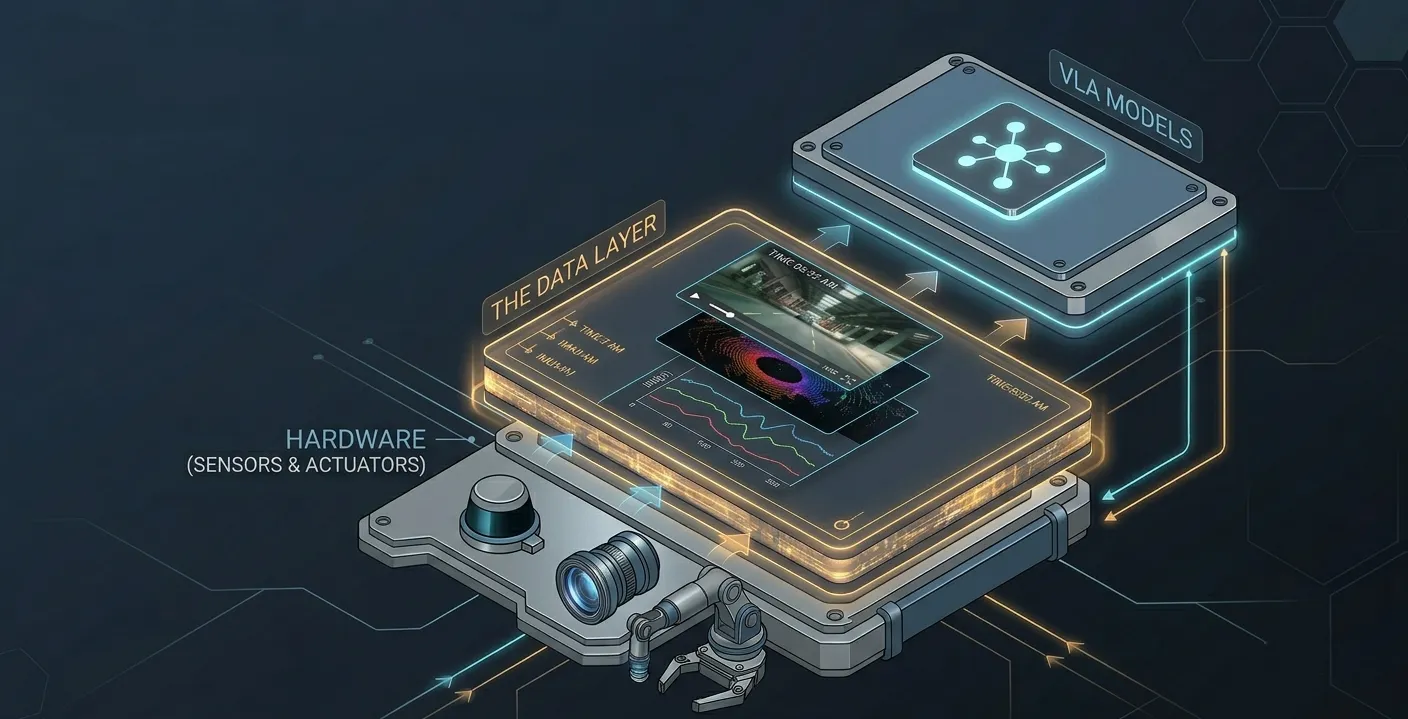
Most Physical AI stack diagrams show two layers clearly: hardware at the bottom, models in the middle. The data layer appears as a thin arrow between them, sometimes labelled "training data," more often not labelled at all.
The Physical AI stack has three distinct layers named hardware, software and models and data. Each requires different infrastructure, different expertise and different ongoing operational work. The hardware and model layers are increasingly well-understood; the data layer is where most Physical AI projects encounter problems they didn't budget for, because it wasn't in the diagram they planned from.
The data layer's invisibility isn't accidental. It spans the boundary between the disciplines that own the other two layers and what belongs to everyone's problem ends up in nobody's architecture.
The Hardware Layer : What the Physical World Actually Requires
The hardware layer is the boundary between digital intelligence and physical reality. It has two directions: sensors that bring the physical world in and actuators that execute decisions in it.

Perception hardware gives the system its view of the environment. RGB cameras provide visual input; depth cameras and stereo rigs add spatial information. LiDAR maps three-dimensional geometry with precision cameras that can't match, particularly in variable lighting conditions. Force/torque sensors at the wrist and fingertips give the system feedback on contact forces that is critical for any manipulation task where the robot needs to know whether it's gripping correctly, too hard or not at all. IMUs track orientation and motion. Together, these sensors produce a multimodal stream: a continuous flow of data about the physical environment from multiple sources simultaneously.
The challenge is synchronization. A Physical AI system makes decisions from fused multimodal inputs and those inputs have to be temporally aligned to precision. A camera running at 30fps and a force/torque sensor running at 1kHz produce measurements at different rates. The model trains on the relationship between visual observations and motor commands, if those two streams are even a few milliseconds out of alignment, the model learns a subtly mis calibrated relationship. The hardware integration problem is not just connecting sensors; it's building pipelines that keep their outputs time-aligned.
Edge compute handles inference locally, at the robot. The model can't wait for a cloud round-trip but a robot arm executing a manipulation task needs to issue motor commands at 10–30Hz, with total latency measured in milliseconds. NVIDIA Jetson, Qualcomm's robotics SoCs and purpose-built neural processing units are the current generation of hardware for this layer. The engineering tradeoff is compute capacity versus power draw: more capable inference hardware consumes more power, which affects battery life and thermal management in mobile systems.
Actuators close the loop motors, grippers, wheels, joints executing what the model decides. The quality of the actuator layer affects what training data you can collect and what the model can learn: a gripper with poor force feedback limits the manipulation tasks worth attempting; a mobile platform with imprecise odometry makes navigation tasks harder to train for.
The hardware layer is primarily a procurement and integration problem. The components exist. What matters is how they're assembled, synchronized and critically how the data they produce flows into a format suitable for training the model layer above it.
Also see Why Physical AI Fails in the Real World on "temporal synchronization".
The software and models layer where intelligence lives

The model layer is where physical sensor inputs become intelligent decisions. It has three main components: the foundation model, the simulation environment, and the inference runtime.
Foundation models Vision-Language-Action models are the central intelligence. A VLA takes visual observations and natural language instructions as inputs and produces motor commands as output. Modern VLAs (OpenVLA, Physical Intelligence's π0, NVIDIA's GR00T N1, Google DeepMind's Gemini Robotics) are pre-trained on internet-scale vision-language data and fine-tuned on physical demonstration data for specific deployments. The pre-training provides a broad generalizable understanding of spatial reasoning, object recognition, instruction following. Fine-tuning specializes that understanding for the specific task, robot, and environment.
Foundation models are now accessible. OpenVLA is open-source. Physical Intelligence has open-sourced π0. The model layer is no longer behind a research lab firewall; it's available to engineering teams with the infrastructure to work with it.
Simulation supports training before real-world deployment. Simulation environments like NVIDIA Isaac Sim, MuJoCo, Genesis let teams run training cycles at accelerated speed in virtual versions of deployment environments. This is where initial policies get trained before physical hardware is involved, and where edge cases too dangerous or too rare to collect in the real world get addressed through synthetic data generation.
Simulation is valuable and widely used. It has a ceiling: simulated physics, textures, lighting, and material properties don't fully replicate real-world conditions. Models trained entirely in simulation typically require real-world fine-tuning before they perform reliably in deployment. Simulation supplements real demonstration data; it doesn't replace it.
Inference runtime bridges training and deployment. A 7B-parameter VLA trained on a GPU cluster needs to run on edge hardware at robot-control speeds. Model quantization, distillation, and efficient serving frameworks are the engineering work that makes this possible. This is where the gap between "the model performs well on benchmarks" and "the model performs well on the robot" most commonly lives.
The model layer is increasingly tractable. The hard problems are foundation model architecture, training at scale, efficient inference, having active research communities and improving solutions. The bottleneck is no longer primarily in this layer.
The bottleneck is what feeds it.
Also See What Is a Vision-Language-Action Model?
The data layer what nobody draws in the diagram
The data layer sits between the hardware layer and the model layer, bridging physical sensor capture and model training. It belongs to neither layer's owner. Robotics engineers own the hardware; ML engineers own the models. The data layer spans both, it requires understanding what the hardware captures, what format the model needs, and how to move from one to the other reliably and at scale. When it belongs to everyone's scope, it ends up in nobody's architecture diagram.
It appears instead as a problem mid-project: the model is trained on data that wasn't formatted correctly, the annotation schema doesn't capture what the model needs to learn, the temporal synchronization wasn't built into the hardware integration. The data layer gets discovered when it's expensive to fix.
What the data layer actually contains:
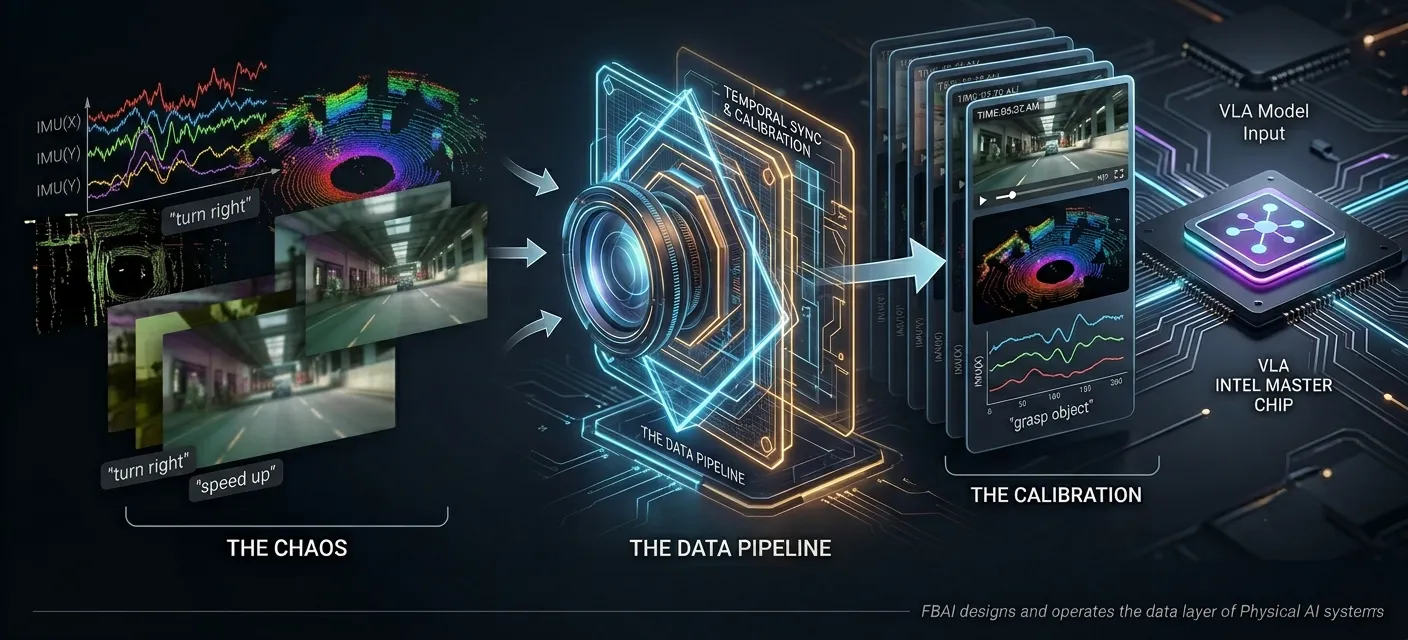
Demonstration collection infrastructure is the physical setup for capturing human demonstrations teleoperation systems that let humans control robots while their actions are recorded, motion capture rigs for capturing human demonstrations of tasks, recording hardware for all sensor streams, and the synchronization layer that timestamps and aligns them. This is physical infrastructure, not software. It has to be designed, built, and tested before a useful collection can begin.
Annotation and labelling pipelines process raw episodes into training-ready data. Task success and failure labelling was the grasp successful, did the robot complete the task, was the action appropriate given the instruction? It requires people with domain knowledge who understand what correct robot behavior looks like, not general-purpose labelers rating image quality. Edge case tagging identifies the unusual scenarios the model needs to learn from. Quality filtering removes corrupted recordings, misaligned streams, or demonstrations that don't meet the standard the model requires.
Temporal synchronization and schema standardization align multimodal streams and convert them into training-ready formats. Raw hardware output like sensor streams at different rates, in different coordinate frames, in different units needs to be processed into consistent, model-compatible schemas. For projects using multiple robot embodiments, standardizing across different action spaces and observation formats is additional engineering work that often gets underestimated.
Dataset management handles the full lifecycle of the training corpus: versioning as the dataset grows, maintaining train/validation/test splits, tracking episode provenance, and quality metrics over time. A Physical AI dataset isn't a static asset, it grows as the system encounters new conditions and performance gaps are identified.
Continuous fine-tuning loops are the operational system that keeps the deployed model performing as its environment changes. Post-deployment, as the robot encounters conditions outside its training distribution, new demonstration data gets collected, added to the dataset, and the model fine-tuned on the expanded corpus. This isn't a one-time project phase. It's an ongoing operational system that runs alongside the deployed robot.
In FBAI's experience building physical AI data pipelines, the teams that discover the data layer late share one characteristic: they scoped the model layer first and assumed data collection could be worked out afterward. By the time the model needs training data, the collection infrastructure doesn't exist, the annotation schema wasn't designed for what the model actually learns from, and the temporal synchronization wasn't architected into the hardware integration. Each of these takes significant time to correct retroactively. The data layer has to be scoped before the model layer, not because it's more important, but because the model layer's requirements define what the data layer needs to produce, and building the data layer wrong means rebuilding it.
Why the data layer has to be designed first
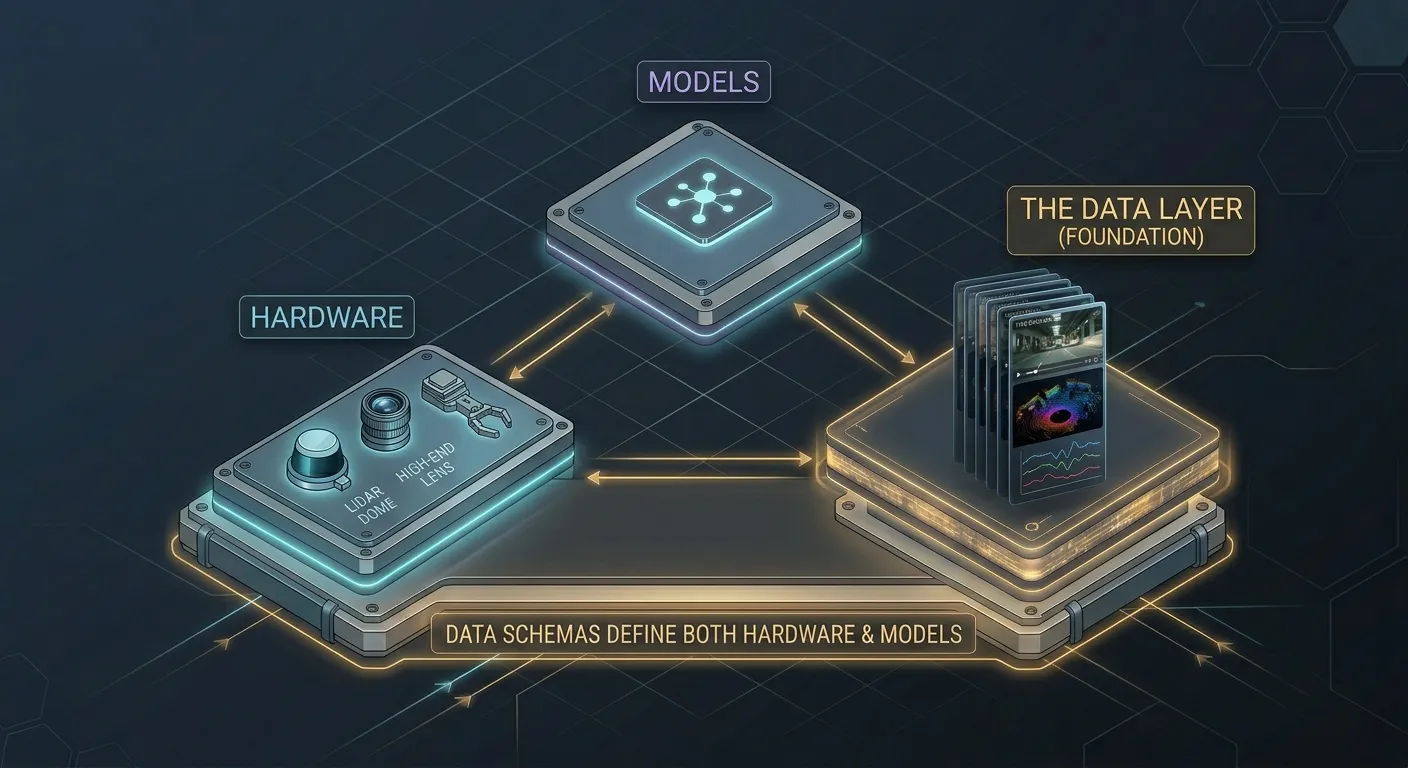
The three layers of the Physical AI stack are not independent. The data layer connects the hardware layer and the model layer, and its design requirements flow from both.
What the hardware layer produces determines what data is capturable. What the model layer requires determines what data format is needed. The data layer design has to precede finalizing both or teams make hardware integration decisions that produce data in formats the model can't use, and model selection decisions that require data the collection infrastructure wasn't built to capture.
In practice: before finalizing sensor selection, understand what the annotation schema requires and whether those sensors can produce it. Before beginning model fine-tuning, have a tested collection pipeline producing data in a consistent, model-compatible format. Before deployment, have a continuous collection plan on how deployment failures route back into the training pipeline, who operates the fine-tuning cycle and how often it runs.
The data layer is the part of the Physical AI stack that doesn't come packaged with a foundation model license or a hardware kit. It has to be designed, built and operated and the teams that design it first are the ones who don't spend six months rebuilding it after the first training run.
FBAI designs and operates the data layer of Physical AI systems: demonstration collection infrastructure, multimodal annotation, temporal synchronization, dataset management, and continuous fine-tuning loops across real-world deployment environments and 100+ locales. The data layer is where Physical AI projects succeed or stall. It should be the first thing on the architecture diagram, not the last. Talk to FBAI about your Physical AI data layer.
FAQ Section
Q. What is teleoperation and how is it used to collect Physical AI training data?
A. Teleoperation is the technique of having a human operator control a robot remotely while the robot's actions and sensor data are recorded simultaneously. The human demonstrates how to complete a task like grasping an object, navigating a space, sorting items while the system captures the full sensor stream and the corresponding motor commands the operator issued. Those recorded episodes become the training demonstrations the model learns from. Teleoperation is the primary method for collecting manipulation training data because it produces natural, task-appropriate demonstrations that reflect how tasks should actually be performed, rather than synthetically generated trajectories.
Q. Who should own the data layer in a Physical AI team?
A. The data layer requires a dedicated function that reports to both the hardware and model teams rather than sitting under either. In practice the most common effective structure is a dedicated robotics data engineering team distinct from the ML team that trains models and distinct from the hardware integration team with explicit mandate to own collection infrastructure, annotation pipelines, dataset management, and fine-tuning operations. Companies that have hardware teams handle data collection typically produce data in hardware-native formats the model team can't use without significant processing. Companies that have ML engineers handle collection typically lack the physical infrastructure expertise to build synchronized, reliable capture pipelines.
Q. How does simulation-generated data compare to real-world demonstration data?
A. Simulation data and real-world demonstration data serve different roles and have complementary limitations. Simulation data can be generated at scale quickly, covers edge cases and dangerous scenarios impractical to capture in reality, and allows controlled variation of parameters like lighting, physics, and object properties. Its limitation is the sim-to-real gap: simulated environments don't perfectly replicate real-world materials, surfaces, sensor noise, or human movement. Real-world demonstration data has the inverse profile, it captures genuine physical conditions but is expensive and slow to collect at scale. Most production Physical AI systems use simulation for initial training and volume, then real-world demonstrations for fine-tuning and grounding.
Q. What skills does a team need to build and operate the Physical AI data layer?
A. Three skill clusters that most software AI teams don't have: physical data collection operations (designing and running teleoperation systems, managing recording hardware, maintaining synchronized sensor capture pipelines across multiple devices), domain annotation expertise (judging whether robot behavior in recorded demonstrations is correct, safe, and appropriate for the specific task, this requires understanding of the physical task, not just labelling patterns), and robotics data engineering (converting hardware-native sensor formats into model-compatible schemas, managing episode versioning across embodiments, building the feedback loop from deployment failures back into the training pipeline). The data layer is where software engineering meets physical operations.






