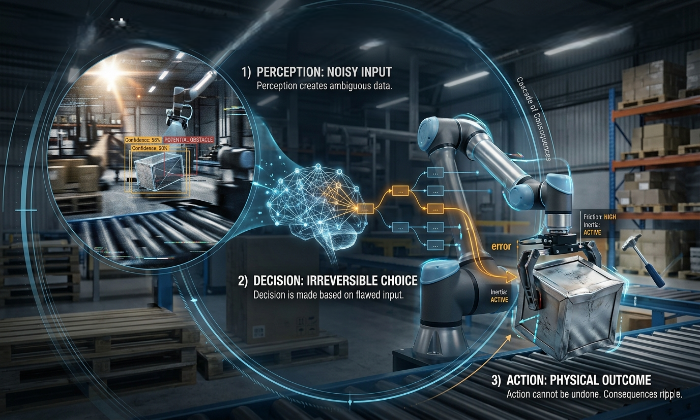
The skepticism is reasonable. Collaborative robots were supposed to work flexibly alongside humans and ended up in the same cages as their predecessors, doing the same repetitive tasks. Computer vision systems were supposed to handle unstructured environments and still require careful staging for reliable performance. Warehouse automation was supposed to handle any package and still struggles when the packaging changes.
Physical AI, the convergence of foundation models with physical robotic systems, is fundamentally different from traditional robotics not because the algorithms are better, but because the knowledge architecture has changed. Traditional robots are programmed, everything they know was specified by a human before deployment. Physical AI systems are trained, their knowledge is learned from data and can expand after deployment. That single distinction changes what these systems can do, where they hit limits, and what maintaining them requires.
The pattern from previous cycles wasn't about algorithm quality. It was about architecture. And the architecture has genuinely changed.
What Traditional Robotics Actually Was and Why It Always Hit a Ceiling
Precision is worth starting with. Traditional industrial robotics is very good at what it's designed for. Robots on automotive assembly lines operate at sub-milli metre accuracy, at speeds humans can't match, for years without failure. The ceiling isn't performance within a defined task. The ceiling is what happens outside that definition.
Traditional robots are programmed systems. A human engineer writes rules for every situation the robot will encounter: if part X arrives at position Y, execute motion sequence Z. The robot executes those rules with high fidelity. When something outside the rules occurs, the part arrives at a slightly different angle, an unexpected object appears on the line, the lighting shifts in a way the vision system wasn't calibrated for, the robot either stops or fails. It has no mechanism for handling what wasn't anticipated, because its knowledge is fixed at build time.
This is the ceiling that previous automation cycles ran into, including the ones that promised flexibility. Collaborative robots addressed the safety question. They could work near humans without injury risk. They didn't address the knowledge question. Their task knowledge was still programmed, still fixed, still brittle at the edge of what was specified. The demos worked because the demo conditions were known in advance. Deployment revealed the limits.
Computer vision automation showed the same pattern. Vision-guided systems handle the variance within their calibrated range and fail outside it. Not because the vision algorithms are poor, modern computer vision is genuinely capable but because the knowledge of what constitutes acceptable variance was programmed in, not learned from the range of conditions the system would actually encounter.
The honest summary: traditional robotics is an excellent solution for tasks that are stable, high-volume, and fully specifiable in advance. The limitation isn't quality. Its scope. Fixed knowledge systems cannot know what the programmer didn't anticipate.
The Architectural Shift From Fixed Knowledge to Learned Knowledge

Physical AI systems are trained, not programmed. The difference is more significant than it sounds.
A Physical AI system built on foundation models doesn't have rules for specific situations, it has learned representations of the physical world, developed from training on diverse data across many environments, objects, and tasks. When it encounters a situation it hasn't seen exactly before, it applies those representations to generate an appropriate response. The capability ceiling isn't defined by what a programmer specified. It's defined by what the training data covered.
The mechanism that made this possible: foundation models pre-trained on internet-scale data before any robot-specific training begins. When a foundation model is fine-tuned on physical demonstration data, it isn't starting from zero, it's adapting a system that already has a broad understanding of objects, spatial relationships, physical concepts, and language. The generalizable knowledge comes in with the pre-training. The robot-specific knowledge is layered on top.
The performance evidence is worth naming specifically. Google DeepMind's RT-2 achieved 62% success on novel scenarios it hadn't seen during training, compared to 32% for prior approaches not a marginal improvement, a different performance signature. Physical Intelligence's π0 demonstrates 40–60% zero-shot success on related but unseen tasks. The latest general Physical AI models are crossing commercial viability thresholds for the first time. These systems don't hit hard walls at the edge of their training. They degrade performance drops as the situation moves further from the training distribution but they degrade gracefully, which is a fundamentally different failure mode from stopping.
The skeptic's objection still applies at the edges: Physical AI systems are not fully general. They fail outside their training distribution. The honest answer is that "outside the training distribution" is now a much wider perimeter than "outside the programmed rules," and it can be expanded by adding data rather than by rewriting programs. That difference compounds over time.. Check Why Physical AI Fails in the Real World.
What "Learned Knowledge" Changes About Building and Running These Systems
This is where the operational implication lives, and where most teams are underprepared.
In traditional robotics, when performance degrades, the team calls a systems integrator or a robotics programmer. The fix is a programming change. The knowledge is updated by a human writing new rules. The operational model is: deploy, maintain mechanically, reprogram when conditions change significantly.
In Physical AI, when performance degrades, the question is different: what conditions is the system encountering that weren't in the training data? The fix is a data change. The knowledge is updated by collecting new demonstration data that covers the conditions causing failures and fine-tuning the model on that expanded dataset. The operational model is: deploy, monitor for distribution drift, expand training data when conditions change, retrain periodically.
That shift changes the composition of the team responsible for the system. Traditional robotics maintenance required mechanical engineers, electrical engineers, and robotics programmers. Physical AI maintenance requires all of that plus people who can identify what training data is needed, collect it in the right format, and manage the fine-tuning cycle. The data operation is not a one-time setup cost, it's a recurring operational requirement.
FBAI has worked with teams that approached Physical AI deployment with the same operational model they used for traditional automation: deploy once, maintain mechanically, call the vendor when something breaks. The teams that ran into trouble earliest had no data pipeline for post-deployment expansion. The teams that sustained performance built continuous collection infrastructure from day one, treating training data as a living system that grows alongside the robot's operational environment, not a fixed asset delivered at project launch.
The systems that are performing well in production today share a characteristic: the teams running them think about data coverage the way traditional robotics teams thought about programming coverage. What new conditions has the system encountered this month? What edge cases is it failing on that weren't in the training set? What variants of the task have appeared in the deployment environment that the original data collection didn't cover? These are the operational questions Physical AI demands. Check our blog at What Is a Vision-Language-Action Model?
Evaluating the Difference in Your Own Context
Traditional robotics remains the right answer for a significant portion of automation use cases like high-volume, stable, fully specifiable tasks where operating conditions don't change and task variants are completely anticipatable. Physical AI adds value when the environment varies in ways a programmer can't fully specify in advance, when the task has a long tail of variants that would require constant reprogramming to cover, or when the system needs to operate across different physical contexts without complete rebuilding.
The practical test: where in your current automation stack does performance degrade because the system encountered something outside what was programmed? Those are the gaps learned knowledge closes. They're also the gaps where the data requirement is highest because closing them requires training data that covers the variation the system will actually encounter in deployment.
That data question is where Physical AI projects succeed or stall. Not the model selection. Not the hardware. The training data strategy and how it's collected, what conditions it covers, and how it expands as the deployment environment evolves.
FBAI designs physical AI training data for teams making this transition. Real-world condition diversity, deployment environment auditing before collection begins, and data pipelines built to expand alongside the system's operational scope. If you're evaluating where Physical AI applies in your stack, the data strategy is where planning needs to start. Talk to FBAI for further discussions.
FAQ Section
Q. Can Physical AI and traditional robotics work together in the same facility?
A. Yes, and in most real deployments they do. Traditional robotics handles the high-volume, deterministic tasks it's designed for welding, stamping, precisely repeating the same motion thousands of times. Physical AI handles the variable, unstructured tasks where fixed programming would require constant reprogramming, bin picking across varied item types, quality inspection in changing conditions, human-robot collaboration in dynamic spaces. Most enterprise deployments treat them as complementary rather than competing: keep traditional automation where it works, introduce Physical AI at the points where fixed knowledge systems hit their ceiling.
Q. How do you detect when a Physical AI system needs more training data?
A. The signal is a mismatch between performance in deployment and performance in testing. Specifically: the system performs reliably on task variants it has seen before and degrades on variants it hasn't. This shows up as inconsistent performance across shifts, locations, or operator populations rather than uniform degradation. Teams running Physical AI in production typically track task success rates by variant type when a specific variant starts failing at a higher rate than others, that's the signal that the training distribution doesn't cover those conditions adequately. The fix is targeted data collection for that specific failure cluster, not a full retraining cycle.
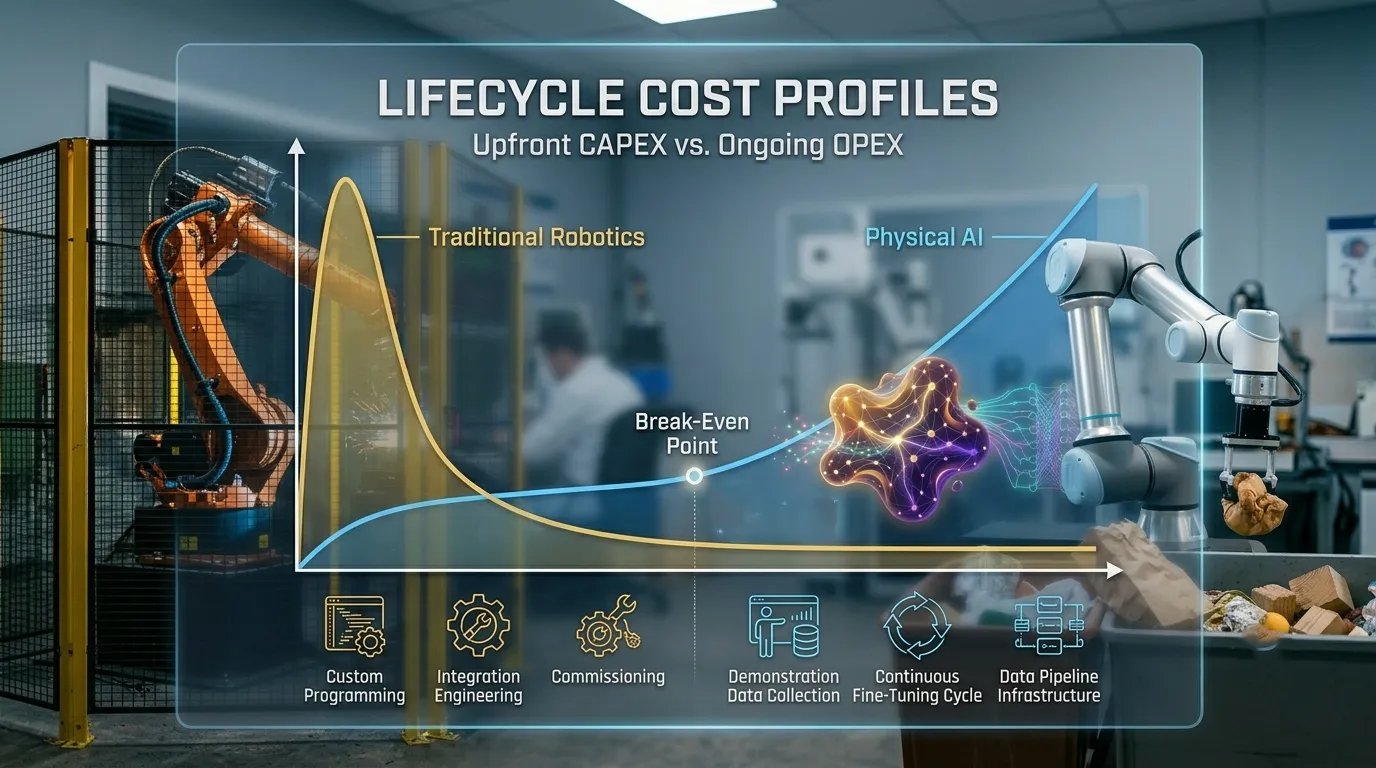
Q. What does it cost to deploy Physical AI compared to traditional automation?
A. The cost profiles are structured differently. Traditional automation has higher upfront engineering costs, custom programming, integration, commissioning but lower ongoing operational costs once deployed and stable. Physical AI has lower upfront engineering costs for the model layer but requires continuous investment in training data infrastructure: demonstration collection, periodic fine-tuning, data quality management. For tasks that change frequently, Physical AI is often cheaper over a multi-year horizon because reprogramming traditional automation is expensive and slow. For stable, high-volume tasks that don't change, traditional automation remains more cost-efficient. The break-even depends heavily on task variability.
Q. What types of tasks is Physical AI genuinely not suitable for today?
A. High-speed, high-precision, deterministic manufacturing tasks. Traditional industrial robots execute sub-milli meter welding and stamping operations at speeds and repeatability that Physical AI systems don't yet match in production. Tasks where latency and reliability requirements are extreme safety-critical industrial applications, for instance still favor programmed systems because their behavior is fully predictable within specification. Physical AI's advantage is flexibility in unstructured environments. Its limitation is that graceful degradation, the feature that makes it adaptable, is also the reason it's not yet appropriate for contexts where any deviation from perfect execution has unacceptable consequences.