A model clears internal evaluation. Word error rate sits comfortably below target. Accuracy crosses 90 percent. Human raters show high agreement. The dashboard is stable. From a technical standpoint, the system appears ready for production.

Then it meets the real world.
Regional users begin repeating commands because recognition falters on certain accents. A TTS voice that sounded natural in testing feels oddly flat to older listeners. A chatbot response that passed safety filters feels dismissive in a sensitive support interaction. Nothing collapses dramatically. The system does not crash. Instead, performance erodes quietly in places the evaluation process never truly examined.
This is where model evaluation fails. Not because metrics are weak, but because judgment is a narrow context.

Evaluation is not just about numbers. It is about who is judging the model, under what context, and with what lived experience.
Metrics measure consistency. Humans measure meaning.
When human judgment lacks diversity, evaluation produces confidence that does not generalize.
The Illusion of Objective Evaluation
Modern model evaluation frameworks are built around quantitative signals.
These metrics are essential. Without them, scale would be impossible.
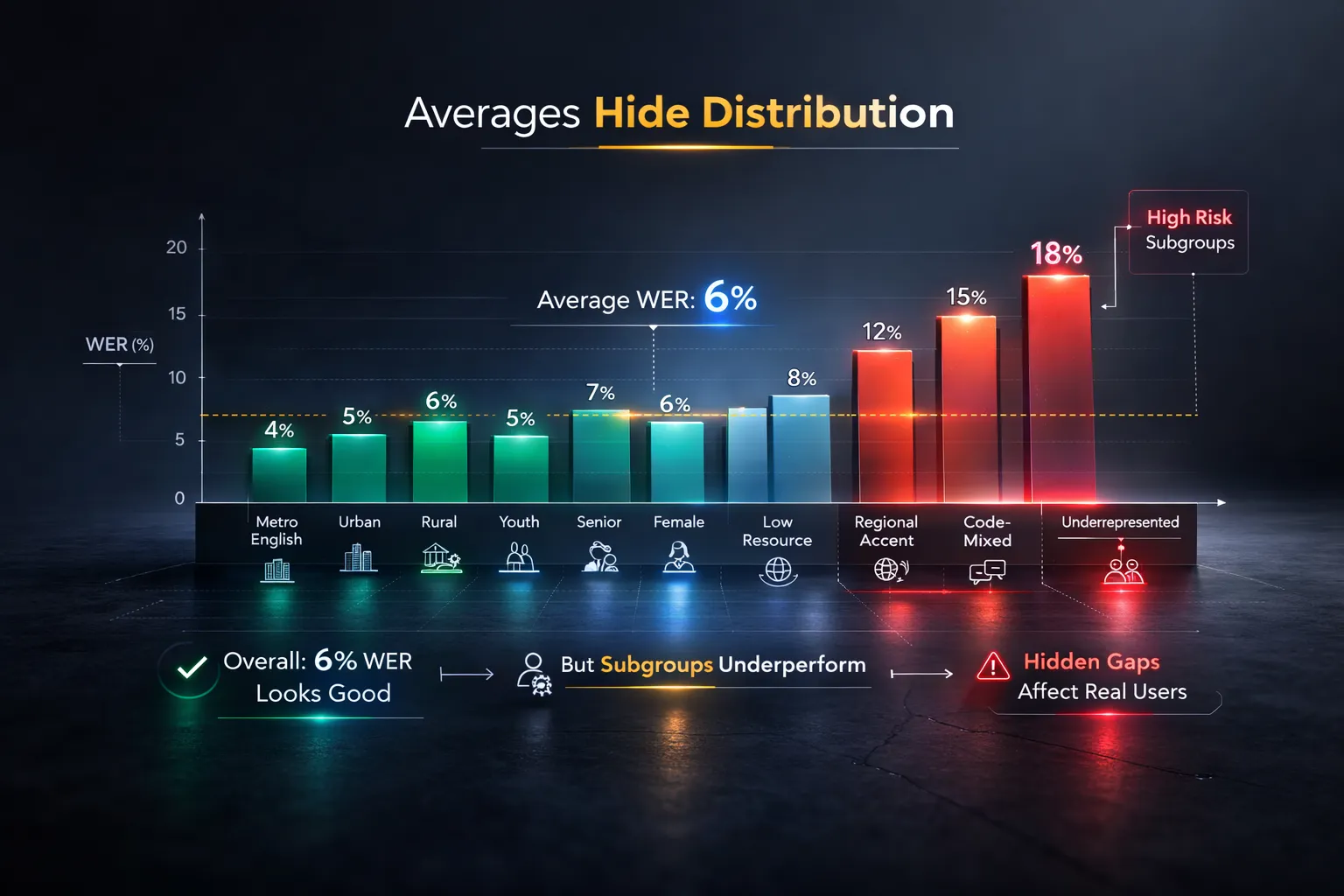
The problem begins when averages are mistaken for universality.
A system may report an overall WER of 6 percent across a test set. That number appears strong. Yet within that same distribution, WER may rise to 15 or 18 percent for specific regional accents. When results are aggregated, the edge cases disappear into the average. The dashboard shows improvement. The distribution hides inequality.
This is not hypothetical.
The 2018 Stanford study on racial disparities in commercial ASR systems showed that error rates for Black speakers were more than twice as high as for white speakers. Aggregate metrics masked subgroup harm.
Objective evaluation feels complete because it is measurable. But measurability is not the same as representativeness.
Metrics detect patterns at scale. They do not interpret how those patterns are experienced.
Where Model Evaluation Actually Breaks
Failures in model evaluation rarely stem from obvious technical errors. They emerge from contextual blind spots.
Accent and Dialect Blindness

Accent variation remains one of the most common sources of silent underperformance in speech systems.Diverse accent representation is foundational in scalable Speech Data Collection Services.
In multilingual Indian deployments, for example, Hinglish interactions such as “Doctor sahab sugar low lag raha hai” can confuse models trained predominantly on metro English datasets. In structured audits, WER has been observed to jump 12 to 15 percent higher in Tier-2 clinical environments compared to metro test sets.
Aggregated metrics conceal this gap.
A listener unfamiliar with a dialect may consider a misrecognized word close enough. A native speaker recognizes that meaning has shifted entirely. In healthcare, confusion between “hypoglycemia” and “hyperglycemia” is not a minor transcription issue. It is a safety risk. Clinical speech systems often require domain-specific datasets such as Doctor Dictation Speech Data and Doctor–Patient Conversation Speech Data, especially in regulated environments like the Healthcare AI industry.
These are not hypotheticals. They are recurring patterns from real deployments.
Cultural Semantics

Language models introduce deeper interpretive risk.
A sentiment classifier may label a statement neutral because it lacks explicit emotional markers. Within a specific cultural context, the same phrasing may signal restrained frustration or sarcasm.Robust NLP supervision depends on structured Text Annotation pipelines and culturally diverse Text Data Collection Services.
User research across age-diverse panels has shown up to 25 percent higher dissatisfaction scores among older users when tone calibration does not match generational expectations.
Directness signals clarity in some cultures. In others, it signals disrespect. Politeness norms vary. Humor shifts meaning. A homogeneous evaluation panel converges on shared interpretations and reinforces a narrow definition of acceptable output.
Automated metrics cannot capture this nuance. Even human reviewers overlook it when they share similar lived experiences.
Without diversity, bias embeds itself quietly into evaluation standards.
Domain Sensitivity

In high-stakes domains, nuance is not optional.
A conversational healthcare model may provide technically accurate information but phrase it ambiguously enough to introduce liability.
A robo-advisor bot may approve phrasing like “high-return bond opportunity.” A finance expert immediately flags mis-selling risk exposure, particularly in compliance-heavy sectors such as the BFSI industry.
Generic evaluators often mark these responses as correct. Domain-trained reviewers see structural risk.
Evaluation frameworks typically measure structural correctness. They rarely measure consequences.
When domain diversity is absent from evaluation, systems pass checkpoints while remaining fragile in production.
The Hidden Bias of Single-Panel Evaluation
Many organizations centralize human evaluation within a single QA team. Inter-annotator agreement is high. Processes are efficient.Structured labeling systems such as Audio Annotation and Text Annotation often drive this process.
But high agreement inside a homogeneous group often signals alignment of perspective, not robustness.
When evaluators share geography, education level, socio-economic context, and linguistic norms, their judgments align naturally. Agreement looks strong because interpretive frameworks are similar.
This is echo validation.
Structural pressures reinforce this model. Efficiency, cost containment, and simplified reporting encourage reliance on centralized panels. Subgroup analysis requires additional metadata infrastructure and disagreement mapping. It introduces operational complexity. Our platform, such as Yugo – AI Data Platform enables metadata-linked governance and evaluator diversity tracking.
Yet evaluation is governance.
As AI systems become infrastructure, evaluation design determines who experiences friction and who experiences fluency.

The most dangerous failures are not visible crashes. They are quite underperformance patterns.
Wake-word systems respond more slowly to elderly voices.
Voice assistants mis recognize commands more frequently in regional dialect clusters.
Emotional distress cues are misinterpreted in support chatbots trained on limited General Conversation Speech Data.
These gaps rarely trigger aggregate alarms.
Users adapt. They repeat commands. They modify speech. Over time, they disengage.
From an enterprise perspective, fixing such patterns post-deployment is expensive. Retraining pipelines, recollecting balanced data, and rebuilding trust costs significantly more than introducing structured diversity during evaluation. Scalable contributor sourcing through Crowd-as-a-Service reduces this risk earlier in the life cycle.
Early diversity reduces late remediation.
Metrics and Human Judgment Are Complementary
This is not an argument against quantitative evaluation.
Metrics remain foundational. They detect regression trends and allow cross-version comparability.
Human judgment is corrective.
Metrics reveal how often errors occur.
Humans reveal why those errors matter.
Metrics quantify distribution.
Humans interpret impact.
This complementarity powers true governance. It reinforces evaluation’s role as a decision about whose experience defines quality.
Evaluation should mirror the diversity of your deployment audience.
Evaluation as a Design Decision About Power
Evaluation defines optimization direction. Optimization direction shapes user experience. User experience determines who benefits.
Evaluation is not neutral. It encodes perspective.
When panels lack diversity, acceptable performance is defined narrowly. When panels expand, interpretive authority distributes more equitably.
That shift influences system behavior at scale.
Real-world deployment insights across industries are documented in our Case Studies.
What Robust Human-Centric Evaluation Looks Like
Strong evaluation frameworks incorporate structured diversity by design.
They:
Use stratified sampling across accents and dialects
Maintain multi-region evaluator pools
Integrate domain-trained annotators for healthcare, finance, and legal verticals
Analyze disagreement patterns rather than suppressing them
Link performance metrics with demographic metadata
Surface subgroup WER gaps, sentiment variance, and domain risk signals early
They do not rely solely on averages. They examine distributions.
They treat disagreement as a signal.
Distributed evaluation panels consistently surface significantly more edge-case behaviors early compared to centralized QA models. That visibility reduces downstream deployment risk.
Measuring Reality, Not Comfort
Model evaluation can reinforce reassurance or approximate reality.
When metrics are interpreted through diverse human judgment, they gain depth. When evaluation panels are narrow, dashboards improve while meaning becomes fragile.
If your AI systems operate across languages, cultures, and domains, your evaluation design must reflect that complexity.
Otherwise, you are not measuring performance.
You are measuring comfort.
Rethinking Your Model Evaluation Framework
If you are building or scaling ASR, TTS, or LLM systems:
Examine not only your metrics, but your evaluators.
Make subgroup performance visible.
Audit whether your panels reflect your deployment demographics.
Track disagreement instead of collapsing it.
FutureBeeAI works with globally distributed evaluator communities, structured validation methodologies, and metadata-linked analysis frameworks designed to surface silent underperformance early. Learn more about FutureBeeAI and our ethical approach on the About FutureBeeAI page.
Our distributed evaluation panels consistently uncover significantly more edge-case behaviors before deployment, strengthening robustness where it matters most.
If you want to audit your evaluation pipeline and reduce hidden bias before production, schedule a consultation through our Contact Page.
Because diverse systems deserve diverse judgment.






