware into the physical world, and whatever happens next can't be rolled back. The wrong decision to grasp an object at the wrong angle doesn't produce a bad text output, it drops the object, potentially damages it, potentially damages the system, potentially harms someone nearby. Physical AI decision-making operates under a different cost structure than digital AI decision-making: the cost of being wrong is measured in physical outcomes, not in computational cycles. That irreversibility changes what "good decision-making" means and what training data needs to teach.
Action : commanding hardware with physics
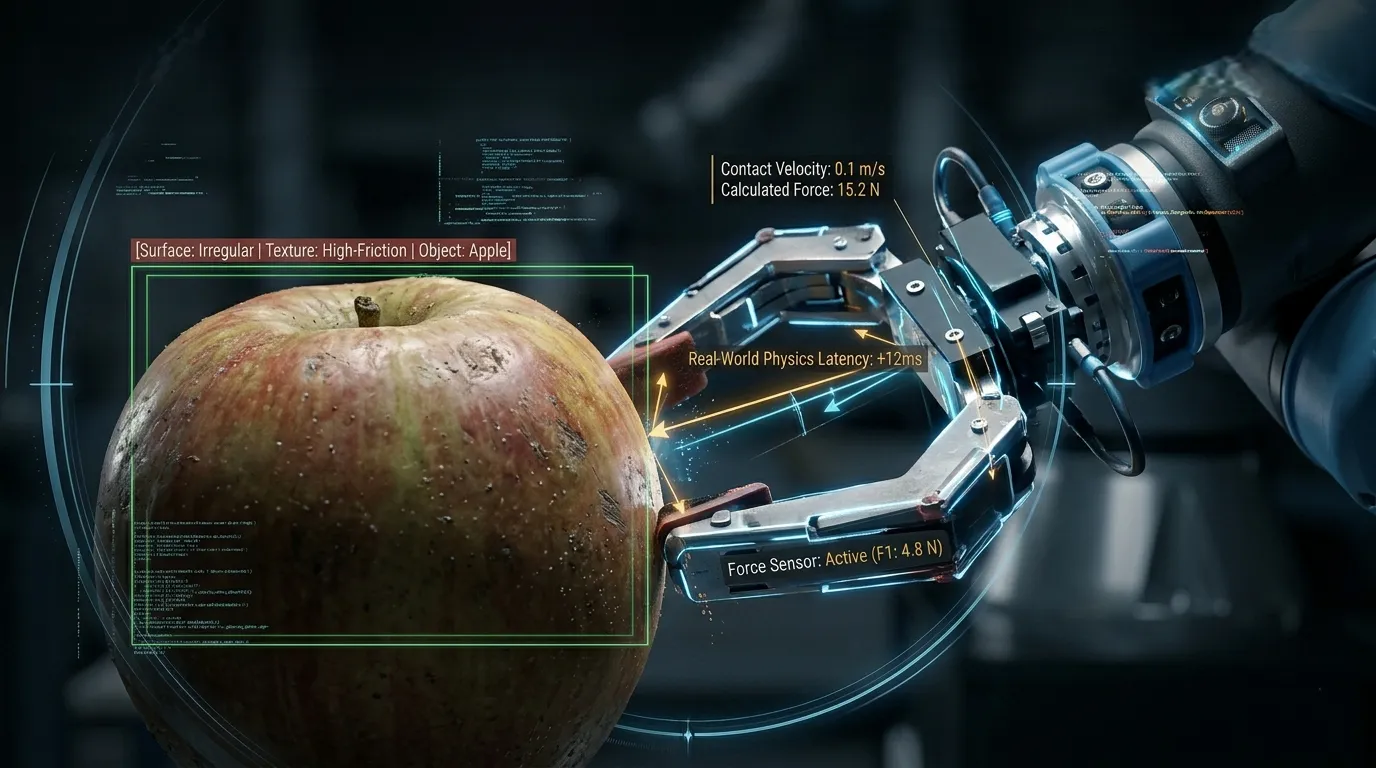
Digital AI action is output generation. The model specifies what should happen and it happens, the text appears, the API call returns, the recommendation surfaces.
Physical AI action is the point where model outputs enter a system with mass, inertia, friction, and mechanical resistance. The gap between "the model specifies this arm movement" and "the actuator actually executes this arm movement" is navigated through hardware, motors that have latency, encoders that have noise, joints that have mechanical play. The world pushes back, and the system has to handle the difference between intended action and executed action as a real-world constraint, not an abstraction.
Understanding what each capability requires in physical environments is the first half of the picture. The second half is how these three relate to each other in physical AI and that relationship is different from how they work in digital systems.
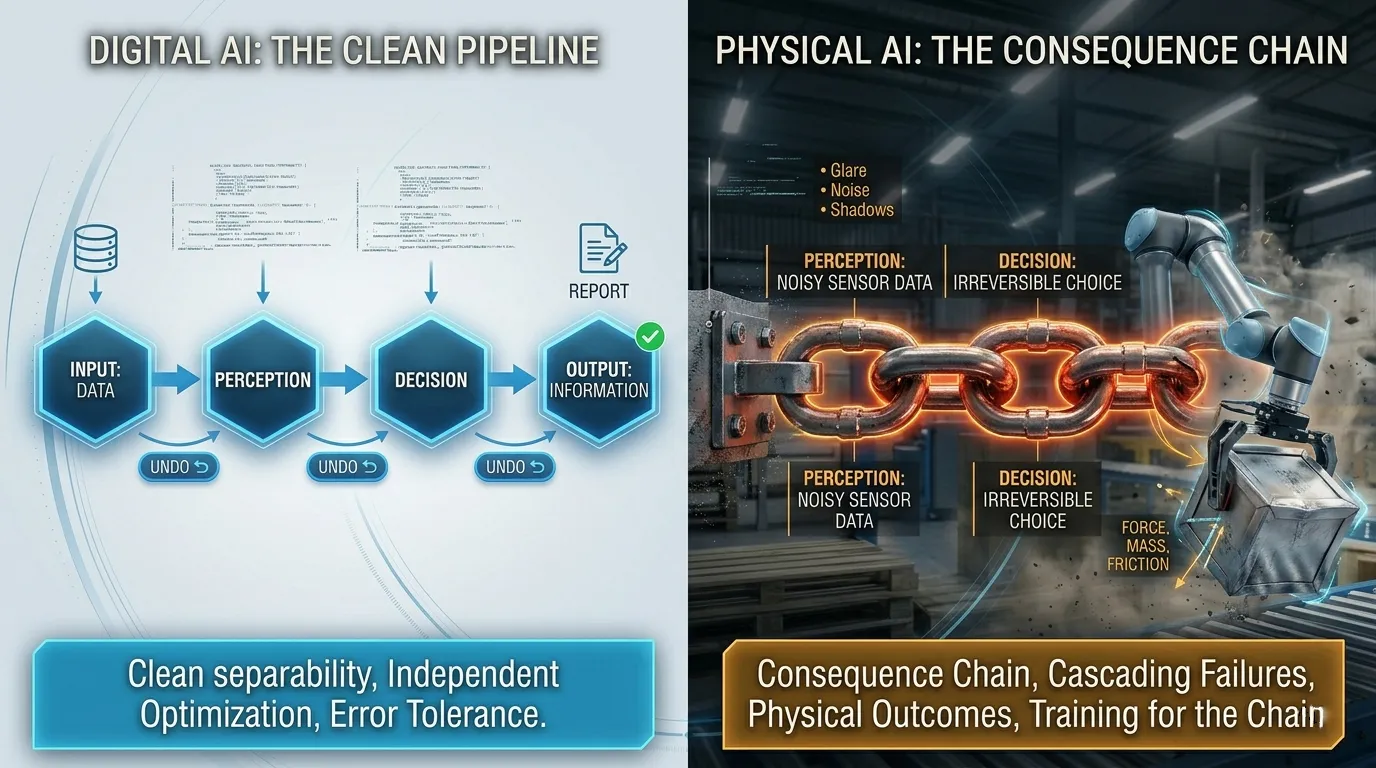
In digital AI agent design, you can optimize perception, decision-making, and action generation somewhat independently. A better perception module improves input quality, which improves everything downstream. Better decision logic produces better choices given equivalent inputs. Better output generation produces better action specifications given equivalent choices. The stages improve each other but can be worked on in isolation.
In Physical AI, these three capabilities form a consequence chain. Perception failure doesn't contain itself to the perception stage. It propagates into decision, which propagates into action, which produces a physical outcome in the world that cannot be undone. The failure mode isn't "wrong output in a context that tolerates correction" yet it's "irreversible physical event triggered by a cascade that started with an imperfect sensor reading."
This changes the nature of the training problem in a specific way. You cannot optimize each capability independently and then assemble a system that handles the cascade safely. A perception module trained on ideal-condition data might achieve high accuracy on its benchmark and still fail catastrophically in deployment, because the conditions where it produces uncertainty are exactly the conditions where that uncertainty propagates through decision into dangerous action. The training has to account for the chain.
In Physical AI collections we've designed for manipulation tasks, the critical data gaps consistently involve the handoff between capabilities rather than any single capability in isolation. A system might handle standard object detection reliably in most conditions, but under degraded lighting or partial occlusion, perception uncertainty triggers a decision to proceed when the system should pause and the resulting action damages the object or the environment. Addressing that gap requires training data specifically designed for the handoff: ambiguous sensor input → uncertain decision pathway → constrained physical action. Standard perception benchmarks don't reveal that gap. You find it when the consequence chain runs.

This consequence chain is what makes Physical AI training data design a different problem from digital AI training data design and it's where most teams discover gaps they didn't anticipate during development.
What building training data for Physical AI actually requires
When you're specifying training data for a Physical AI system, you're not filling three independent buckets. You're designing for a system where errors compound across a consequence chain. That changes what "comprehensive training data" means.
Perception data needs to include the degraded, ambiguous, real-world inputs where the system's interpretation becomes uncertain, not just the standard inputs where it performs well. The cases that matter most are the edge conditions: partial occlusion, inconsistent lighting, worn surfaces, unexpected object orientations. These are where perception uncertainty triggers downstream consequences.
Decision data needs to include the uncertainty scenarios, the situations where multiple plausible interpretations of a scene lead to different physical consequences. Training a decision capability only on clear-signal scenarios produces a system that performs well when perception is confident and fails without guidance when perception isn't. Real deployment is full of ambiguity.
Action data needs to include the gap between intended and executed movement including the recovery behaviors when execution doesn't match intention. Physical systems don't always do what they're told. Slippage happens. Forces are different than expected. The training has to include the full space of how action plays out in real physical conditions, not just the nominal case.
Building Physical AI training data for the full consequence chain
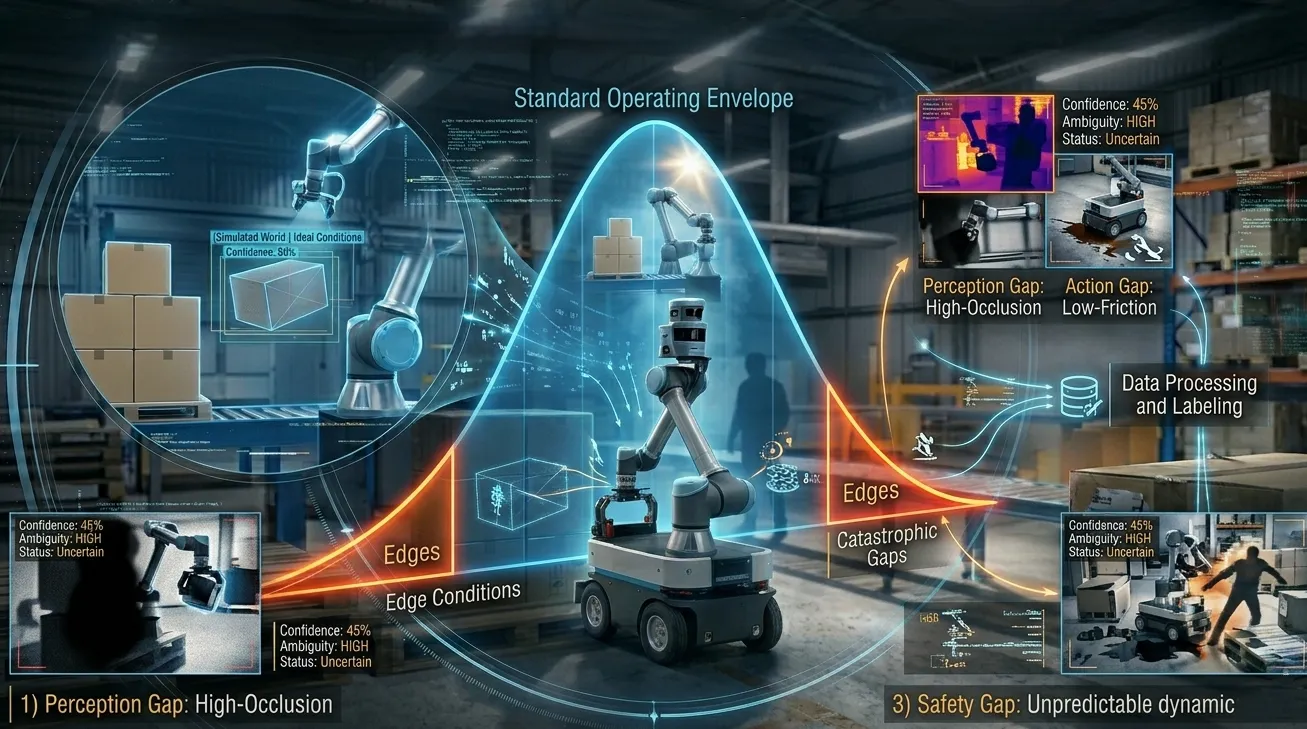
Physical AI succeeds when its training data was designed to prepare it for the full range of conditions it will encounter across all three capabilities, through all the handoffs where failure can propagate.
FutureBeeAI designs Physical AI training data collections that account for the consequence chain as a design input, not as an afterthought. The collection brief isn't "how much perception data do we need?" but it's "what physical scenarios create consequence-chain failures, and does our training data include those scenarios across perception, decision, and action?" Across Physical AI collection projects, the question we consistently ask at the design stage is: what's the worst physical outcome this system could produce, and what chain of perception-decision-action events leads there? Then we design the training data to include the ambiguous, uncertain, edge-case inputs that trigger those chains so the system can learn to handle them before deployment rather than fail at them in the field.
If you're building a Physical AI system and want to talk through what training data design looks like when you're optimizing for the full consequence chain, talk to the FutureBeeAI team.
FAQ
Q. Can a Physical AI system be strong at one capability and weak at another, or do all three develop together?
A. The three capabilities develop at different rates, and imbalances are common. A system can achieve high perception accuracy correctly classifying objects and conditions while still struggling with decision quality, particularly in scenarios that require longer-horizon planning or handling conflicting signals. Action precision is often the last to converge because it requires not just the right decision but accurate physical execution under real-world variability. What the consequence chain means in practice is that strength at perception is a prerequisite for decision quality, and decision quality is a prerequisite for action reliability. Improving action performance while leaving perception gaps unaddressed produces limited gains, the ceiling is determined by the weakest upstream layer.
Q. How do Physical AI systems handle situations they've never encountered during training?
A. Not reliably and understanding this is important for anyone deploying Physical AI. Systems trained on a specific distribution of environments and conditions degrade when they encounter meaningful deviations: different lighting, different object configurations, different surface types, different user behavior. The three capabilities degrade together because the consequence chain starts at perception. Modern approaches address this through systematic coverage during data collection (deliberately capturing at the edges of expected operating conditions), adversarial testing during evaluation, and staged deployment that monitors for distribution shift before expanding autonomy. Robust generalization comes from robust training coverage. No Physical AI system is distribution-independent, and claiming otherwise is a red flag in a vendor conversation.
Q. Why can't simulation data fully replace real-world training data for physical tasks?
A. Simulation is useful but can't fully replace real-world data because physical environments contain variations that simulators don't model completely. Surface friction, material deformation, sensor noise, lighting gradients and the behavior of real humans and objects in real settings all contain patterns that even high-fidelity simulators abstract away. The result is "sim-to-real gap" systems trained entirely in simulation often degrade in deployment because their behaviors were optimized for a simplified physical model. Simulation is valuable for safely exploring dangerous conditions and generating labeled data at scale. But closing the gap requires real-world collection, particularly at the edges of the deployment environment. The two approaches are complementary, not interchangeable.
Q. Which of the three capabilities is typically hardest to train?
A. Perception is typically hardest to get right at scale because the variation is enormous. A Physical AI system needs to perceive its environment correctly across a range of lighting conditions, viewpoints, object states and environmental configurations, each of which varies independently. Decision quality depends directly on perception quality, which means perception errors compound through the chain. Action precision, by contrast, is often the most tractable once perception and decision are reliable: executing a well-reasoned decision in a well-understood environment is a narrower problem than reasoning well from a poorly-perceived one. The practical implication for teams building or procuring Physical AI systems: training investment in perception coverage like breadth of environments, range of conditions, density at distribution edges pays outsized returns compared to action refinement alone.