A contributor taps “I agree” in twelve seconds. On the platform, that click grants permission to use their voice, image, or text to train AI systems powering call-center agents, healthcare tools, and multimodal models used globally. But a click made without real understanding is not consent; it’s a checkbox. And in AI data collection, checkboxes can be dangerous. Real informed consent depends on comprehension, not convenience, and the difference determines whether a dataset is built on trust or on ambiguity.
What Informed Consent Really Means in AI Contexts
 Informed consent has always meant more than a signature. It is an explanation, a context, and a choice made with clarity. In AI data collection, that clarity becomes even more important because contributors are authorizing the use of their voice, image, or text to train systems that can generalize far beyond the original project.
Informed consent has always meant more than a signature. It is an explanation, a context, and a choice made with clarity. In AI data collection, that clarity becomes even more important because contributors are authorizing the use of their voice, image, or text to train systems that can generalize far beyond the original project.
To be truly informed, consent must help contributors understand what their data is training, how identifiable they might be, who will use the dataset, and how long it will remain accessible. A generic statement like “your data will be used for AI training” is too broad to carry real meaning. The downstream implications of training a medical transcription model, a multilingual call-center bot, or a voice-cloning system are radically different. Contributors deserve specificity, not abstraction.
FutureBeeAI designs consent forms that clearly describe what the data will be used for, equally clearly state what it will not be used for, and explain retention periods and contributor rights. This transforms consent from a legal safeguard into a meaningful decision.
The Gap Between Compliance and Comprehension
Many organizations assume that meeting legal requirements automatically ensures ethical consent. But compliance and comprehension are not the same. A consent form written to satisfy a lawyer may leave contributors confused or hesitant, especially when literacy levels vary or when contributors come from regions with different norms regarding data privacy and institutional trust. A translated document may be linguistically correct but culturally misaligned.
This gap widens when collecting data across languages, cultures, and contexts where institutional trust and familiarity with AI vary widely. The challenge isn't just translating a form from English to Hindi or Swahili, it's recognizing that cultural attitudes toward data privacy, technology, and institutional authority differ fundamentally across regions. Treating consent as a one-size-fits-all legal document ignores this reality.
What Contributors Are Really Agreeing To
When someone consents to "AI training," the specifics matter enormously. A contributor needs to know whether their voice will help transcribe medical records or power a smart speaker. Those are different contexts with different implications.
Most platforms treat consent as an administrative step. FutureBeeAI treats it as part of the contributor experience. We explain actual use cases: speech recognition for healthcare applications, voice assistant training, and customer service automation, and we're equally explicit about what we won't use the data for. This specificity transforms consent from a legal formality into a meaningful choice. On Yugo, consent materials use simplified, localized language supplemented with helpful hint cards that explain use cases and terms in everyday phrasing. Contributors can even listen to the consent text through text-to-speech, a key feature for accessibility and for contributors who are more comfortable listening than reading. This focus on comprehension helps ensure that a click represents a decision, not confusion. For more on consent in medical datasets, check out our blog on doctor-patient conversation data.
The Three Pillars of Real Consent and Where They Break

Ethical AI data collection rests on three core pillars: transparency, comprehension, and voluntariness. These principles sound straightforward, yet each can collapse easily in practice.
Transparency: Telling Contributors What You're Actually Doing
It breaks when platforms use overly broad language such as “for research purposes,” which provides no real sense of how the data will be used. Consent needs granularity. Contributors must understand whether the dataset may be repurposed, what types of models are being trained, and how scope changes will be handled. At FutureBeeAI, we never rely on umbrella permissions for repurposed use. When a client’s needs change, we recollect consent with updated terms or initiate a new custom collection. A contributor’s original agreement is respected, not stretched.
Making It Understandable Across Languages and Cultures
Translating a consent form from English to another language is necessary but insufficient. A literal translation might preserve legal accuracy but miss cultural nuance in how people in different contexts understand privacy, trust institutions, or relate to technology.
Consider a contributor in a region where data privacy regulations are nascent or unenforced. They may not have the same frame of reference for "data rights" that someone in a GDPR-regulated country does. Or take contexts where collective decision-making is valued over individual autonomy, a consent process designed for Western notions of individual choice may feel alien or inadequate.
FutureBeeAI addresses this by localizing consent forms through professional translation for each project, not just converting words but adapting explanations to cultural contexts. We're also adding text-to-speech functionality so contributors can hear the consent form read aloud addressing both accessibility needs and literacy barriers.
Voluntariness: Ensuring There's No Coercion and a Real Opt-Out Exists
It breaks when contributors feel pressure to accept terms because they rely on the income. To address this, FutureBeeAI presents compensation information upfront during onboarding rather than burying it within the consent process. Payment terms are separated from consent entirely so contributors can decline without losing transparency about compensation. The opt-out button on Yugo is always visible, and the consequences of opting out are explained clearly. Contributors should never feel they must accept unclear or uncomfortable terms simply to access work.
Contributor Rights Beyond the Initial “Yes”
 Consent is not a moment. It is an ongoing relationship.
Consent is not a moment. It is an ongoing relationship.
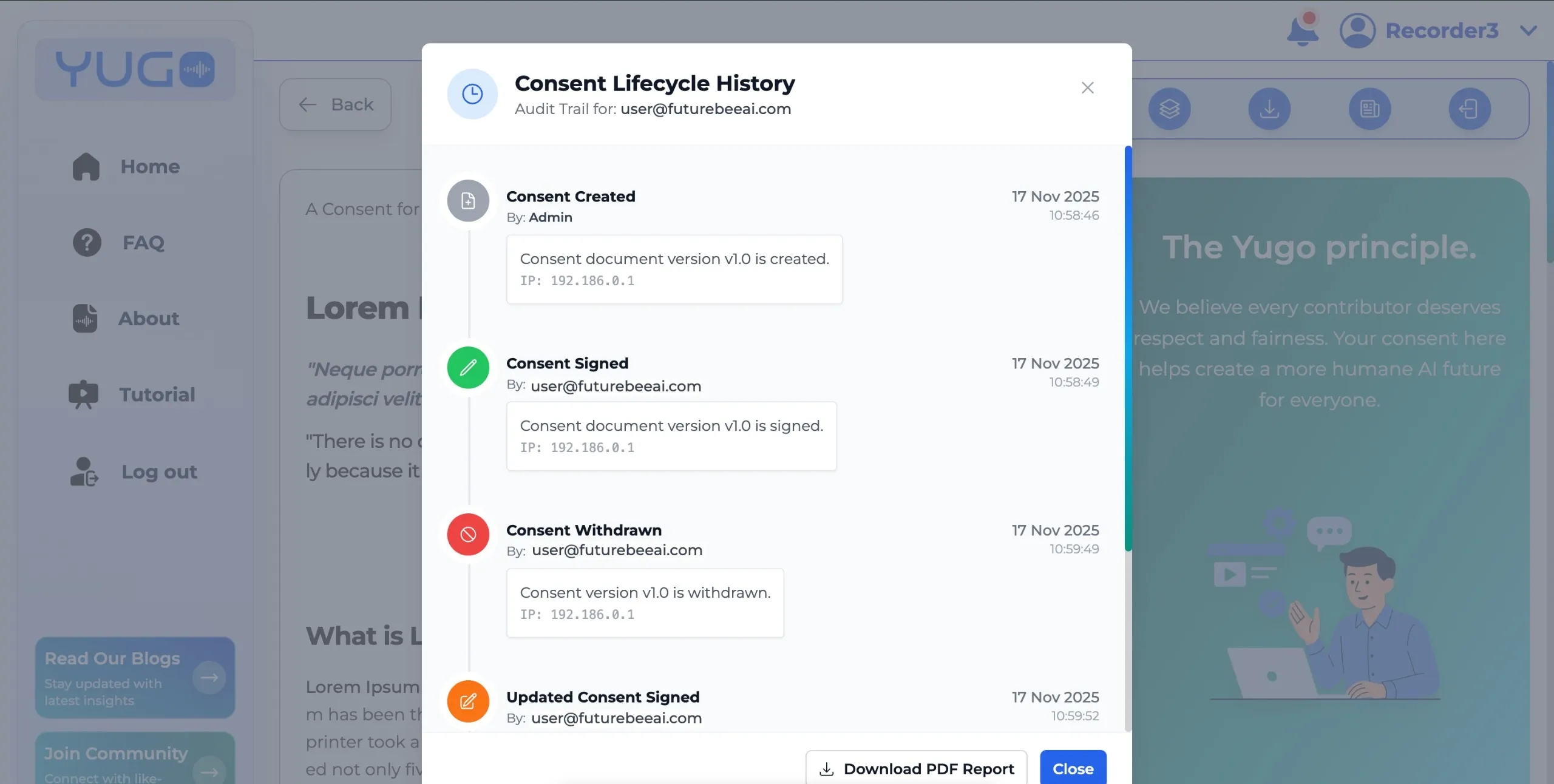
One of the most important but misunderstood rights is the right to withdraw. Withdrawal is possible, but its effectiveness depends on timing. At FutureBeeAI, if a contributor withdraws consent during an active project, their data is immediately flagged, excluded from all client deliveries, and placed into our deletion workflow. All flagged data is deleted within 30 days, and contributors receive confirmation once the deletion is complete. This is a predictable, transparent process.
However, there are technical limitations that honest platforms must disclose. If data has already been licensed to a client or incorporated into a trained model, withdrawal cannot undo those uses. This is not a loophole; it is an inherent property of model training. FutureBeeAI explains this upfront so contributors know exactly what withdrawal can and cannot achieve.
Contributors also deserve ongoing visibility into their relationship with the platform. We are building a unified contributor portal that will allow users to see their consent history across all projects, download signed records, view compensation logs, and initiate withdrawals or updates. Transparency shouldn’t end at the moment of consent; it should extend through the lifecycle of the contributor’s engagement.
Compliance Frameworks That Actually Matter
Consent in AI data collection cannot operate in isolation. It must align with real regulatory requirements and security frameworks.
GDPR offers the clearest definition of valid consent: freely given, specific, informed, and unambiguous. Operationalizing those principles requires avoiding pre-ticked boxes, providing clear explanations, enabling straightforward withdrawal, and maintaining auditable records of each consent action. FutureBeeAI follows these standards for all contributors, regardless of geography, because GDPR-aligned workflows reduce risk for clients and build trust with contributors.
California’s CCPA adds additional rights related to personal information and automated decision-making, reinforcing the need for transparent data practices. Meanwhile, the EU AI Act is shaping stricter requirements for transparency and data governance in high-risk AI systems, making strong consent practices essential rather than optional.
Security frameworks matter just as much as legal ones. FutureBeeAI’s ISO 27001 certification influences consent workflows directly through encrypted storage of consent records, mandated internal audits, and rigorous access controls. Consent that is not protected by security cannot be considered valid, no matter how well the text is written.
How FutureBeeAI Designs Consent That Works at Global Scale
Consent isn't paperwork at FutureBeeAI, it's product architecture. We've built infrastructure that treats informed consent as both a technical and ethical problem.
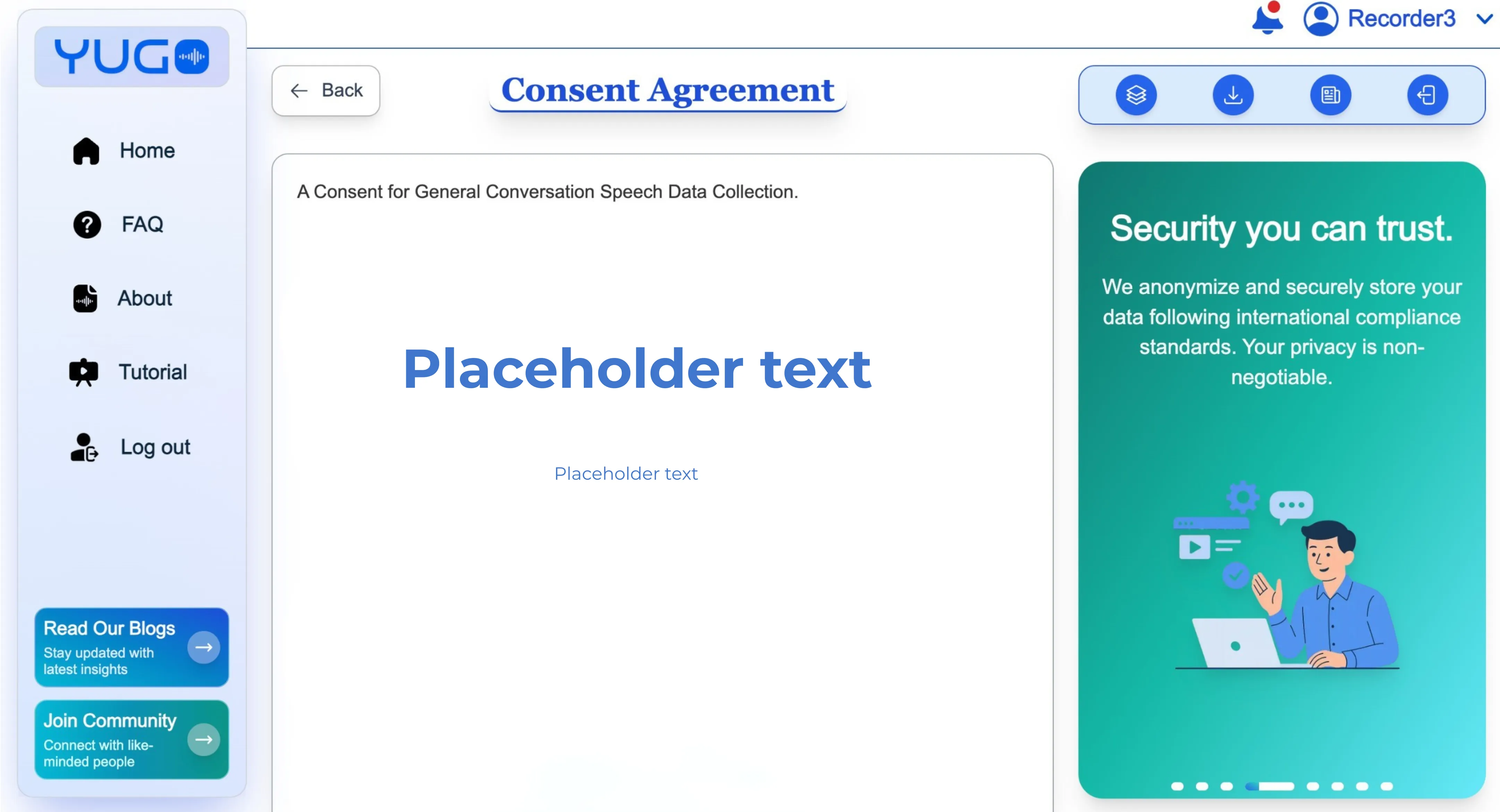 Consent is not a form attached to Yugo; it is part of the platform’s design philosophy. Every contributor begins their project experience with the consent screen, which cannot be bypassed.
Consent is not a form attached to Yugo; it is part of the platform’s design philosophy. Every contributor begins their project experience with the consent screen, which cannot be bypassed.
The layout is intentionally simple: the full text of the consent form, contextual hint cards on the side, a clear opt-out button and a download option to save a timestamped PDF record. This design ensures consent happens before any data collection and helps contributors make informed decisions without feeling rushed.
"Your data, your decision." Review exactly what you're consenting to and withdraw anytime. Full transparency, full control, always.
"No fine print, no surprises." We clearly explain how your data will be used, with no hidden terms or vague language. Read carefully and consent with confidence.
"Every voice counts." You're part of a global movement building responsible, inclusive AI that is ethically sourced, safely deployed, and fairly representative.
"Security you can trust." We anonymize and securely store your data following international compliance standards. Your privacy is non-negotiable.
Multiple Consent Modalities: Matching Mechanism to Context
Real consent also requires matching the mechanism to the sensitivity of the data. For low-sensitivity tasks, a checkbox is sufficient.
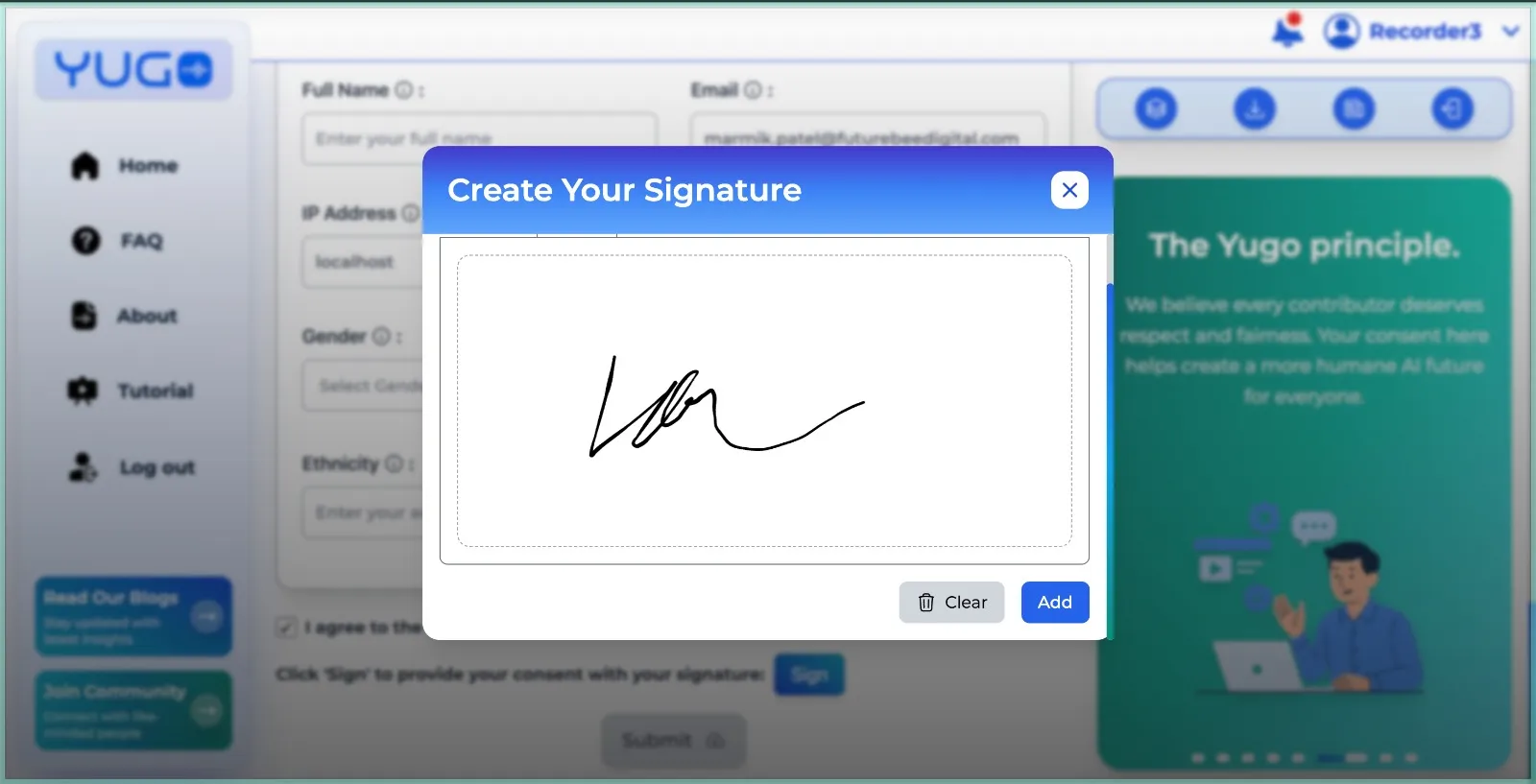 For ASR projects, a combination of checkbox and signature adds verification.
For ASR projects, a combination of checkbox and signature adds verification.
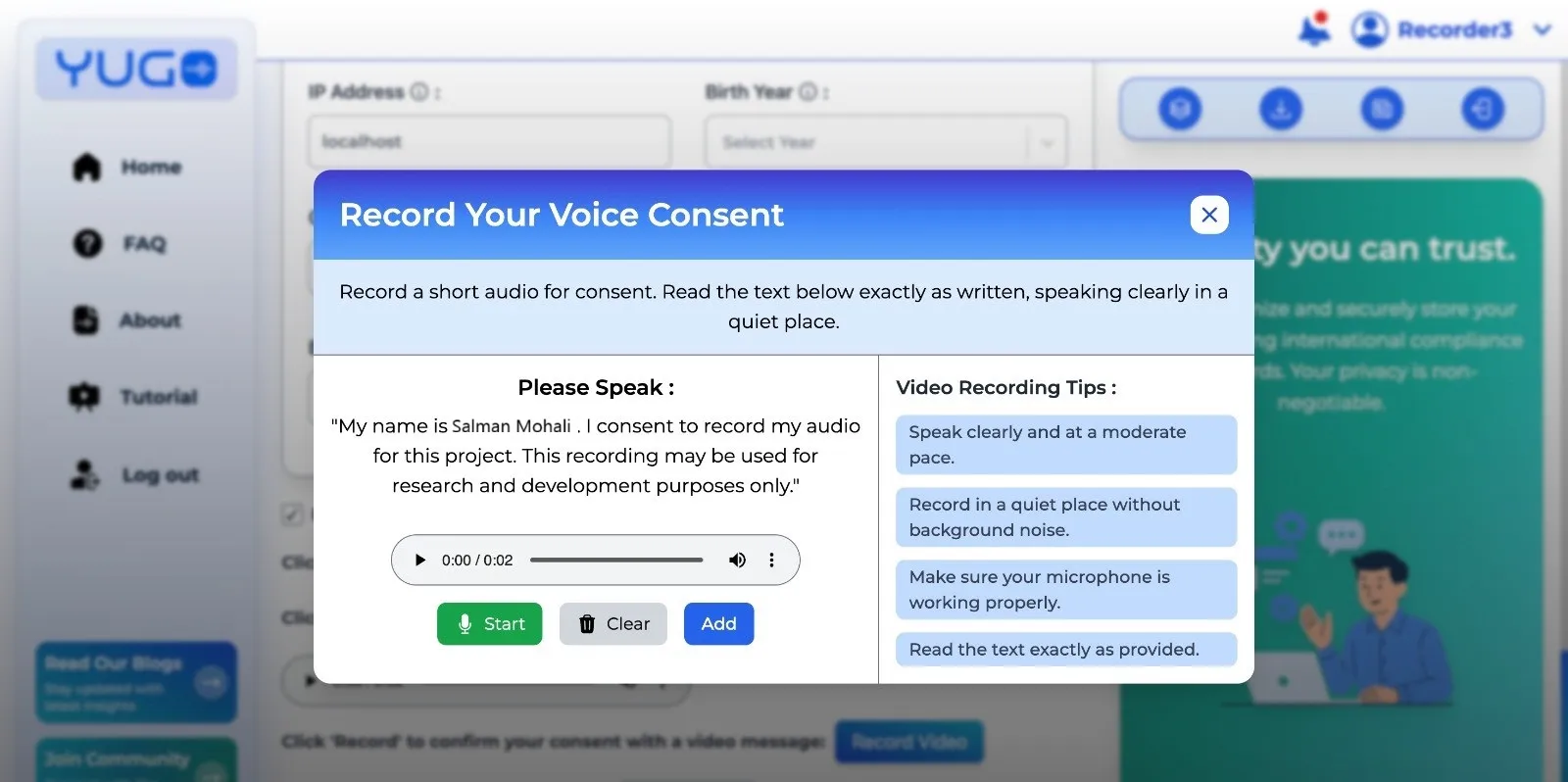 TTS or voice-cloning projects require voice consent paired with a signature, where contributors read a scripted statement that confirms consent while also validating voice quality.
TTS or voice-cloning projects require voice consent paired with a signature, where contributors read a scripted statement that confirms consent while also validating voice quality.
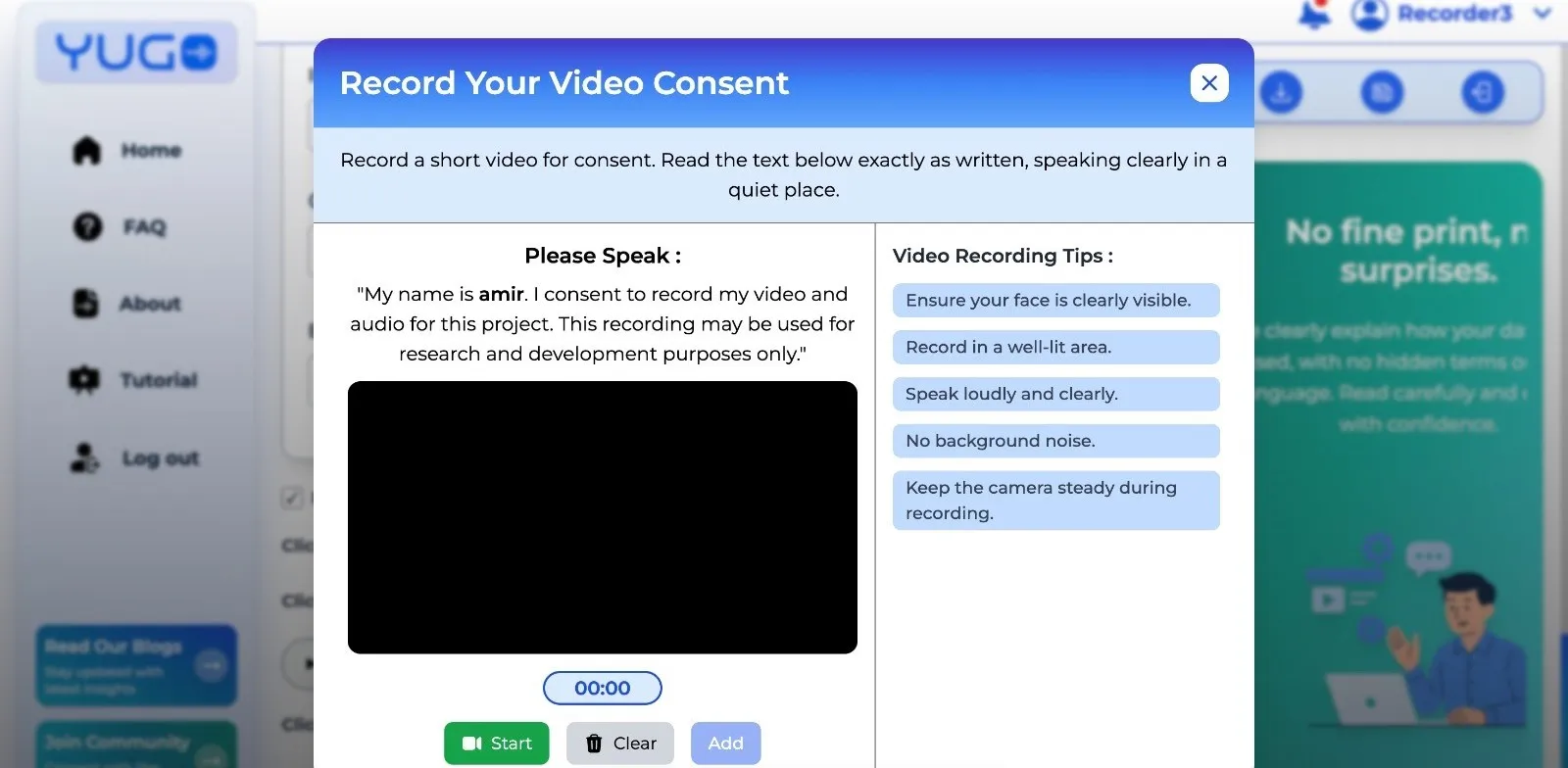 For biometric and facial data, video consent is used to create an additional layer of verifiable identity. These modalities acknowledge the different risks associated with different data types and ensure the consent method is proportionate to the sensitivity of the project.
For biometric and facial data, video consent is used to create an additional layer of verifiable identity. These modalities acknowledge the different risks associated with different data types and ensure the consent method is proportionate to the sensitivity of the project.
Localization and cultural nuance in consent
These are equally critical. FutureBeeAI adapts consent language to each region’s norms and expectations and uses text-to-speech to support contributors who may be more comfortable listening than reading. This reduces misunderstandings and helps ensure comprehension across a wide international contributor base. It can still fail if it doesn't align with local norms around privacy, institutional trust, and technology. We're also implementing text-to-speech functionality so contributors can hear the form read aloud, addressing accessibility needs for visually impaired users and literacy support for those who may struggle with written text.
Contributor Rights Beyond the Initial "Yes"
Consent isn't a one-time transaction. What happens after a contributor agrees matters just as much as the initial decision.
Right to Withdraw and What It Actually Means
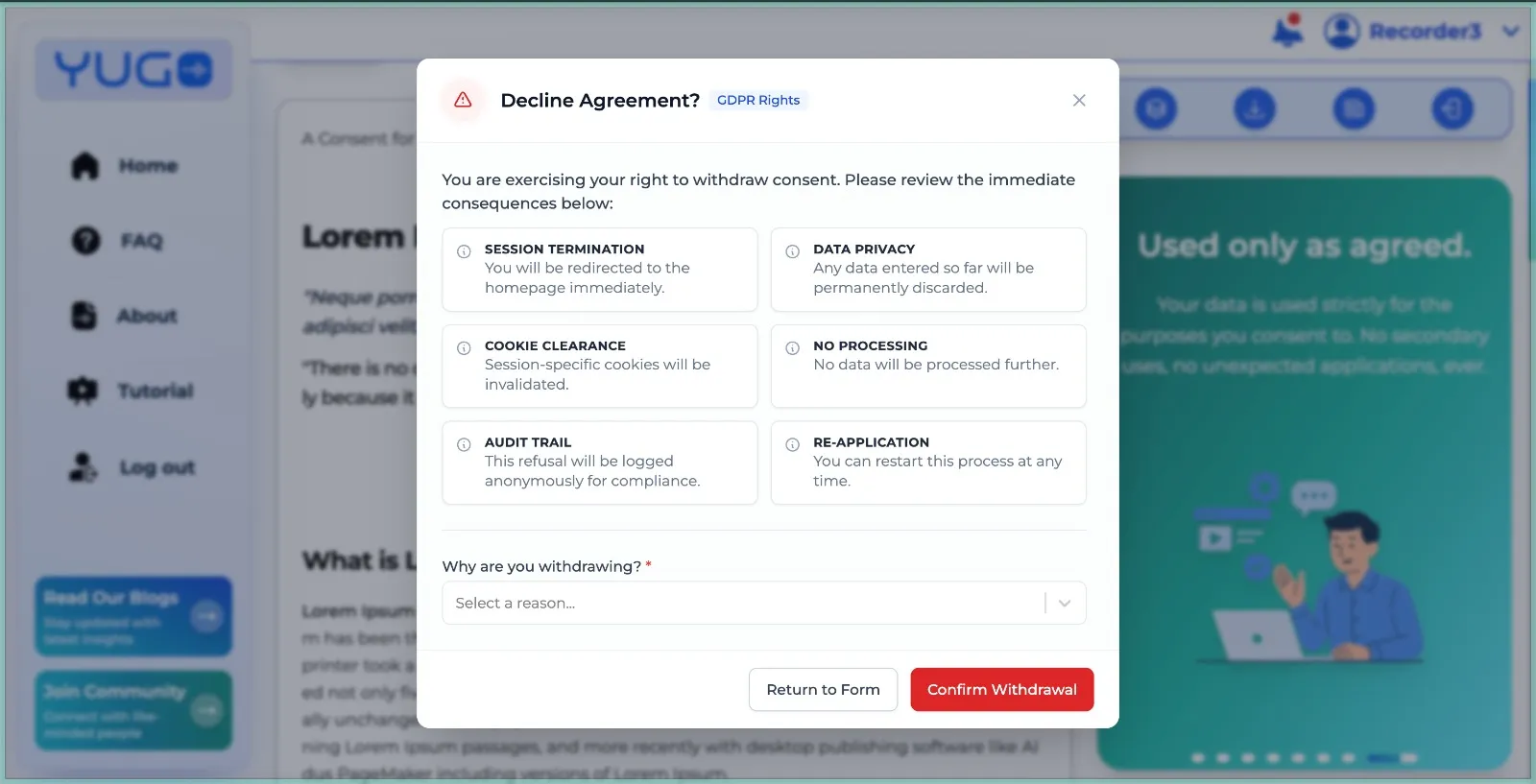 Withdrawal processes are equally strict. Once a contributor opts out, their data is flagged instantly and excluded from deliveries. Deletion occurs within 30 days, and contributors receive confirmation afterward. Once deletion is complete, contributors receive notification via platform message and email.
Withdrawal processes are equally strict. Once a contributor opts out, their data is flagged instantly and excluded from deliveries. Deletion occurs within 30 days, and contributors receive confirmation afterward. Once deletion is complete, contributors receive notification via platform message and email.
If project scope changes midway, the system automatically triggers a new consent request that contributors must accept before continuing. Without this, consent would fail to keep up with evolving AI projects.
Internal platform data shows that contributors spend 12-20 minutes reviewing consent materials and that our completion rate is approximately 97 percent, with the remaining percentage representing contributors who opt out or withdraw. These insights come from platform analytics and reflect how careful design leads to higher comprehension and comfort.
What We're Building Next: Unified Contributor Portal
We are also developing additional features such as voice-enabled consent responses, granular project-level updates, and a unified contributor portal. These enhancements reflect our belief that consent must evolve alongside the complexity of AI systems.
Red Flags: What Bad Consent Looks Like
Many organizations claim to follow ethical consent practices, but the gaps become clear upon closer inspection.
- Vague language like “to improve our services” or “for research purposes” provides no real sense of how data will be used.
- Consent buried inside lengthy legal terms is another warning sign, as is generic translation that doesn’t account for local norms. Platforms that hide compensation details until after consent or provide no straightforward withdrawal mechanism should raise immediate doubts.
- One-size-fits-all consent across languages and cultures. A generic, translated consent form that doesn't account for cultural differences in privacy expectations or institutional trust is a red flag. Consent should be localized, not just translated.
- No clear withdrawal mechanism or contributor contact. If there's no obvious way to opt out or reach the platform with questions, the consent process wasn't designed with contributors in mind.
- Lack of compensation transparency or contributor rights documentation. If a platform doesn't clarify payment upfront or explain contributor rights clearly, it's treating consent as a formality rather than a foundation.
The most serious red flag, which unfortunately does occur in parts of the market, is the use of forged signatures or fabricated contributor data in place of real consent.
Why This Matters Now
Legal and Reputational Risk
The stakes around consent have never been higher. Regulations are tightening, and public expectations of ethical AI practices are rising rapidly. Companies that rely on datasets without provable consent risk fines, product delays, brand damage, and legal challenges. But beyond risk mitigation, consent also influences model quality. Contributors who understand and trust the platform provide clearer, more accurate, and more consistent data. Ethical AI data collection practices are not only moral; they produce better models.
Model Quality and Trust
FutureBeeAI approaches consent as infrastructure: technical, ethical and operational. Our workflows are built not to satisfy the minimum legal threshold but to create trust with contributors and confidence for clients. This is the difference between dataset vendors and dataset partners. Vendors treat consent as paperwork. Partners treat it as the foundation for long-term, ethically sourced AI development.
FutureBeeAI's Position
 At FutureBeeAI, we've built infrastructure that treats consent as both a technical and ethical problem, not paperwork. We've designed workflows that function across languages, cultures, and data types. We've implemented audit trails, withdrawal mechanisms, and compensation transparency. We've chosen to recollect consent when project scope changes rather than rely on vague initial permissions.
At FutureBeeAI, we've built infrastructure that treats consent as both a technical and ethical problem, not paperwork. We've designed workflows that function across languages, cultures, and data types. We've implemented audit trails, withdrawal mechanisms, and compensation transparency. We've chosen to recollect consent when project scope changes rather than rely on vague initial permissions.
Ready to build AI with datasets grounded in real consent? Explore FutureBeeAI's ethically sourced datasets or contact us to discuss custom data collection built on transparency and contributor trust.






