Physical AI
Training Data
Why Physical AI Fails in the Real World And What the Training Data Gets Wrong
Most physical AI systems pass testing and fail in deployment. The reason is almost never the model, here's the five-part data diagnosis.
Physical AI
Training Data
Most physical AI systems pass testing and fail in deployment. The reason is almost never the model, here's the five-part data diagnosis.

Consider a team that ships a robot. The robot worked. In testing it completed tasks at 85%, solid enough to ship, strong enough to justify the investment. Three weeks into real deployment on a production floor, that number sat at 59% and nobody on the team could explain why.
They had done everything the playbook recommends. Diversified the training dataset. Added domain randomization to the simulation. Ran real-world fine-tuning sessions between testing cycles. Each round of fixes helped briefly, then the numbers slid back.
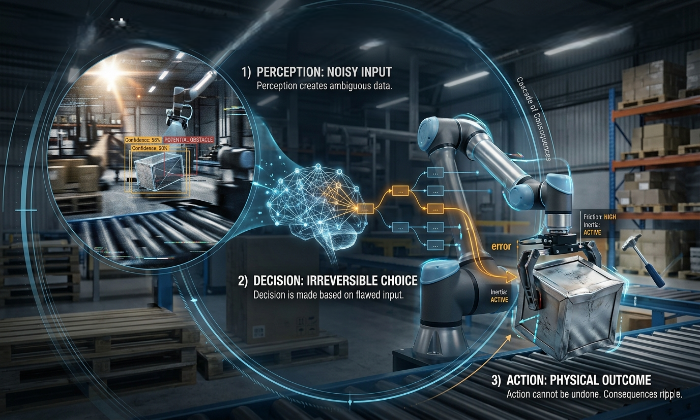
Physical AI systems trained on carefully prepared data fail in real deployment when there is a gap between the conditions under which training data was collected and the conditions in which the system actually operates. This gap is distinct from the simulation-to-reality problem the industry has spent years solving, it affects real-world data not just synthetic training and it has five specific forms each with a different cause and a different fix.
The model wasn't the problem. The pipeline showed no anomalies. The hardware performed to spec. What was wrong was the data not its volume, not its annotation quality in the standard sense, but the specific assumptions baked into when and where and how it was collected.

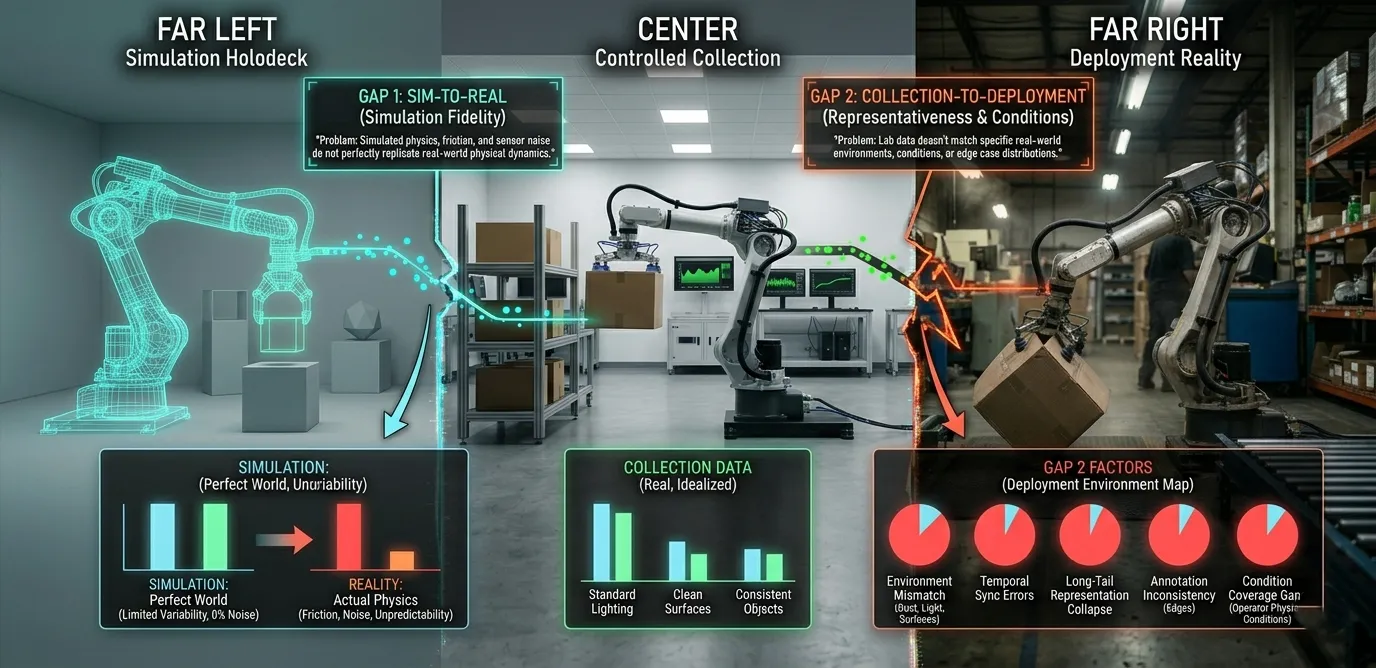
The dominant narrative in Physical AI development has framed the core data problem as the sim-to-real gap: the performance difference between a system trained in simulation and that same system running on physical hardware. Simulated physics doesn't perfectly replicate real-world friction, sensor noise, material behavior, or the unpredictability of actual human presence. Models trained in virtual environments encounter physical reality in deployment and fail at the discrepancy.
The industry's response has been substantial. Better simulation engines. Domain randomization like varying lighting, textures and mass parameters during training so models learn to generalize across physical variability. Synthetic data at scale, with billions of training examples generated using physically accurate rendering. Real-world fine-tuning cycles layered on top of simulation-trained policies. NVIDIA's Physical AI Data Factory represents the current state of this approach: a full pipeline for transforming limited real-world inputs into large synthetic datasets that include rare edge cases and long-tail scenarios that are expensive to capture in the real world.
This is genuine progress on a real problem. It describes Gap 1.
Gap 2 is different. It is the distance between the conditions in which training data was collected and the conditions in which the physical AI system actually operates. Not a simulation fidelity problem, a representativeness problem. The data is real. The physics are real. But the data was collected somewhere specific, under specific conditions, by specific people. The deployment environment is somewhere else entirely.
A synthetic dataset with perfect physics, generated in a virtual US warehouse with standardized lighting and predictable object types, does not help a robot navigating a dusty distribution center in Chennai where the lighting varies by bay, the floor surface changes between sections, and the object dimensions don't match any published dataset. The synthetic pipeline closed Gap 1. Gap 2 was never touched.
This is why teams following the current best-practice playbook have to diversify, randomize, generate synthetic data and fine-tune can still see systematic deployment failure. They are solving Gap 1 while experiencing Gap 2. The two look similar from the outside: the model doesn't perform as well in real conditions as it did in testing. The causes are different and the fixes don't overlap.
There are five distinct forms Gap 2 takes in production. Knowing which one is causing a specific failure matters, because treating them as the same problem or as the same problem as sim-to-real means intervening in the wrong place.
To understand how perception, decision, and action form a consequence chain in Physical AI, see: The Three Things Every Physical AI System Needs to Learn.
None of these failure modes are invisible in retrospect. All of them are invisible before deployment, which is why they keep appearing in systems that passed thorough testing. Each one traces back to a specific decision made during data collection and not a model flaw, not an architecture choice.
The most common Gap 2 failure is the simplest to describe: the system was never trained in the environment it was deployed into.
Data collection happens somewhere. Usually somewhere accessible and controllable like in a lab, a studio built to approximate a target facility, a partner site that agreed to host the collection team. These environments have characteristics that get baked into the training data whether anyone intended it: lighting range, floor surface, object density, spatial layout, ambient noise profile, ceiling height. The model learns to operate under these conditions. They become its implicit definition of normal.
Deployment environments have different characteristics. The robot trained in a clean, well-lit mock warehouse encounters a real facility where half the overhead lighting runs at reduced power, the floor transitions between concrete and rubber matting, and objects arrive in orientations the mock environment never staged. The perception model calibrated to operate under specific conditions encounters conditions it has never processed.
The failure shows inconsistency rather than breakdown: the system performs well in some areas and poorly in others, or works acceptably on one shift and degrades on another. Teams spend weeks adjusting model parameters before realizing the problem is environmental, not algorithmic.

Physical AI requires multimodal data like video frames, depth sensor readings, force measurements and action labels captured simultaneously and aligned precisely in time. The relationship between what a system perceives and what action it should take is learned from this alignment. A robotic arm learning to grasp objects builds its perception-action mapping from thousands of paired examples: this visual configuration, this motor command.
The alignment requirement is strict. A few milliseconds of offset between a visual frame and its corresponding action label teaches the system the wrong relationship that the motor command appropriate for one visual state belongs to a slightly different one. Research on multimodal robotics data has documented that timing misalignments of this magnitude are sufficient to cause robots to miss targets consistently. The error is small in any single training example and produces no signal in standard training metrics. Across thousands of examples, the system learns a subtly mis calibrated perception-action mapping.
In deployment, this appears as degraded action accuracy that seems random: the system performs isolated tasks correctly but loses precision on sequential actions, where small errors compound. Adjusting model parameters finds nothing. The issue is in the data pipeline, upstream of training.
In FutureBeeAI's physical AI data work, temporal synchronization errors are among the hardest failure modes to diagnose because they're introduced at the data capture stage, often between separate recording devices that weren't hardware-synced and there's no signal in standard training metrics that the problem exists until deployment accuracy is specifically analyzed across sequential action chains rather than isolated task completions. Teams that catch this before training, run synchronization verification as a mandatory QA check before the dataset leaves the collection pipeline.

Training datasets are built to be representative which, in practice, means they reflect the frequency of events in a controlled collection environment, not the distribution of difficulty in real deployment.
In a carefully managed data collection, edge cases appear at roughly their natural frequency in the collection environment: unusual object orientations, unexpected spatial configurations, rare environmental states. That frequency is low. A thorough collection might be 92% common-case examples and 8% edge cases. The model trains on this distribution and achieves strong performance on common cases.
In production, edge cases are not 8% of what causes failure. They are the majority of it. Common cases resolve cleanly. The package that arrived upside-down, the object partially occluded by another, the aisle obstructed in a way the map doesn't reflect, these are where systems break down. The training distribution didn't match the failure distribution. Collecting more data the same way makes this worse: it adds more common-case examples to a distribution already over-weighted toward them.
The fix isn't volume. It's deliberately sampling hard cases at a frequency indexed to their deployment failure rate, not their collection frequency. That requires mapping which cases are hard in the specific deployment environment before collection begins and not after the first failure cycle.
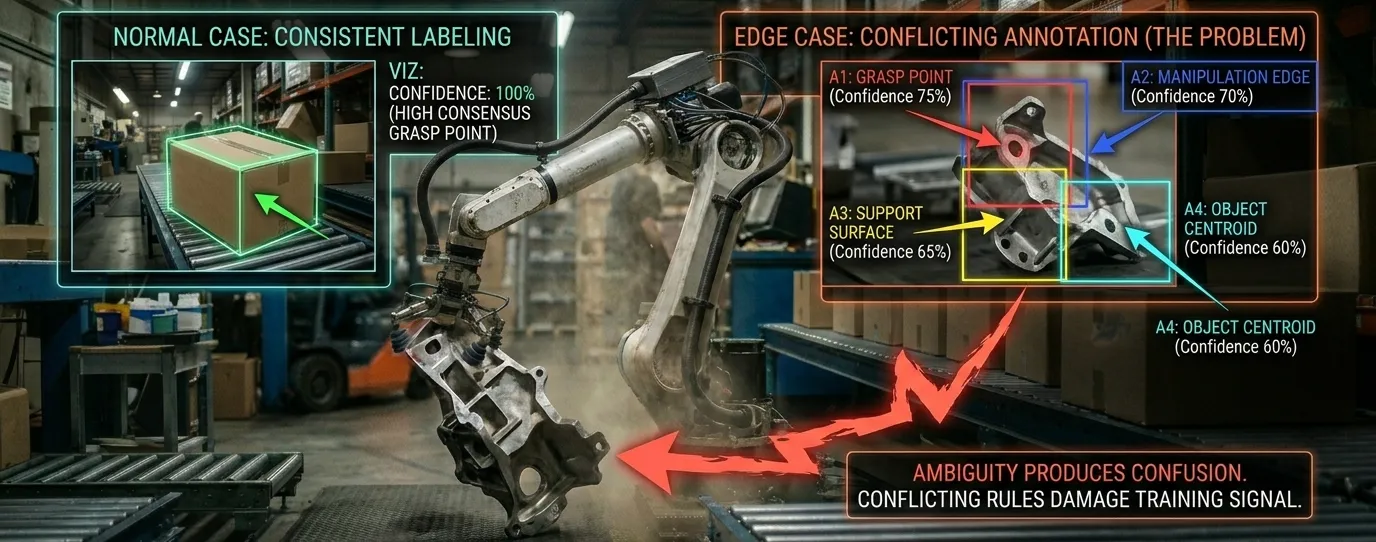
Clear, standard cases are annotated consistently. Give a specific, unambiguous grasping example to ten annotators and you get ten matching labels. The model trains on high-confidence signals where it needs the least guidance.
Edge cases produce annotator disagreement. An object grasped at an unusual angle. A manipulation task performed under partial occlusion. A human-robot proximity scenario where intent is ambiguous. These are the scenarios where the model needs the most precise training signal and they are the scenarios where different annotators make different calls on the same frame. Under time pressure or without edge-case-specific label standards, conflicting labels appear in the training data precisely where conflicting rules would be most damaging.
This produces a specific performance pattern: high accuracy on standard task variants, unexpected failure on variations that seem only slightly different. The model didn't generalize poorly but it learned inconsistent rules from inconsistent labels. The solution isn't a general quality review. Its edge-case-specific annotation standards are established and locked before annotation begins, not applied as a correction afterward.
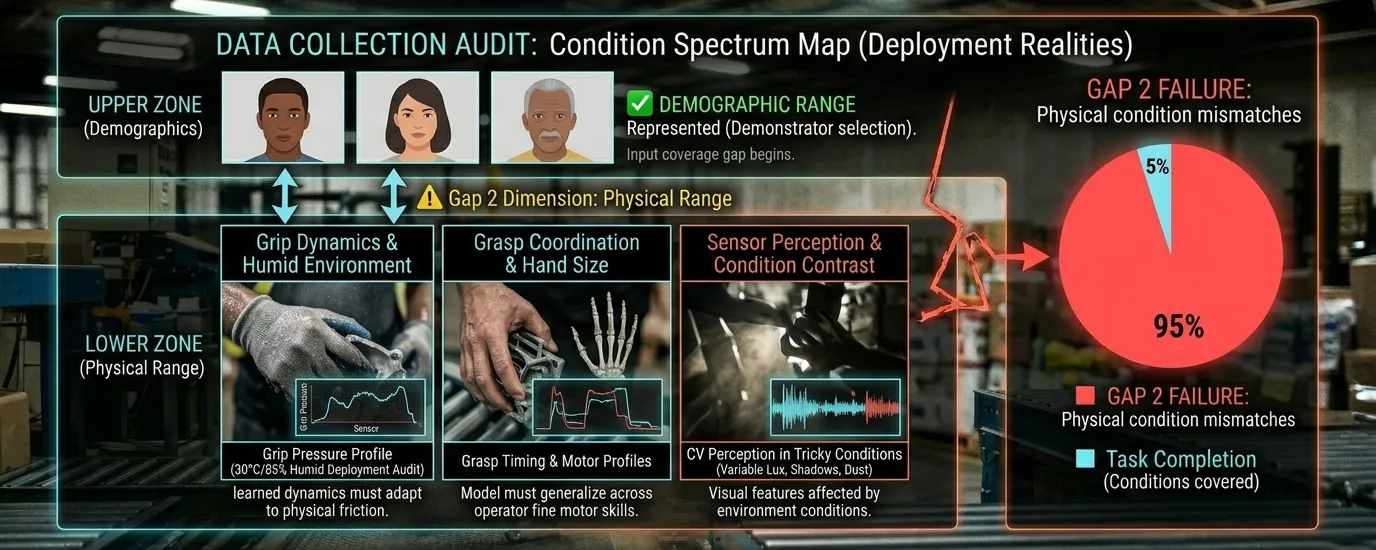
Beyond the environment and the task: the physical conditions of the people who demonstrated the task.
Computer vision systems trained primarily on light-skinned hands show measurable performance differences with darker skin tones, differences that affect grasp detection accuracy, gesture recognition and intent classification. This isn't a hypothetical concern. Research on annotation quality in AI perception systems has documented how demographic gaps in training data propagate into systematic performance differences in deployed systems. Models trained on demonstrations by a narrow operator population perform differently with operators whose hands move at different speeds, have different fine motor characteristics, or interact with objects differently.
Physical AI bias taxonomy adds a dimension language AI teams have never had to consider: the physical conditions of the demonstration affect the model's learned behavior, not just the content of what was demonstrated. Grip pressure, ambient temperature, hand size relative to the objects being manipulated, surface texture, lighting angle, all of these vary across real operator populations and real deployment environments. A grasping model trained in a controlled studio at 22°C with one set of demonstrators will behave differently at 32°C in a humid facility with a different operator population, even if the task is identical.
Demographic diversity in demonstrators is necessary but not sufficient. The relevant range is condition diversity: the physical conditions under which the task will actually be performed in deployment, not just the demographic profile of who performs it.
Each of these five failure modes has a different cause and a different fix. But they share a common origin: the data collection was designed before anyone mapped the deployment environment. That sequencing is where the gap opens and where closing it begins.
The teams that close the collection-to-deployment gap fastest share one operational pattern: they treat the deployment environment as the first input to collection design, not the last.
Standard collection planning starts from model requirements. What data type does the architecture need? What annotation schema? What volume? The deployment environment appears as a general constraint like "warehouse robotics," "surgical assistance," "service robot in hospitality" rather than a specific design input. Collection happens in whatever environment is accessible. The mismatch between collection conditions and deployment conditions is discovered after deployment, during the failure investigation.
Gap 2-aware collection inverts this. Before a protocol is written, before a data partner is contracted, before an annotation schema is finalized, the team documents where and how the system will actually operate. Not at the category level, at the level of the specific facility, its lighting range measured in lux across different operating conditions, its floor surface transitions, its operator population by relevant demographic and physical range, its peak operating temperatures, the actual frequency of edge case types in a normal operating week.
That deployment environment map drives five specific collection design questions, one for each Gap 2 failure mode. What physical environments need to be represented in the data, and has the collection been designed to span that range rather than approximate its center? Are capture devices hardware-synced, and has synchronization alignment been verified across the full recording pipeline before collection begins? What are the failure-critical edge cases in this deployment environment, and have they been deliberately over-sampled relative to their common-case frequency? What label standards govern the ambiguous scenarios specific to this task domain, and are those standards locked before annotation begins? What is the full range of physical conditions like operator demographics, grip profiles, ambient temperature, surface properties in the deployment context and does demonstrator selection reflect that range?
Across FutureBeeAI's physical AI data collection projects, the clearest predictor of deployment performance isn't dataset volume or annotation throughput, it's whether the collection team spent substantive time characterizing the actual deployment environment before collection planning began. Teams that conduct a structured deployment environment audit before writing a collection protocol consistently produce data that closes Gap 2. Teams that don't consistently rediscover the same failure modes in their second deployment cycle, after the first one surfaces what the environment actually requires.
These questions cannot be answered after collection ends. They must be built into the collection protocol from the start. The gap doesn't close by collecting more data. It closes by collecting data designed against the right starting point which is always the deployment environment, not the model spec.
Physical AI teams are failing after careful preparation not because they're doing things wrong, but because they're solving a different problem than the one they have.
The industry's attention has been on Gap 1 like simulation fidelity, domain randomization, synthetic data at scale because Gap 1 is visible, measurable, and amenable to infrastructure investment. The research community has developed sophisticated tools to address it. The progress is real and it matters. But infrastructure investment in Gap 1 solutions doesn't touch the collection-to-deployment gap. Teams who have done everything the current narrative recommends and still see systematic deployment failure are almost certainly experiencing Gap 2.
Closing Gap 2 requires operational knowledge of actual deployment environments, collection protocols designed against deployment conditions rather than model requirements, and annotation standards that specifically govern the hard cases before annotation begins. These don't come from better simulation infrastructure. They come from data expertise tested across real deployment contexts.
The gap between lab performance and production performance in most physical AI systems isn't primarily a model problem. Name the right gap, and the path to closing it becomes clear.
FutureBeeAI designs physical AI training data collections from the deployment environment out, real-world conditions, condition-diverse demonstrator selection, hardware-synced multimodal capture pipelines, and annotation standards built around the edge cases that matter in the specific deployment context. If the failure patterns in this blog match what your team is experiencing, the starting point is a deployment environment audit against the five Gap 2 dimensions before the next collection cycle begins. Talk to FutureBeeAI about your physical AI data pipeline
Q. What is the difference between the sim-to-real gap and the collection-to-deployment gap?
A. The sim-to-real gap is about physics fidelity: simulated environments don't perfectly replicate real-world material behavior, sensor noise, and physical dynamics, so models trained in simulation encounter conditions in deployment they weren't trained on. The collection-to-deployment gap is about representativeness: real-world training data, collected in specific environments under specific conditions, doesn't reflect the range of conditions in the actual deployment environment. Both gaps cause deployment failure, but they have different causes and different fixes. Synthetic data and domain randomization address the sim-to-real gap. They don't address the collection-to-deployment gap.
Q. How do you over-sample edge cases without biasing the training distribution?
A. The goal is to sample edge cases at a frequency indexed to their deployment failure rate, not their natural collection frequency. Common cases are already well-represented, more common-case data adds diminishing value. The specific edge cases to over-sample are identified through a deployment environment audit before collection begins: what scenarios actually cause failure in the deployment context, and at what rate? Those scenarios become the deliberate over-sample targets. The resulting dataset is intentionally unrepresentative of natural event frequencies, which is correct, the model needs to be robust to the hard cases, not just accurate on the common ones.
Q. What does temporal synchronization failure look like in a deployed Physical AI system?
A. It shows as degraded action accuracy on sequential tasks, the system completes isolated actions correctly but loses precision when actions chain together. The failure appears random because no single action is obviously wrong; the error is a small miscalibration in the learned perception-action relationship that compounds across a sequence. Standard training metrics don't surface this problem because the misalignment is small in any single training example. It's identified by specifically analyzing deployment accuracy across multi-step action chains rather than isolated task completions, and traced back to the data capture pipeline through synchronization verification.
Q. What is condition coverage and why isn't demographic diversity sufficient for Physical AI data?
A. Condition coverage refers to the range of physical conditions under which training data was collected: lighting levels, ambient temperature, floor surfaces, demonstrator hand characteristics, object weight and texture, and other physical variables that affect both demonstrator behavior and sensor readings. Demographic diversity representing different ages, genders, and ethnic backgrounds in the demonstrator population is necessary but captures only part of the relevant variation. A dataset with demographically diverse demonstrators, all operating in the same controlled environment under the same physical conditions, can still have significant condition coverage gaps. The relevant question for Physical AI is not just who demonstrated the task, but in what physical conditions it was demonstrated and whether those conditions reflect the full range the deployed system will encounter.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!