If you already understand vision-language models, the name almost explains itself. Almost.
A Vision-Language-Action model (VLA) is a multimodal AI architecture that takes visual input and natural language instructions and outputs physical actions, motor commands a robot can execute directly in the real world. That one-sentence definition is accurate. But it undersells how much changes when you move from producing language to producing action and why that difference shapes everything about how these systems are built and trained.
The teams building Physical AI on VLA foundations are discovering that the architecture is available, the open-source models exist and the hard part is something else entirely.
From Vision-Language to Vision-Language-Action - What the "A" Actually Adds

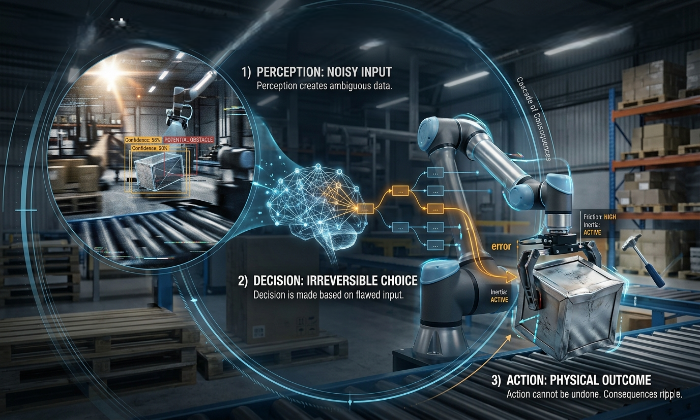
A vision-language model takes an image and a text prompt and produces text. Its output lives in token space interpretable, correctable, regeneratable. If the model misreads a scene, you ask again. If the response is wrong, you try a different prompt. The failure mode is soft.
A VLA takes an image and a text instruction and produces physical actions. Motor commands. Gripper forces. Trajectory coordinates. The output doesn't stay on a screen, it moves hardware. A wrong answer from a language model costs a few tokens. A wrong motor command from a VLA costs, at minimum, a failed task. In safety-critical deployments, it costs more than that.
That difference sounds obvious when stated plainly. Its architectural implications took years to work through.
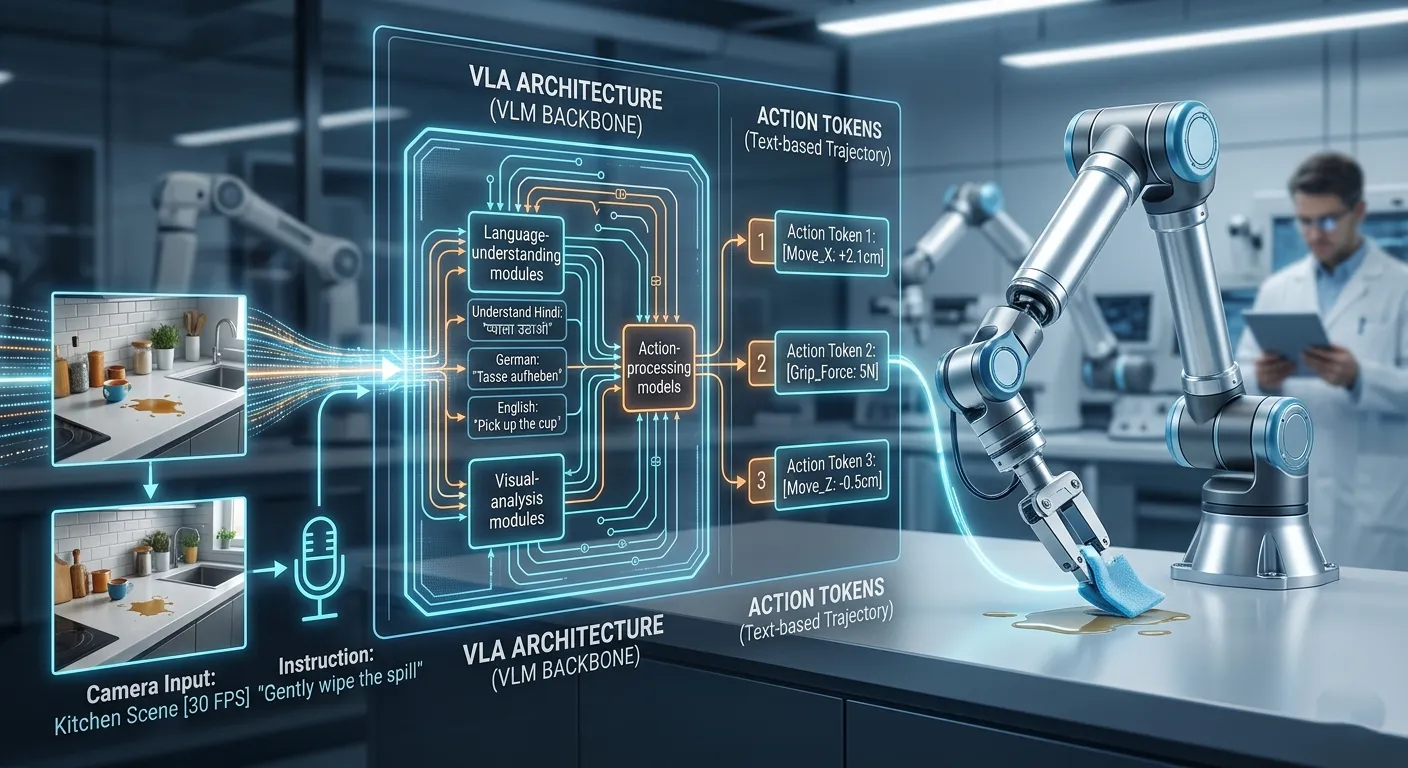
The foundational move came with RT-2 from Google DeepMind in 2023. The paper solved the bridging problem by representing physical actions as text tokens, forcing robot trajectory data into the same format as language data so both could be used to train the same model simultaneously. This is action tokenization: the technique that made it possible to leverage internet-scale vision-language pre-training for a system that needed to output motor commands. Before RT-2, robotics and language AI had different architectures, different training pipelines and essentially different research communities. Action tokenization made the language AI toolchain available to physical agents.
The architectures that followed built on this foundation in different ways. Open VLA, a 7B-parameter open-source model trained on 9,70,000 robot demonstration episodes from the Open X-Embodiment dataset, showed that the approach generalized across robot types and tasks. Physical Intelligence's π0 added continuous action outputs via flow matching, allowing the model to produce smooth, high-frequency motor commands rather than discrete token predictions, which matters for dexterous manipulation. NVIDIA's GR00T N1 and Google DeepMind's Gemini Robotics pushed the architecture further with dual-system designs: a large VLM backbone for scene understanding and language comprehension feeding into a faster visuomotor policy for low-level action execution.
The reader who came in asking "how is a VLA different from a VLM" now has the answer: the same general architecture, extended by action tokenization to handle a fundamentally different output type, with everything downstream shaped by that extension. What "downstream" means in practice is where it gets interesting.
To go deeper on how Physical AI systems learn to perceive, decide, and act, see: The Three Things Every Physical AI System Needs to Learn this.
The Data Dependency Language AI Never Had
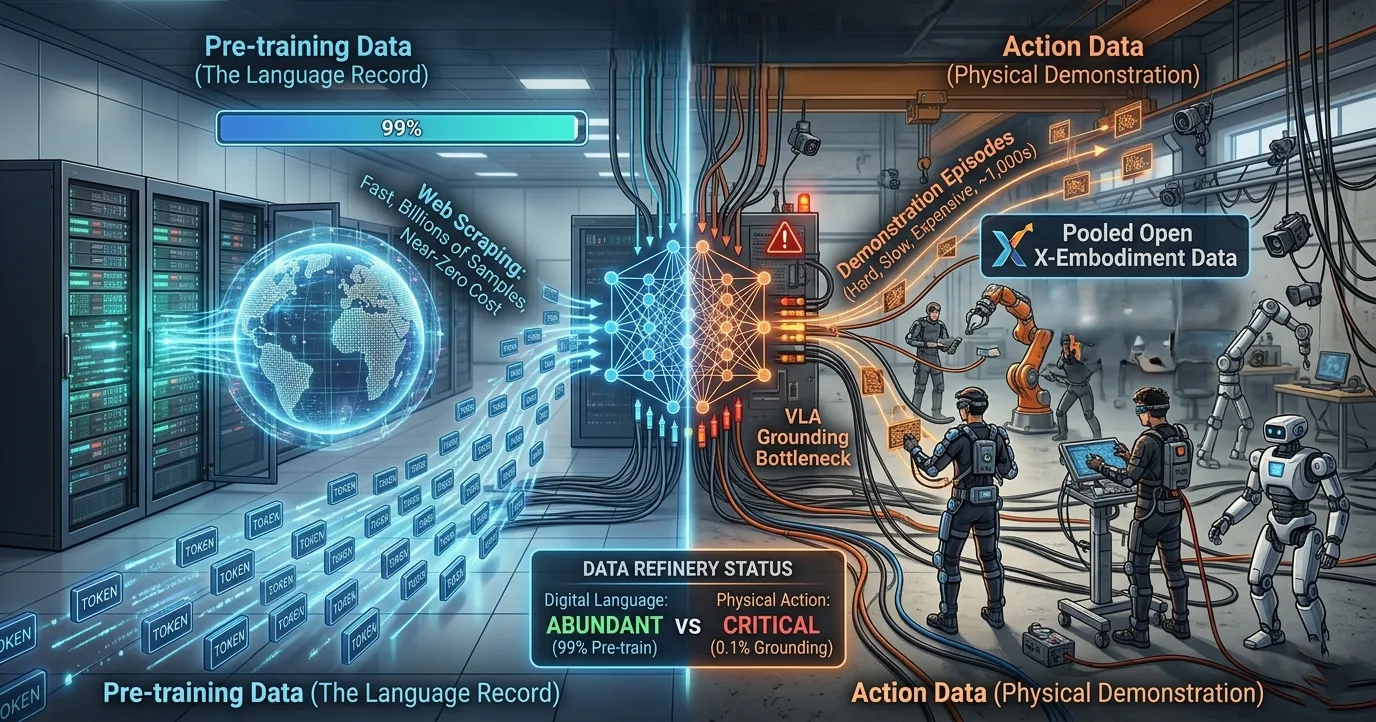
Language models learned from the accumulated record of human thought. Hundreds of billions of tokens, books, articles, code, conversations scraped from sources that existed long before the models did. The data problem for language AI was curation and quality. The data existed. It just needed to be found and filtered.
VLAs have to learn from the accumulated record of human physical demonstration data. That record barely exists.
The Open X-Embodiment dataset is the largest collaborative effort to pool VLA training data, assembled by 22 research institutions across robot platforms. It contains approximately 970,000 demonstration episodes. Open VLA was trained on this. To put the scale in perspective: GPT-scale language models train on datasets measured in hundreds of billions of tokens. The entire Open X-Embodiment dataset, one of the most significant data pooling efforts in robotics research, would be a rounding error in that comparison.
This is not a temporary gap that more computers will close. Robot demonstration data cannot be scraped from the internet. Each episode requires hardware running, a human demonstrating, sensors capturing and a data pipeline processing the result. The data collection is physical, slow and expensive in ways that text collection is not. A VLA being fine-tuned on a new task typically needs 50 to 200 demonstration episodes to perform reliably. Adapting a model to a new robot embodiment requires significantly more. Training a foundation model from scratch requires the kind of coordinated multi-institution effort that produced Open X-Embodiment.
What this means for teams building with VLAs: the foundation models are available. The architecture is not the bottleneck. The demonstration data, its volume, its diversity, its quality, and how well it reflects the environment where the system will actually operate is where most Physical AI projects either succeed or stall.
In FBAI's work supporting VLA development, the teams that hit walls soonest are rarely the ones struggling with model architecture. They're the ones who underestimated what producing quality demonstration data at the required volume and diversity actually involves, collection infrastructure, hardware synchronization, annotation schema design and the specific environmental conditions the deployment system will encounter. The data pipeline is where Physical AI projects stall, not the model selection.
This data dependency has one dimension that almost every team building VLAs under plans for. It isn't volume. It's language.
The Instruction Language Gap Most VLA Teams Don't See Coming
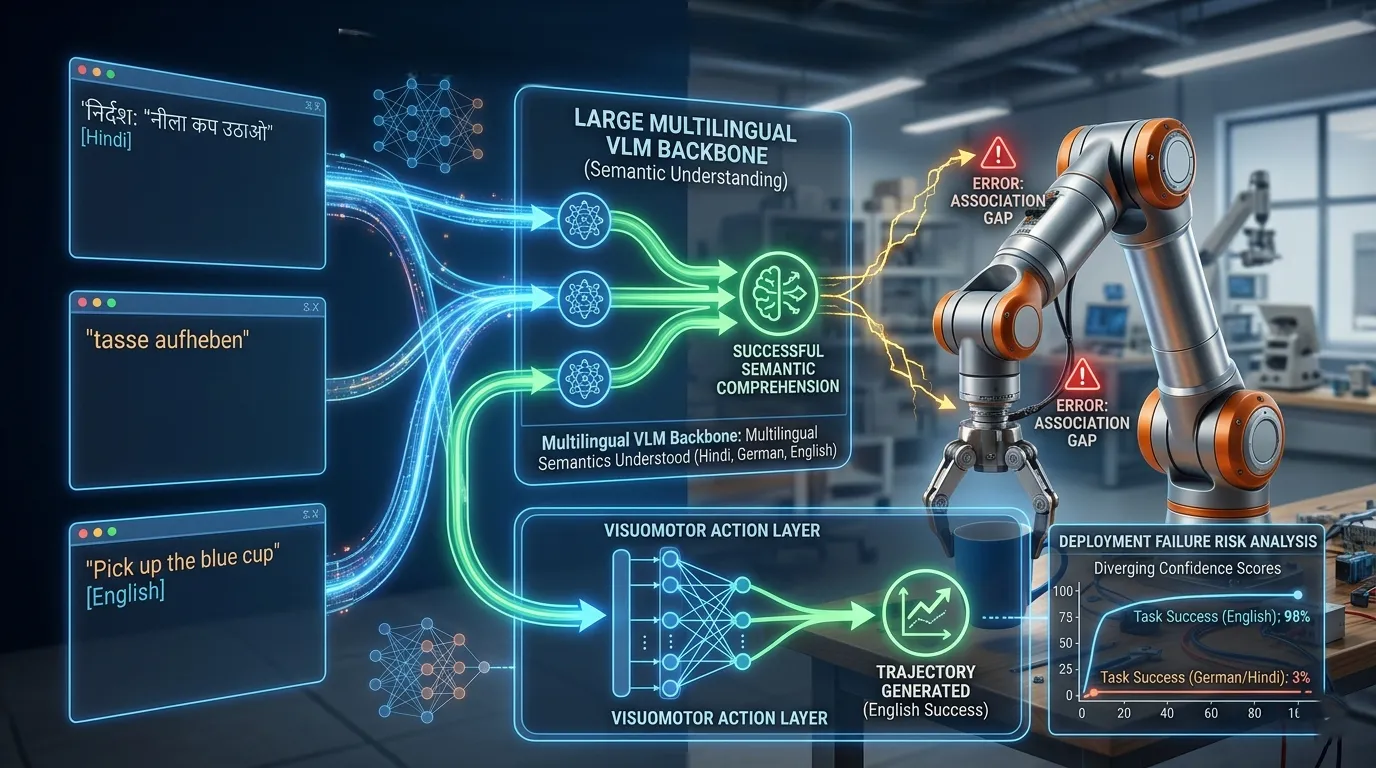
VLAs receive natural language instructions. When a team builds on a multilingual VLM backbone which most modern VLAs do, the assumption is usually that the language capability transfers. If the backbone understands Hindi, the VLA will follow Hindi instructions. This reasoning sounds sound. It usually isn't.
Here is why. A VLA learns action-language pairings from demonstration data. During training, the model is seeing thousands of episodes where a human performs a physical task while that task is described in natural language. The model learns to associate specific language patterns with specific physical actions. If every demonstration episode was conducted with English-language instructions which is typical, because most data collection teams operate in English, the model's learned pairing between "pick up the cup" and the corresponding motor command is tight. Its learned pairing between "tasse aufheben" and the same command is either weak or absent.
The VLM backbone may understand both sentences with equal fluency. The VLA does not act on them with equal reliability. The backbone knowledge and the action-language pairing are separate learned capabilities. Inheriting a multilingual VLM does not automatically produce a multilingual VLA.
For enterprises deploying Physical AI in multilingual operating environments, manufacturing facilities where operators speak regional languages, logistics hubs with mixed workforces, healthcare robotics in non-English-speaking markets, this is a real problem that surfaces at deployment, not at training. By that point, it traces back to a data collection decision made early in the project.
The language of instruction in the demonstration data is a design decision. In most VLA development pipelines, it is treated as a default.
FBAI has observed this pattern across physical AI data collection projects: teams inherit a multilingual VLM backbone and collect demonstration data in English because it is operationally simpler. The instruction-action pairing ends up language-narrow even when the VLM foundation is language-broad. When the system deploys in a multilingual environment, instruction-following degrades in ways that initially look like model failure but trace directly to a data collection decision from early in the project.
What This Means If You're Building with VLAs
VLAs are the architecture Physical AI is converging on. They generalize across tasks and embodiments in ways that task-specific programmed robotics cannot. The open-source models like Open VLA, π0 and others make the architecture accessible to teams that aren't Google DeepMind or Physical Intelligence.
What those models do not provide is the demonstration data that makes VLAs work in a specific deployment context. Task-specific fine-tuning needs demonstration episodes that reflect the actual task, the actual environment and the actual operating conditions. For multilingual deployments, it also needs instruction data in the languages the system will receive.
That is the practical challenge VLA development actually runs into. Not the architecture. The data.
FBAI designs physical AI training data for VLA development like multimodal demonstration collection, real-world condition diversity, hardware-synchronized capture pipelines and language-diverse instruction data across 100+ locales. For teams working on VLA fine-tuning or foundation model development, the right starting point is the demonstration data strategy, not the model selection. Talk to FBAI about your VLA data pipeline.
FAQ Section
Q. Can synthetic data replace physical robot demonstrations for training a VLA?
A. Partially, but not fully. Synthetic data generated in simulation can expand training volume and cover rare scenarios that are impractical to collect in the real world. NVIDIA's physical AI data infrastructure is built partly around this. But simulation-generated data doesn't replace real demonstration data, it supplements it. VLAs trained exclusively on synthetic data consistently show degraded performance in real environments because simulated physics, textures, and human movement don't fully replicate what the system encounters at deployment. Most production VLA pipelines combine synthetic data for coverage with real demonstrations for grounding.
Q. How does a VLA generalize to tasks it wasn't explicitly trained on?
A. Generalization in VLAs comes primarily from the VLM backbone, which was pre-trained on internet-scale vision-language data and carries broad semantic understanding. When a VLA receives an instruction for a task not seen in its robot demonstration data, it draws on the VLM's understanding of the instruction and the visual scene to generate approximate action sequences. The quality of that generalization degrades with task distance from the training distribution. π0 achieved 40–60% zero-shot success on related but unseen tasks like meaningful generalization, but far from the reliability of trained tasks.
Q. How much training data does a VLA need?
A. It depends heavily on what you're trying to do. Fine-tuning an existing VLA foundation model for a single new task on a specific robot typically requires 50–200 demonstration episodes. Adapting a model to a new robot embodiment requires substantially more, often several thousand episodes. Training a foundation model from scratch, like Open VLA, requires datasets in the hundreds of thousands of episodes across diverse robot platforms. The 970,000-episode Open X-Embodiment dataset, assembled by 22 research institutions, is roughly what full foundation model training demands.
Q. What does action tokenization look like in practice?
A.RT-2, the model that introduced action tokenization, discretized continuous robot movements into numerical bins and represented those bin indices as text tokens, the same format as language tokens. A command like "move arm 3.2cm left" became a sequence of numbers formatted as text, allowing the same transformer training objective used for language prediction to apply to robot control. This let the model be co-fine-tuned on both web-scale vision-language data and robot trajectory data simultaneously. Later VLAs moved away from discrete tokenization toward continuous action representations using flow matching, which produces smoother, higher-frequency motor commands than discrete token sequences allow.