The hidden risk beneath every AI decision
Every day, AI makes decisions that used to belong squarely to humans. A loan application is approved in seconds, a fraud model freezes a transaction, a healthcare transcription engine interprets a clinician’s voice, or an in-car assistant acts on a driver’s rushed command in traffic. These systems quietly shape outcomes that affect safety, fairness, and access.
But here’s the uncomfortable part: even the teams deploying these systems often cannot answer the question a regulator, a customer, or an internal auditor will inevitably ask, “Why did the model do that?”
Consider a loan applicant who receives an unexpected denial. The model was trained on millions of historical records, yet nobody on the product or compliance team can pinpoint which pattern, data slice, or demographic imbalance influenced that decision. Was it the applicant’s profile? The dataset’s skew toward certain income brackets? Or a missing representation in past training data? No one can say for certain and in regulated sectors, uncertainty becomes a liability.
This is why data transparency in AI matters. Trust begins long before a model makes a prediction; it begins with the data that shaped its behavior. Once viewed through this lens, it becomes clear that organizations aren’t struggling because models are opaque; they’re struggling because their datasets are.
The shift in thinking from model explainability to data transparency
Before we examine how transparent data actually works, it helps to acknowledge a shift occurring across AI teams. For years, the industry leaned heavily on explainability tools to decode black boxes. These tools are useful; they help reveal how a model weighed its inputs, but they rarely reveal why the model arrived at a particular decision.
A healthcare AI team recently encountered this subtle gap. Their transcription model consistently misheard certain medical terms spoken by clinicians with specific regional accents. Explainability tools could highlight the misclassification patterns, but they couldn’t reveal the root cause: those accents were barely represented in the dataset. The issue wasn’t the model. It was the missing context in the training dataset.
This is the heart of the shift. Models learn the patterns, biases, and gaps in their training data. If datasets are undocumented, unbalanced, or poorly sourced, the model will reflect those blind spots, no matter how advanced the architecture or how polished the explainability layer.
Data transparency reframes trust from a reactive activity (“let’s explain what happened”) to a preventive one (“let’s understand what the model learned in the first place”). It gives organizations concrete, verifiable artifacts, provenance records, consent logs, demographic metadata, and version histories that reveal where the problem truly lies. This is the foundation ethical AI is built upon.
As we follow the thread from explainability to its root cause, the stakes become sharper in regulated sectors!
Why regulated sectors require deeper data transparency
Healthcare, BFSI, automotive, telecom, and public-sector systems all operate under heightened expectations. A healthcare transcription error can influence clinical documentation. A misheard automotive voice command during highway driving becomes a safety event. A BFSI dispute-assistance model misrouting a customer creates fairness and compliance risks. A public-service chatbot providing skewed guidance erodes institutional trust.
In these settings, regulators, auditors, and internal review boards do not want general assurances. They want evidence. They want to know:
- Where did the data come from?
- Under what rights was it collected?
- Who contributed it, and what demographic groups were represented?
- Which environmental or device conditions shaped it?
- Which dataset version trained the deployed model?
An opaque dataset becomes a deployment blocker. Not because anyone doubts the model’s sophistication, but because no one can verify its lineage, completeness, fairness, or risk exposure. When a telecom complaint-resolution model incorrectly prioritizes certain cases, or when an automotive assistant repeatedly misinterprets younger drivers in noisy environments, leaders need traceability, not guesswork.
This is why transparent data isn’t a “nice-to-have” in regulated industries. It’s the backbone of defensible, ethical, audit-ready AI.
With the stakes established, the natural next question becomes: what does transparent training data actually look like?
What transparent training data actually looks like
 Transparent data is not a slogan, it’s a system of documented, human-centered practices. It creates a verifiable chain connecting contributors → data collection → metadata → annotation → versioning → model training. When done well, it allows teams to trace a model’s behavior back to its origins.
Transparent data is not a slogan, it’s a system of documented, human-centered practices. It creates a verifiable chain connecting contributors → data collection → metadata → annotation → versioning → model training. When done well, it allows teams to trace a model’s behavior back to its origins.
Let’s break down what these transparency foundations look like in practice and notice how real-world examples naturally reveal why each one matters.
Provenance and lineage
True provenance tells the story behind every sample: when it was collected, under which scenario, using which device type, and from which contributor (represented through anonymized IDs). Lineage then connects those samples to dataset versions and model training cycles, making it possible to reconstruct exactly what influenced a given decision.
Consider a BFSI call-center ASR system that begins misclassifying dispute categories. If you cannot trace the problematic outputs back to specific dataset versions, you are left with speculation. But with documented timestamps, session logs, and version histories, teams can identify the exact training batch, understand what changed, and justify corrective action during audits. Provenance is what turns instinct into evidence. Platforms like Yugo make this kind of sample-level and version-level traceability operationally manageable.
Verifiable contributor consent and consent management
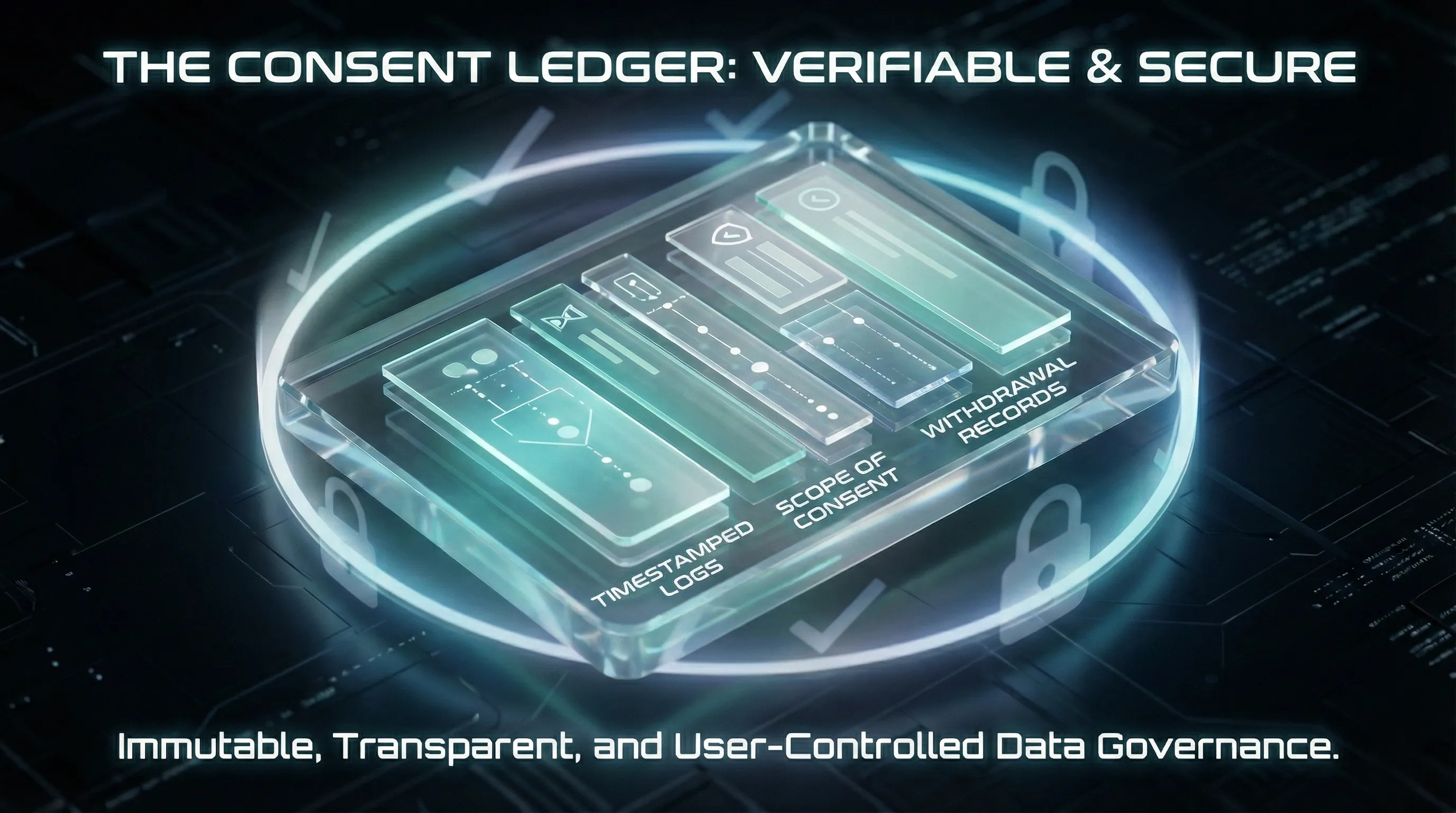 In ethical AI, consent cannot be implied, aggregated, or vaguely described. It must be verifiable. Because FutureBeeAI collects all data from real contributors through our global contributor community, and when scenarios are staged, they are clearly labeled as human-performed simulated and unscripted role-play, every dataset is anchored in explicit rights. Consent records in Yugo include timestamps, scope definitions, and withdrawal logs tied to contributor IDs. For regulated sectors, this clarity matters enormously.
In ethical AI, consent cannot be implied, aggregated, or vaguely described. It must be verifiable. Because FutureBeeAI collects all data from real contributors through our global contributor community, and when scenarios are staged, they are clearly labeled as human-performed simulated and unscripted role-play, every dataset is anchored in explicit rights. Consent records in Yugo include timestamps, scope definitions, and withdrawal logs tied to contributor IDs. For regulated sectors, this clarity matters enormously.
Telecom organizations, for example, increasingly face questions about the rights under which customer-voice datasets were collected. A dataset with uncertain consent lineage is a compliance liability. A dataset with verifiable consent is an asset.
Demographic metadata and multilingual dataset context
 Most fairness challenges originate not in the model, but in invisible gaps inside the dataset. Demographic metadata like age group, gender (where appropriate and lawful), region, and accent help teams see what is represented and what is missing.
Most fairness challenges originate not in the model, but in invisible gaps inside the dataset. Demographic metadata like age group, gender (where appropriate and lawful), region, and accent help teams see what is represented and what is missing.
A healthcare provider evaluating ASR performance across clinical specialties may discover that certain regional accents, speech rates, or linguistic patterns were never collected, creating disproportionate error rates. A BFSI fraud-detection system may show inconsistent confidence scores for customers from underrepresented geographies. Without demographic metadata, teams cannot diagnose the issue, and worse, they cannot prove mitigation to auditors.
Transparent demographic and linguistic metadata turns fairness into a measurable, improvable dimension of AI governance.
AI systems don’t fail randomly; they fail under specific conditions. Environmental metadata (quiet/noisy, indoor/outdoor) and device metadata (smartphone model, in-car mic type, headset) explain why.
Automotive teams know this well: an assistant trained mostly on quiet indoor recordings will behave unpredictably on a busy highway. Teams working with in-car speech datasets understand how critical environmental noise metadata becomes for real-world deployment. Telecom teams see similar patterns in call-routing models exposed to mixed microphone quality. And healthcare ASR engines trained on high-fidelity headsets may struggle with real ward acoustics.
Audio Annotation metadata, including annotator decisions, timestamps, and guideline versions that provides yet another layer of traceability. When labels drift or interpretations vary, teams can pinpoint exactly where the inconsistency emerged.
Transparent metadata is not busywork. It is the context that explains the “why” behind the model’s behavior.
Dataset versioning, audit trails, and traceable packaging
Any dataset used in production should have a visible evolution: version identifiers, change logs, added/removed samples, and updated annotation guidelines. Yugo supports timestamped audit-log capabilities and traceable lineage, allowing teams to reconstruct the precise dataset state that trained a deployed model.
This becomes indispensable during compliance inquiries. When a healthcare transcription output is questioned, or when a BFSI dispute-resolution assistant behaves unexpectedly, teams must answer not only “what the model did,” but also “what data the model saw.” Versioning provides that clarity.
When all these transparency pillars work together, organizations gain something rare in AI: the ability to tell a complete, defensible story from data → decision.
Once these foundations are understood, the question naturally arises: how does FutureBeeAI operationalize this in real datasets?
How FutureBeeAI enables dataset-level transparency
At FutureBeeAI, transparency is built into the architecture of how we collect, document, and deliver data. All data comes from real contributors in real environments. When simulations are required, such as healthcare intake role-play, telecom customer-service dialogues, or automotive command scenarios, they are always human-performed, unscripted, and clearly labeled to avoid confusion with synthetic data.
Yugo, our data-collection and governance platform, anchors this entire process. It maintains verifiable consent artifacts, contributor onboarding records, demographic and environmental metadata, and timestamped audit-log capabilities with traceable lineage. This means organizations can see not just what data they received, but how it came to be across versions, sessions, and quality checks.
Our work is designed to align with leading global data protection principles such as GDPR, HIPAA, BIPA, CCPA, DPDPA, and security frameworks like ISO 27001, as detailed in our policies and compliance documentation. Our internal stance is firm:
- No scraped data.
- No harmful tasks.
- Minimal, purpose-bound collection only.
Because transparency isn’t an afterthought. It is the structure that makes AI trustworthy.
After exploring how transparency works and how we build it, the final step is helping teams evaluate it in vendors they onboard.
Practical takeaway: A six-question dataset transparency checklist
Most AI companies cannot or should not collect all their data internally. They rely on data partners, which means the transparency of the data partner becomes the transparency of the final system.
Here is a practical framework teams can use when evaluating any dataset provider. Instead of a dry list, think of each question as a doorway: the way the vendor answers it reveals their philosophy, not just their process.
- Can you show me provenance details for a sample?
A transparent partner can immediately provide timestamps, contributor IDs anonymized, and environmental context. Hesitation indicates weak traceability.
2. How is contributor consent recorded and managed over time?
- Look for clear, verifiable artifacts: consent timestamps, scope, withdrawal logs, and rights definitions. Anything vague here becomes a compliance risk later.
3. What demographic and linguistic metadata accompanies the dataset?
- This reveals whether the vendor thinks about fairness, representativeness, and multilingual reality, or simply delivers volume.
4. What environmental and device attributes do you capture?
- If the dataset will power healthcare ASR, telecom routing, or automotive assistants, this context directly affects real-world performance.
5. How do you manage dataset versioning?
- A trustworthy vendor should provide change notes, version identifiers, and lineage artifacts that help teams reproduce model behavior.
6. What governance exists around annotation?
- Look for annotation logs, guideline versions, and QA processes. These determine consistency, especially in regulated domains.
Ask these six questions sincerely, and the strength of a data partner’s transparency will become self-evident.
A simple truth and the next step
Trustworthy AI begins long before a model trains, deploys, or makes a decision. It begins with knowing where the data came from, who contributed it, under what rights, and within which contexts. If teams cannot answer these questions, they cannot defend the system that stands on top of that data.
Data transparency isn’t a regulatory checkbox. It is a foundation for ethical, resilient, and explainable AI across healthcare, BFSI, automotive, telecom, and public-sector ecosystems. As you evaluate future datasets or data partners, start with the six questions above. The answers will reveal not only how the data was collected but also whether the AI system built on top of it can genuinely be trusted.
If you’re exploring transparent, auditable AI datasets, whether speech, text, image, or multimodal, our team at FutureBeeAI can help you understand what ethical, well-documented data should look like. If you have any specific dataset requirements or need guidance on selecting transparent training data, explore real-world implementations and begin a conversation grounded in clarity, traceability and responsible AI practice.






