The Meeting Where Everyone Pretended Not To Know
Picture a quarterly governance review at a mid-sized financial services firm eighteen months into a flagship AI deployment. The slide on the screen reads “100 percent human oversight maintained across all decision workflows.” The compliance lead nods. The board representative writes something down. The product head confirms that the system has processed several million cases since launch.
Three floors below that meeting room, fourteen reviewers are working through a queue of roughly two hundred and forty decisions per shift. Most of the cases are being approved in under a minute. Not because the cases are simple. Not because the reviewers are careless. The approvals are happening that quickly because the alternative is a growing backlog that nobody in that meeting room wants to explain.
This is not a story about rogue AI. It is not a story about negligent teams or irresponsible vendors. It is a story about a perfectly ordinary enterprise system that implemented human-in-the-loop oversight successfully at small scale and then scaled the model faster than it scaled the governance architecture around it.
Technically, humans are still in the loop.
Operationally, they are no longer governing the system. They are logging approvals.
Across enterprise deployments, this pattern appears with surprising consistency. The failure is rarely dramatic. The AI does not suddenly start performing worse. Reviewers do not revolt. Dashboards do not turn red.
What actually happens is a slow structural shift where the human oversight layer gradually loses its functional role while its formal presence remains intact.
Understanding this shift requires looking at human-in-the-loop systems not as a single process but as a governance architecture that changes under scale pressure.
Across many enterprise AI deployments, the same progression appears again and again. The breakdown follows a predictable pattern that can be described as the HITL Oversight Decay Model.
This model explains why systems that appear robust during early deployment quietly lose the ability to provide real oversight once volume, speed, and operational complexity increase.
Why Human-in-the-Loop Feels Unbreakable at Small Scale
Every organization that deploys human review layers successfully at a small scale remembers why the system felt strong in the beginning.
The review team was small. The case volume was manageable. Reviewers spoke with each other constantly. Edge cases were discussed in shared channels or informal meetings. Standards evolved through discussion rather than documentation.
The process itself was rarely perfect. The rubric might have been incomplete. Some decision categories may not have been clearly defined. Yet the system worked because human judgment filled the gaps.
When something looked strange, a reviewer raised it. When model behavior seemed inconsistent, someone noticed the pattern. When a mistake happened, the responsible reviewer could be identified instantly, and the team corrected the standard together.
What made the system reliable was not the documented workflow. It was the density of human judgment operating in close proximity.
The feedback loop between reviewers, data teams, and model developers remained tight. Small calibration differences surfaced quickly and were corrected before they affected the system.
Scale slowly dismantles this structure.
The HITL Oversight Decay Model
When human-in-the-loop systems scale inside enterprise AI environments, they typically degrade through five predictable structural failures.
Queue Saturation
Calibration Drift
Accountability Diffusion
Cognitive Rubber-Stamping
Governance Scope Erosion
Each stage appears manageable in isolation. Together, they gradually transform the oversight layer from a genuine control system into a procedural formality.
Failure One: Queue Saturation
Human attention does not degrade gradually under increased workload. Cognitive science has shown repeatedly that decision quality remains relatively stable up to a certain threshold and then drops sharply once that threshold is crossed.
Research on decision annotation fatigue bears this out directly. A widely cited 2011 study by Danziger et al. published in PNAS examined over 1,100 judicial parole decisions and found that favorable rulings dropped from roughly 65% at the start of a session to nearly zero before a food break — then reset after it. The mechanism in annotation pipelines is identical: sustained decision volume depletes the cognitive resources required for independent evaluation, leaving pattern-matching as the default.
In human review systems, this threshold usually appears when review volume per reviewer doubles without structural redesign of the workflow.
Consider a speech recognition dataset review pipeline used to validate call center transcripts before they are added to a training set. At low volume, a reviewer might examine eighty segments per shift. They listen carefully, check transcription accuracy, verify speaker separation, and mark edge cases that require escalation.
As dataset collection scales globally, that same reviewer may be asked to process one hundred and sixty segments per shift. The decisions still happen. The labels are still logged. Throughput metrics look healthy.
But the cognitive quality of the review changes.
Instead of listening fully to each segment, the reviewer begins pattern matching. If the transcription confidence score appears high and the text looks plausible, the segment is approved quickly.
The system still records a human decision. What has actually changed is that the model’s confidence score has quietly become the primary input into the decision process.
The independent check has become a confirmation step.
An analogy from air traffic control captures the dynamic clearly. A controller managing five aircraft can maintain a full mental model of the airspace. The same controller managing twenty aircraft must rely more heavily on automated signals and pattern recognition.
The operational log shows decisions being made continuously in both scenarios. What the log cannot show is how much independent cognitive evaluation each decision received.
The signal to watch inside enterprise AI systems is subtle but measurable. Average review time per case decreases while approval rates remain constant or increase. Each metric alone appears healthy. Together, they indicate queue saturation.
Failure Two: Calibration Drift
Queue saturation introduces the second structural failure. Once reviewers operate under sustained volume pressure, they lose the opportunity to calibrate their decisions with one another.
In healthy systems, small disagreements surface frequently. Two reviewers interpret an edge case differently and resolve the difference through discussion. Over time, this process produces a shared operational standard.
Under high-throughput conditions, those discussions disappear.
Edge cases are labeled differently depending on who reviewed them, what part of the shift they appeared in, and how fatigued the reviewer was at that moment. Each decision appears reasonable in isolation. Over time, the collective label distribution becomes inconsistent.
This issue becomes especially critical in data pipelines that feed model retraining.
For example, multilingual speech datasets used for training automatic speech recognition models rely heavily on human verification for accent coverage, background noise handling, and dialect normalization. When reviewer calibration drifts, the resulting dataset begins to contain subtle inconsistencies in labeling standards across regions and annotator groups.
From the model training perspective, this appears as noise in the training signal. Retraining cycles continue. Benchmark scores may still improve slightly. Yet the model stops improving in exactly the scenarios that matter most in production.
This is not a theoretical risk. A 2021 audit of a large-scale medical imaging annotation project (reported anonymously in an IEEE data quality working group summary) found that inter-annotator agreement on ambiguous cases fell from 84% in the first month of the engagement to 61% by month six, despite no changes to the annotation guidelines. The sole structural change in that period was a threefold increase in daily volume per annotator. The degraded labels were fed two retraining cycles before the drift was detected through a targeted calibration audit.
The problem is rarely the architecture of the model. The issue is the quality and consistency of the human-generated labels feeding the retraining pipeline.
Organizations often discover this only months later when real-world performance plateaus without an obvious explanation.
One of the most useful indicators of this failure is the inter-reviewer agreement rate. If that metric is not actively monitored in the annotation pipeline, the system may already be producing degraded training data.
Failure Three: Accountability Diffusion
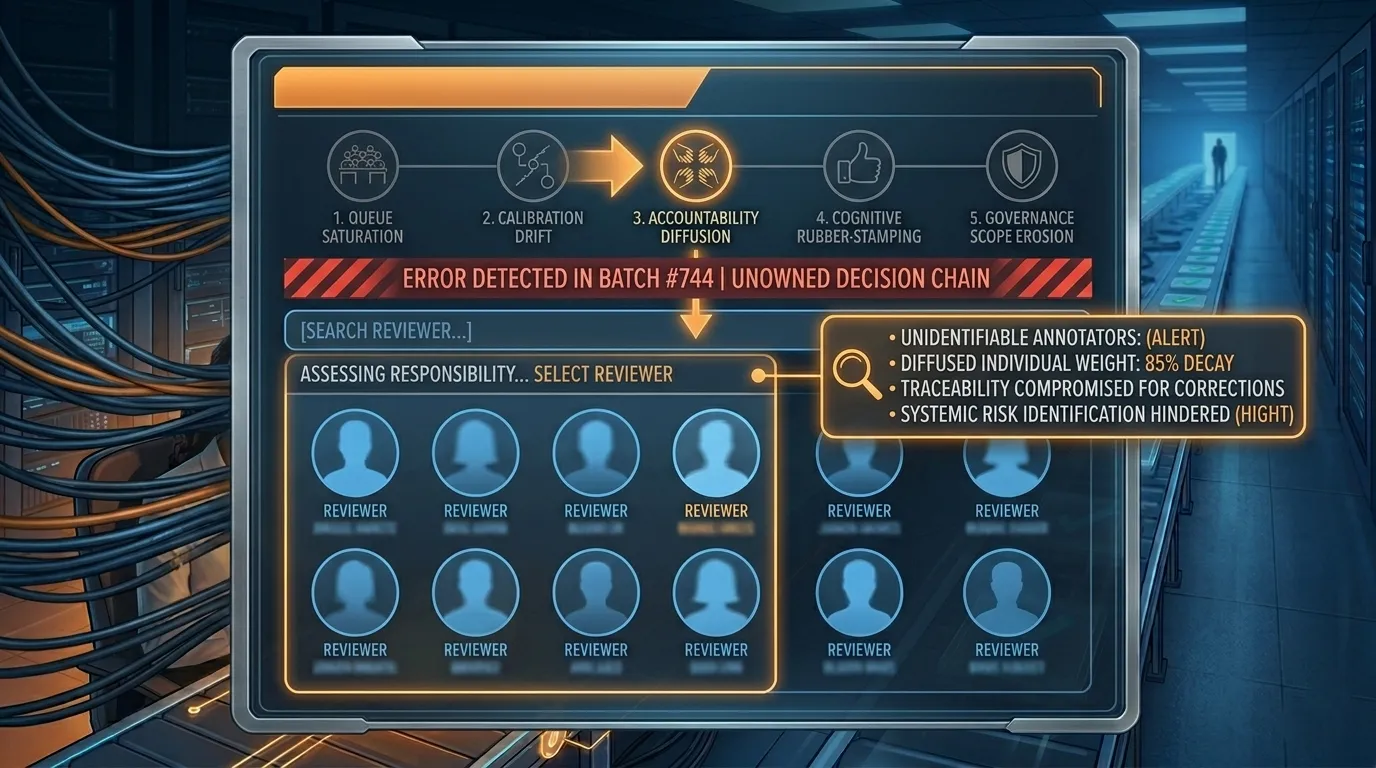
Early-stage review teams rely heavily on social accountability. When a team of ten reviewers operates in close proximity, everyone knows who approved which decisions. Errors have identifiable authors. Professional reputation naturally shapes behavior.
As review operations scale to dozens of reviewers distributed across shifts and locations, this social visibility disappears.
Responsibility becomes distributed across the entire team. Each individual reviewer becomes a small part of a large system.
This mirrors what social psychologists call the bystander effect, first documented by Darley and Latané following the 1964 Kitty Genovese case, and since replicated across hundreds of organizational studies. In their foundational experiment, individuals who believed they were the sole witness to an emergency intervened 85% of the time; when they believed five others were also present, that rate dropped to 31%. In distributed review teams, no one believes they are the sole decision-maker, and behavior shifts accordingly. When responsibility is spread widely across many individuals, the perceived weight of individual accountability decreases.
In large annotation operations, this often manifests as a subtle shift in review discipline. Reviewers still complete their tasks responsibly, but the psychological ownership of each decision becomes weaker.
In large-scale dataset production environments, this problem can have direct operational consequences. Consider image annotation pipelines used for training computer vision models in retail or autonomous vehicle contexts. When accountability is diffuse, it becomes difficult to trace the origin of labeling inconsistencies across thousands of annotated images.
Without clear ownership structures, even well-designed quality control processes struggle to maintain consistent standards.
A simple operational test reveals whether this failure has begun. If a problematic annotation was discovered today, could the system identify the specific reviewer responsible for that decision within minutes using standard tooling?
If that requires manual investigation, the accountability structure has already weakened.
Failure Four: Cognitive Rubber-Stamping

Sustained exposure to repetitive decision-making produces another well-documented effect. Human judgment begins to converge toward the base rate of outcomes that appear most frequently.
In high-volume review environments, reviewers begin approving cases that resemble previously approved patterns rather than evaluating each case independently.
In AI data pipelines, this often appears when reviewers begin relying heavily on model-generated confidence scores.
Imagine a dataset curation workflow for training wake word detection systems. The model flags thousands of short audio segments containing potential wake word triggers. Human reviewers verify whether the wake word is present and whether background noise or overlapping speech could confuse the model.
At low volumes, reviewers examine each segment carefully. At higher volumes, they begin using the model’s confidence score as a shortcut. High-confidence predictions are approved rapidly. Low confidence predictions receive slightly more attention.
The human and the model were originally intended to provide independent signals. Over time, both signals begin reflecting the same underlying pattern.
The most revealing indicator of this failure is how the system handles low-confidence cases. In healthy review systems, these cases receive deeper scrutiny and have significantly lower approval rates.
When approval rates for low confidence cases approach overall approval rates, the human review layer is no longer functioning as an independent validation mechanism.
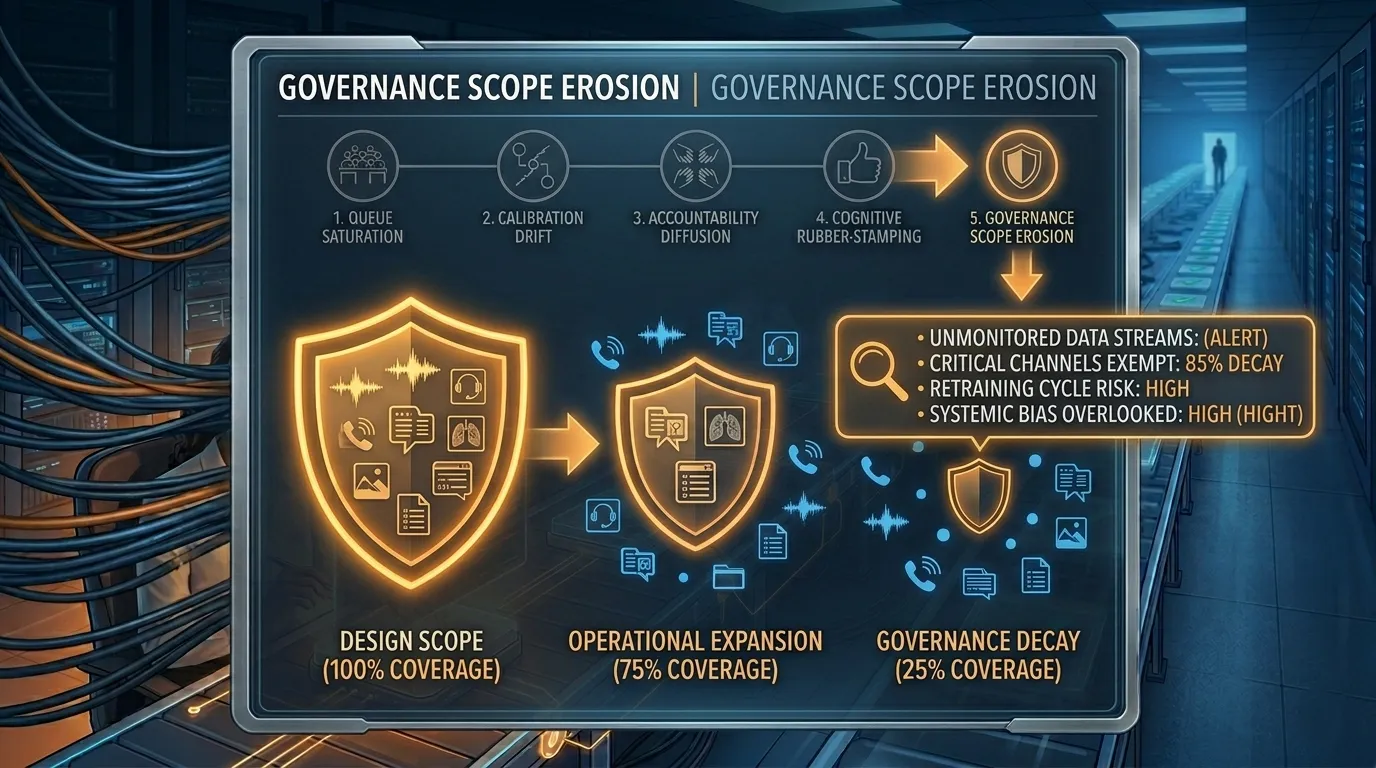
Failure Five: Governance Scope Erosion
The final stage of oversight decay happens in management meetings rather than review queues.
As AI systems scale, human review becomes the slowest component of the decision pipeline. Product teams face pressure to maintain response time commitments and operational efficiency.
The first adjustment often appears reasonable. A specific category of low-risk decisions is allowed to bypass review.
Later, another category receives the same treatment. Each decision is individually justified. None of them triggers a full governance review.
Gradually, the scope of decisions subject to human oversight shrinks while official documentation continues to claim comprehensive oversight.
This stage is particularly difficult to detect because the system still technically includes humans in the loop. The loop simply covers fewer cases than originally intended.
A careful comparison between the original governance design and the current operational scope often reveals how much the review perimeter has shifted over time.
Designing Human Oversight That Survives Scale
The five failures described earlier rarely occur because organizations stop caring about oversight quality. They happen because the structures supporting that quality were never designed to hold under scale pressure. When annotation pipelines expand, model retraining cycles accelerate, and throughput expectations increase, review systems that worked well at small volumes begin to degrade.
The principles below are not corrective measures applied after problems emerge. They are architectural decisions that must be built into the system before scale creates conditions that make oversight difficult to repair.
Tiered Review Architecture
Human attention is a finite resource. Treating every decision as equally deserving of review guarantees that the decisions that actually matter will receive the same amount of scrutiny as the ones that do not.
Tiered review addresses this constraint by routing decisions based on consequence. High-stakes outputs and cases where the model shows uncertainty receive full human review, while routine cases with strong historical consistency move through automated or sampled validation layers. The logic is straightforward: human attention is concentrated where it produces the greatest improvement in data quality.
The difficulty emerges in how most organizations define these tiers. In many systems, routing decisions are determined primarily by model confidence scores. High-confidence predictions move through a fast path while low-confidence predictions are routed for deeper review.
This creates a structural blind spot. The fast path now contains every case the model is confident about, including the cases where it is confidently wrong.
In speech and language pipelines this appears frequently when models assign strong probabilities to incorrect phoneme interpretations or mis-handle dialect variations. Audio segments that contain unfamiliar accents, code-switching between languages, or overlapping speech may receive high confidence scores despite being incorrect.
To guard against this, a small percentage of decisions should be pulled into full review at random regardless of model confidence. The goal is not to catch common mistakes. It is to ensure that systematic model errors cannot hide inside the high-confidence path for months without detection.
Calibration Sampling
Two reviewers evaluating the same ambiguous case will sometimes reach different conclusions. In a small team this difference surfaces quickly and is resolved through discussion. In a large distributed review operation processing thousands of cases per day, disagreement accumulates quietly.
Calibration sampling exists to detect this drift before it contaminates training data.
Each week, a small percentage of completed decisions should be re-evaluated by senior reviewers. The purpose is not to identify individual mistakes but to measure whether the review team is applying consistent labeling standards. Over time this process reveals whether interpretation guidelines are being applied uniformly across reviewers, locations, and shifts.
A common failure occurs when calibration checks are treated as an early-stage quality exercise. Teams often run calibration rigorously during the first few months of a project, observe healthy agreement rates, and gradually reduce the frequency of checks once workflows appear stable.
In practice, the opposite pattern is needed. Calibration drift tends to emerge after annotation pipelines scale and throughput increases. As more reviewers enter the system and task volumes expand, subtle interpretation differences compound across labeling cycles. For this reason, the cadence of calibration checks should increase as operational scale increases.
Clear Ownership Structures
When something goes wrong in a distributed review pipeline, there is a simple test of whether the accountability structure is functioning correctly: can the organization identify the reviewer responsible for a specific decision within minutes using standard tooling.
If locating that information requires manual investigation across logs or multiple internal systems, the accountability structure is already weaker than it appears.
This is not about assigning blame. It is about preserving the conditions that make reviewers take decisions seriously. When responsibility is diffused across a large team, individual reviewers rarely feel ownership over specific outcomes. Errors become systemic rather than traceable, making them much harder to correct.
Effective systems assign ownership at the decision category level rather than the workflow level. A reviewer responsible for a queue containing hundreds of mixed tasks primarily manages throughput. A reviewer responsible for a specific decision type across a defined dataset population develops pattern recognition, notices emerging anomalies, and escalates unusual cases with greater precision.
The difference between these two structures is subtle but significant. Ownership tied to decision categories encourages expertise and accountability to develop simultaneously.
Reviewer Specialization
Specialization allows reviewers to build deep familiarity with the types of cases they evaluate. A reviewer who has spent several months working exclusively with call center audio containing regional accents will make more reliable labeling decisions than a generalist rotating across multiple unrelated annotation tasks.
In speech and language datasets, this expertise becomes particularly valuable. Specialized reviewers develop a stronger ability to recognize dialect variation, interpret overlapping speech, distinguish background noise from linguistic content, and handle code-switching between languages. These are precisely the situations where annotation mistakes have the greatest downstream effect on model performance.
However, specialization introduces a different risk: boundary blindness. Reviewers become highly confident within their domain and may remain confident even when a case sits just outside the boundaries of their expertise.
In these edge situations, a specialized reviewer may make a decisive judgment where a generalist might have flagged uncertainty and escalated the case.
Specialization works best when paired with clearly defined escalation criteria. Reviewers should have explicit guidelines describing what falls outside their expertise and when cases must be transferred to another specialist. Without these boundaries, the most confident decisions reviewers make are sometimes the ones most likely to be incorrect.
Oversight Latency
Another structural challenge appears when oversight systems evolve more slowly than the models they supervise.
Machine learning systems frequently change through retraining cycles, dataset expansion, and architecture improvements. Each update can alter the types of errors the model produces. If reviewer guidelines and calibration standards remain static while model behavior evolves, reviewers may unknowingly apply outdated evaluation criteria to new error patterns.
Organizations that maintain oversight quality treat review standards as versioned components of the AI system. When a model is updated, calibration procedures and reviewer instructions are revisited alongside it. This ensures that the human oversight layer evolves at the same pace as the system it monitors.
Maintaining Oversight Integrity Over Time
All of these structures share a common characteristic: they degrade without active maintenance.
Tiered routing systems must be audited as model behavior changes. Calibration sampling must expand as annotation throughput increases. Ownership structures need to be revisited as teams grow and workflows become more complex. Specialization boundaries must be updated as datasets expand into new linguistic or environmental conditions.
Organizations that sustain oversight quality at scale treat these mechanisms as monitored systems rather than one-time design decisions. They measure them, audit them, and assign clear responsibility for keeping them operational.
That discipline is what separates human oversight that survives scale from human oversight that merely appears to.
A Practical Diagnostic for Enterprise AI Teams
Organizations operating human-in-the-loop systems can quickly assess the health of their review infrastructure using a small set of operational questions.
Has the average review time per case decreased during the last six months, while overall approval rates remained stable or increased? If both trends appear simultaneously, the system may already be experiencing queue saturation.
Can the organization produce an inter-reviewer agreement rate for edge cases using existing monitoring tools? If the answer requires building new infrastructure, calibration drift may already be affecting dataset quality.
If a harmful decision occurred recently, could the system identify the reviewer responsible within minutes? If not, accountability diffusion is likely present.
What is the approval rate for cases flagged by the model as low confidence, and how does that compare to the overall approval rate? Convergence between these numbers often indicates cognitive rubber stamping.
Has the scope of human review changed since system launch, and were those changes formally authorized through governance channels?
Answering these questions does not require speculation. The required signals already exist in most operational systems.
As a rough benchmark: in well-governed annotation pipelines observed across enterprise AI deployments, inter-reviewer agreement on edge cases typically sits between 78–85%. Agreement rates below 70% on a sustained basis are a reliable leading indicator that calibration drift is already affecting training data quality.
The Part of AI Systems That Receives the Least Engineering
Much of the public conversation around AI governance focuses on model architecture, benchmark performance, and algorithmic transparency.
Yet in most enterprise deployments, the long-term behavior of the system is shaped just as much by the structure of the human review layer.
Models are benchmarked carefully. Infrastructure is monitored continuously. Deployment pipelines are designed with redundancy and failover mechanisms.
Human oversight layers often evolve organically with far less structural planning.
When those layers degrade, the system does not simply make occasional incorrect decisions. It gradually begins learning from inconsistent or degraded data.
In many cases, the most significant risks in enterprise AI systems emerge not from the models themselves but from the human processes that generate the data used to train and validate those models.
Organizations that recognize this early treat human governance infrastructure with the same rigor applied to model engineering.
They measure it. They audit it. They design it deliberately before scale forces difficult compromises.
Closing Reflection
Human-in-the-loop systems remain one of the most important safeguards in modern AI deployments. They provide context, judgment, and accountability that automated systems cannot replicate.
But human oversight does not remain effective automatically as systems grow. Without careful architectural design, it gradually shifts from active governance to procedural confirmation.
Many organizations believe their systems maintain strong oversight because humans remain technically present in the workflow.
The more useful question is whether those humans still have the time, structure, and authority required to meaningfully influence the system’s behavior.
If the answer to that question becomes uncertain, the oversight architecture deserves the same attention and redesign that any critical component of an AI system would receive.
For teams building production AI systems, the quality of the human review layer often determines whether models improve steadily over time or quietly inherit the weaknesses of the processes surrounding them.
Understanding this shift requires looking at human-in-the-loop systems not as a single process but as an AI governance architecture that changes under scale pressure. The patterns described in this piece are drawn from FutureBeeAI's work designing and auditing human review infrastructure across enterprise AI deployments, and they appear with enough consistency to warrant a structured model.






