The Unique Challenges of Call Center Data
In the world of ASR (Automatic Speech Recognition), we’ve become accustomed to models that perform well in controlled, clean environments. These models work with perfect, noise-free data, often designed for specific applications like transcription or voice assistants. But in a call center environment, things are far from ideal. The data is filled with background noise, dynamic conversations, and rapid emotional shifts. It’s anything but static.
While many ASR systems work well in other environments, the call center is a different breed entirely. It demands a more advanced and tailored approach, as the traditional clean and static datasets that ASR systems rely on don’t capture the full spectrum of real-world speech.
Call center data is not only full of technical jargon and customer-specific language, but also involves rapid emotional shifts, background noise, and overlapping speech. These elements make call center speech significantly more complex than other ASR environments. So why is call center speech data so different from other ASR models? And why can’t we rely on generic, pre-trained ASR models? Let’s dive into this and explore the real-world complexities of call center speech data, and why it demands a highly customized model to truly make sense of it.
Call Center Data vs Standard ASR Models
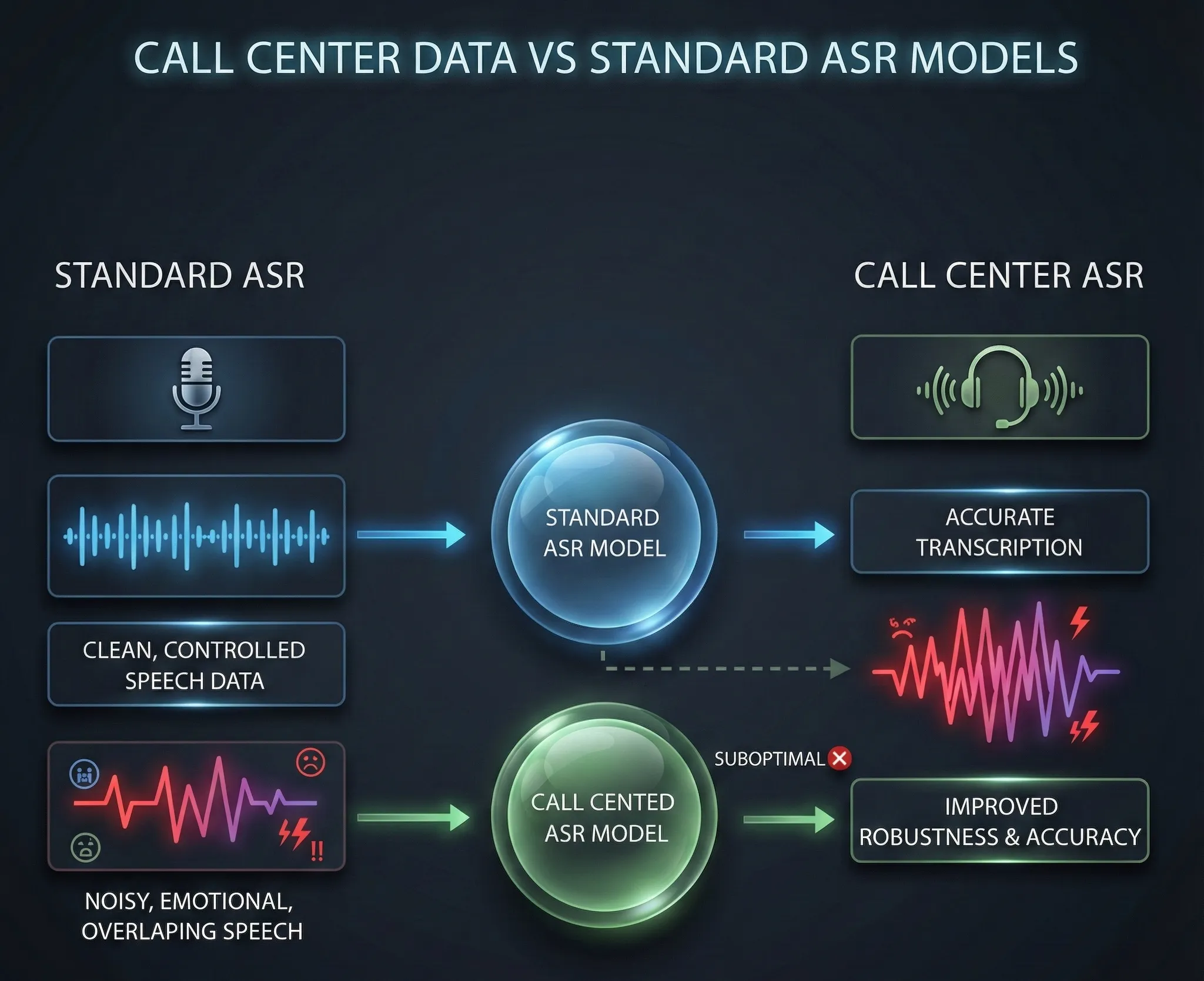
The Clean vs Chaotic Spectrum
A typical ASR model is trained on clean, controlled speech samples. Whether it's a voice assistant, transcription service or any other application that requires understanding speech in ideal conditions. These models are tuned for clarity and accuracy, using datasets that are mostly noise-free and predictable.
However, the call center environment is nothing like this. Here, the speech data is messy and unpredictable. Imagine a conversation where customers are switching topics mid-sentence, changing their tone or becoming emotional. Add to that the ambient noise from a bustling call center, office chatter, traffic sounds, keyboard typing and more. Standard ASR models are not built to handle this kind of dynamic variability.
The standard ASR system works well when there is little background noise, the speech is clear, and the vocabulary is basic. In a call center, however, these conditions rarely apply. The speech may include interruptions, rapid exchanges, and terms that vary based on the industry. Even the emotional tone plays a major role. Customers may speak with frustration, urgency or calmness and the model must understand these shifts in tone to transcribe accurately.
Now that we’ve explored why call center data presents unique challenges, let's look deeper into the specific elements of call center speech that make it such a complex task for ASR models to decode accurately.
The Complexity of Customer-Driven Speech Patterns
Changing Tone and Emotion
Call center conversations are not linear. A customer can go from asking a simple question to suddenly raising their voice in frustration, or shifting their speech pattern when they realize they’ve reached the wrong department. The emotional context of speech is vital for understanding intent and meaning, and ASR systems need to capture this if they are to be truly effective.
In a standard ASR model, tone shifts and emotional inflections are often overlooked. Frustrated customers speak differently than calm ones. They may speak more slowly, with greater pauses or raise their voice. The emotional subtext in these cases matters a lot more than just the words being spoken. A call center-specific ASR model must be trained not only to transcribe the words accurately but to also understand the intent behind those words. This is where emotionally intelligent models come in.
In customer service, this becomes even more critical. A calm, polite inquiry should be treated differently from a heated complaint. If a model doesn't recognize these emotional cues, it could lead to an incorrect understanding of the situation, resulting in an inadequate response from agents. Call centers need emotionally aware ASR systems that recognize frustration, urgency or satisfaction in a customer's voice.
Dynamic, Rapid Conversations
Another key difference between call center data and typical ASR data is the speed and interruptions. Customers don’t speak in neat sentences. They ask quick questions, interrupt the agent and sometimes speak over them. This leads to overlapping speech, which standard models often misinterpret. If the model isn’t trained to handle these situations, it can confuse the flow of conversation or fail to capture important information.
Consider how a conversation in a call center might go:
- Customer: “I’m having an issue with my bill, I don’t understand the charges and I really need to get this sorted out.”
- Agent: “I can help with that, let’s first look at your statement. What exactly is unclear?”
- Customer: “The last payment is missing, I already paid last week and this is frustrating.”
- Agent: “Okay, let’s check that payment. Could you confirm the date for me?”
Here, there are interjections and quick exchanges between speakers. An ASR system must be able to handle this dynamic flow of conversation, discerning who’s speaking and when while keeping track of key details. Something pre-trained models struggle to do in fast-paced environments like call centers.

Why Pre-Trained Models Won’t Cut It for Call Centers
The Limitation of Pre-Trained ASR Models
Most ASR models are trained on vast datasets that might include conversational speech, but they are rarely specific to the call center environment. These models are generally built for broader speech recognition tasks and are not fine-tuned for the intricacies of call center data.
While pre-trained models are great for standard speech applications, they are often too generalized for call centers, where domain-specific language and industry jargon are frequently used. A financial services call center, for example, will have unique terms that a generic model simply won’t recognize correctly.
Think about the healthcare industry, where terminology such as medication names, symptoms and doctor-patient communication is highly specialized. A pre-trained ASR system won’t know how to transcribe terms like “antihypertensive drugs” or “stent replacement”, and may misinterpret these words entirely.
Moreover, in call centers, the conversation is not just about clear speech. It’s about actionable data that impacts the customer experience. Pre-trained models, lacking the fine-tuning necessary for understanding customer-specific language, will fall short when it comes to providing the right level of service.
With this in mind, let’s talk about what needs to be done to create an ASR model that can handle the full spectrum of challenges unique to this environment.
ASR Model with High-Quality Call Center Data & Domain-Specific Customization
To develop a highly effective ASR (Automatic Speech Recognition) model for call centers, it’s essential to ensure that the data used for training is of the highest quality and tailored to the specific domains in which the call center operates. FutureBeeAI focuses on creating domain-specific datasets that represent the complexities of real-world customer-agent interactions across a wide range of industries.
Domain-Specific Data Requirements
Every industry has unique needs when it comes to call center data. A generic dataset is not sufficient to accurately capture the subtleties of each domain. At FutureBeeAI, we ensure that our datasets reflect the specific requirements of various industries, such as:
- Retail & E-Commerce: Customer inquiries about products, order statuses, returns and refunds are common. Retail and E-com calls often include product-related terminology and require specific jargon.
- Travel: Call center interactions may involve booking queries, flight status, hotel reservations, and travel itineraries, all requiring specific industry-related vocabulary.
- Delivery & Logistics: Calls often center around tracking, delivery status, scheduling, and order updates, necessitating a focus on logistics-specific terms and processes.
- Real Estate: These calls may include property inquiries, lease details, viewing appointments, and market trends, with a strong emphasis on terminology related to properties and real estate transactions.
- Telecom: Calls in the telecom sector focus on service issues, new plan inquiries, billing, and technical support, each requiring a rich set of telecom-related language.
- BFSI (Banking, Financial Services, and Insurance): Call center interactions in the BFSI sector often involve topics such as account inquiries, loan applications, insurance claims, credit card services, and financial advice. These calls require precise handling of financial terminology and sensitive information.
- General: This category includes a broad range of industries, and while the data is more generalized, it still requires domain-relevant customization.
Each of these domains has unique terminology and conversation types, so ensuring that the data used to train ASR models reflects the specific language and context of each industry is crucial for creating accurate and reliable models.
Diverse Call Types
In call centers, the types of calls vary greatly, and each type requires specific data handling. For a robust ASR model, it is essential to include:
- Inbound Calls: These are calls initiated by customers seeking assistance, making inquiries, or reporting issues.
- Outbound Calls: These calls are made by agents, often for follow-ups, surveys, or sales calls.
- Edge Cases: While these calls may not be frequent, they often include complex scenarios, such as emergency calls or escalations, and must be included for a comprehensive dataset.
By including a balance of common and edge cases, we ensure that the model is capable of handling a wide variety of situations, whether common or rare.
Call Duration and Emotional Variability
Customer-agent interactions are varied, both in terms of call duration and the emotional tone of the conversation. Call durations can range from short, quick inquiries to long, detailed troubleshooting sessions. Additionally, customers may display a wide range of emotions, from frustration to calmness or satisfaction. These emotional variations are critical to understanding the context and sentiment of the conversation.
Comprehensive Data Capture for Real-World Scenarios
To ensure the model performs well under real-world conditions, the dataset must account for background noise, accents, and demographic diversity. While we don't rely on real-world data, we simulate real-world scenarios that capture:
- Multiple Speaker Variations: Distinguishing between customer and agent voices.
- Noise Simulation: Including both clean audio and noisy environments, such as office chatter or outdoor sounds.
Real-Time and Rapid Conversation Shifts
Call center conversations don’t happen in a linear fashion. Customers interrupt agents, switch topics rapidly and speak over each other. For ASR systems to truly perform well, they must be able to recognize multiple speakers, manage interruptions, and adapt to rapid conversation shifts. Our datasets are designed to include examples of speech overlap and interruptions, ensuring that the models can accurately transcribe conversations as they happen in real-time, without losing key information. We also ensure that turn-taking and speaker identification are reflected accurately in the data so that models can identify and separate customer and agent dialogues with ease.
By ensuring a diverse dataset that accurately represents various industries and real-world conditions, FutureBeeAI ensures that its ASR models can handle customer interactions across a broad range of sectors and situations.
Drawbacks of Real-World Data and the Advantages of Simulated Data
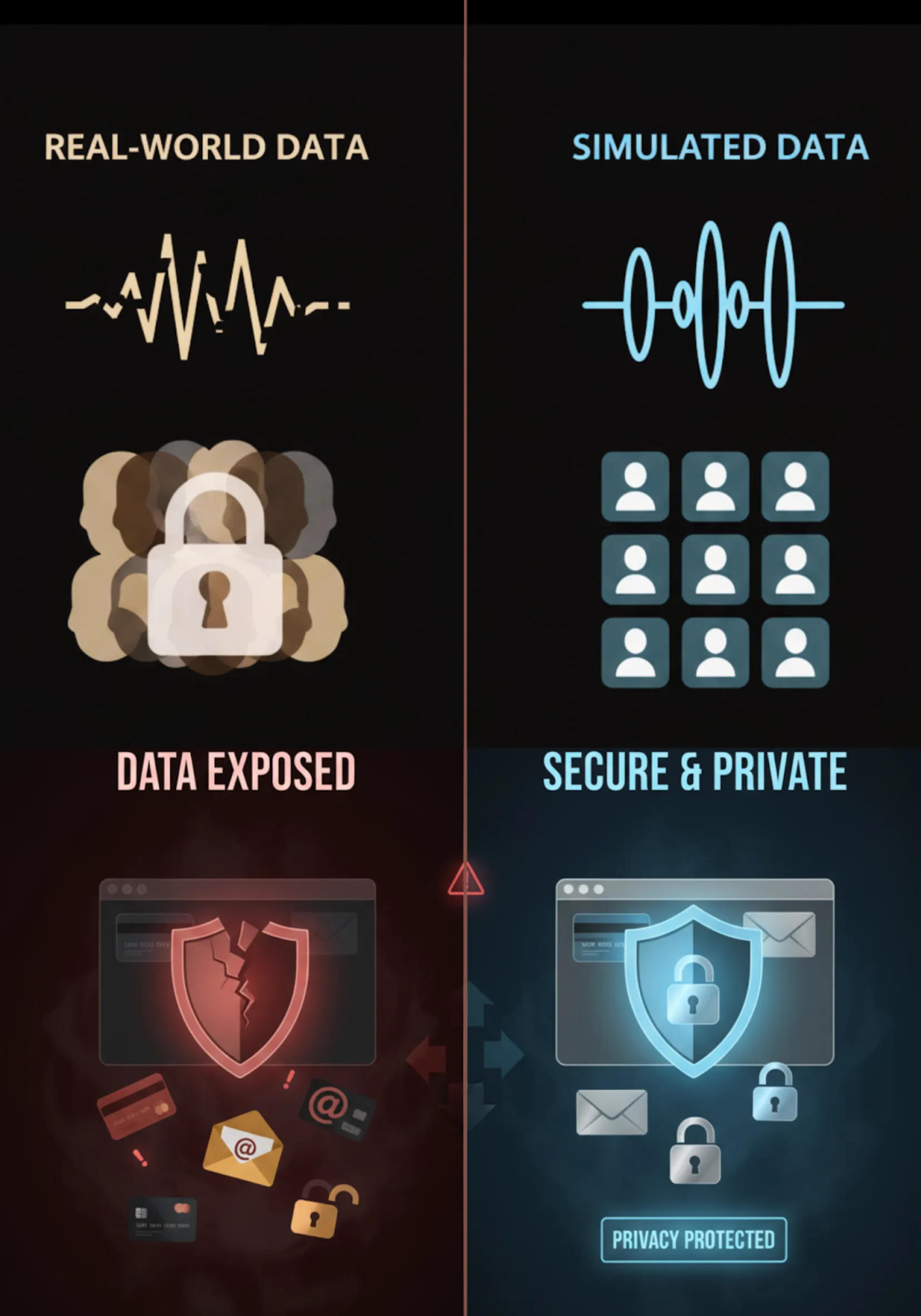 When developing ASR systems, real-world data is often considered the go-to choice for training models. However, real-world data comes with a number of drawbacks that can significantly impact model accuracy and performance.
When developing ASR systems, real-world data is often considered the go-to choice for training models. However, real-world data comes with a number of drawbacks that can significantly impact model accuracy and performance.
- Privacy Concerns: Real-world data often contains Personally Identifiable Information (PII), which presents privacy risks and complicates compliance with strict regulations. Without obtaining explicit consent from all individuals involved in the recordings, real-world data raises legal and ethical concerns.
- Lack of Diversity: One of the biggest limitations of real-world data is that it doesn't guarantee data diversity. There’s no control over factors like accents, languages, or demographics, which means certain customer profiles or edge cases might not be adequately represented in the data. This can lead to models that are biased or unable to handle a diverse range of real-world scenarios.
- Low-Quality Audio: Real-world recordings often suffer from poor audio quality, including background noise, static or distorted audio. This can make the data irrelevant or inconsistent, which negatively impacts the training process and compromises model performance.
In contrast, simulated data offers a clear solution to these challenges, providing higher control, better quality, and privacy-compliant datasets. With FutureBeeAI's approach, we overcome the limitations of real-world data while still capturing the richness and complexity of real-world scenarios.
Simulated Data vs. Real and Synthetic Data
While real-world data presents challenges, simulated data provides an efficient, effective alternative. Simulated data ensures better control over the training process, offering several clear advantages when compared to both real and synthetic data.
- Control and Quality: Simulated data allows for precision in creating high-quality, noise-free recordings while still reflecting the complexities of real-world environments. By generating data that closely mimics real customer-agent interactions, we ensure that the models are exposed to both common scenarios and edge cases that might otherwise be underrepresented in real-world data.
- Privacy and Compliance: Unlike real-world data, simulated data avoids privacy concerns by eliminating the inclusion of sensitive information. It provides a compliant, ethical data solution that maintains the integrity and security of the dataset.
- Diversity: Simulated data can be customized to include a broad range of accents, languages and emotional tones, ensuring a highly diverse dataset. This enables the model to generalize better across varied user profiles, enhancing its ability to adapt to a wide range of customer interactions.
- Realistic yet Controlled: While synthetic data often lacks the authenticity of real-world interactions, simulated data offers the best of both worlds, capturing realistic scenarios while maintaining quality control.
These benefits make simulated data the clear choice for training ASR models, offering superior flexibility, higher accuracy and the diversity required to ensure reliable, real-world performance.
The Role of Annotation and Transcription in Data Quality
 To further enhance the effectiveness of simulated data, it is crucial to annotate and transcribe the data accurately. The annotation process adds an extra layer of clarity and structure, ensuring that the data is not only usable but also maximizes its value in training ASR models.
To further enhance the effectiveness of simulated data, it is crucial to annotate and transcribe the data accurately. The annotation process adds an extra layer of clarity and structure, ensuring that the data is not only usable but also maximizes its value in training ASR models.
Data Collection Process
At FutureBeeAI, our data collection process is meticulously designed to ensure high-quality, domain-specific data:
- Domain Experts: We collaborate with domain experts and native language speakers to record the data. While the recordings are unscripted, these experts are provided with SOPs (Standard Operating Procedures) to guide the recording process, ensuring the conversations remain natural yet diverse. The topics for the conversations are provided, but the dialogue is allowed to flow freely, reflecting the true nature of customer-agent interactions.
- Recording Quality Assurance (QA): We employ the Yugo platform for continuous monitoring of audio quality. This ensures that poor-quality recordings, such as those with excessive background noise or audio distortions, are flagged before they are added to the dataset.
Transcription and Annotation
Once the recordings are made, the data undergoes transcription and annotation to ensure it is accurate and valuable for ASR model training:
- Transcription: The audio recordings are transcribed, ensuring that the spoken words are captured accurately. This is crucial for building an effective ASR model.
- Annotation: We enrich the dataset by adding several critical tags:
○ PII Tags for privacy protection.
○ Speaker Labels to distinguish between customer and agent, including gender.
○ Foreign Language Tags to identify when multiple languages are spoken.
○ Filler Words, Number Tags and Emotion Tags to capture the subtleties of conversation.
○ Additional details like music, laughs and technical noise help replicate real-world conditions.
Why Annotation and Transcription Matter
The inclusion of detailed annotation tags is what sets our simulated data apart. These annotations enable the ASR model to not only understand what is being said but also to capture context, whether the speaker is frustrated, calm or speaking in a noisy environment. This level of detail ensures higher accuracy and enables the model to adapt to various real-world conditions, such as fluctuating emotions or background noise.
Conclusion
In conclusion, the challenges presented by real-world data such as privacy concerns, low-quality audio and lack of diversity, make it less than ideal for training effective ASR models. On the other hand, simulated data offers a superior solution by providing high-quality, diverse and privacy-compliant datasets. With the additional benefit of detailed annotation and transcription processes, FutureBeeAI creates datasets that capture the complexities of real-world interactions while maintaining control over data quality.

By utilizing domain-specific expertise, advanced QA processes and precise annotation, we ensure that our simulated data is ready to deliver the highest accuracy and adaptability, making it the ideal choice for modern call center applications. As we continue to innovate, FutureBeeAI remains committed to developing ASR solutions that drive better customer satisfaction and more efficient business operations worldwide.






