Introduction
Clinical conversations are among the most demanding speech environments for artificial intelligence. Doctors think aloud while reading charts, patients pause, cough, rephrase symptoms, and speakers often talk over one another. For systems that aim to transcribe, summarize, or extract clinical meaning, clinical ASR engines, documentation assistants, or clinical NLP pipelines, the underlying doctor–patient speech dataset is the single biggest determinant of whether those systems will work in the real world.
Collecting clinical speech is not the same as recording scripted lines in a studio. Real encounters contain sensitive health information and wide variation across specialties, accents, devices, and acoustic settings. At the same time, training only on sterile or synthetic audio leaves models brittle in practice. This piece walks through how a clinical speech dataset is engineered to be AI-ready: how teams preserve realism while protecting privacy, how recordings are annotated and audited, and what metadata and quality controls make the data genuinely useful for clinical AI.
A real clinical moment and why it challenges AI
 Medical dialogue moves in ways that staged speech does not. Small signals carry outsized meaning: a breathy pause when a patient attempts to describe chest tightness, a clinician’s parenthetical note about recent medication, a patient switching languages mid-sentence. These are the cues humans use to understand intent and urgency, but they are the very things that confuse off-the-shelf speech systems.
Medical dialogue moves in ways that staged speech does not. Small signals carry outsized meaning: a breathy pause when a patient attempts to describe chest tightness, a clinician’s parenthetical note about recent medication, a patient switching languages mid-sentence. These are the cues humans use to understand intent and urgency, but they are the very things that confuse off-the-shelf speech systems.
Imagine a short exchange in internal medicine: the clinician asks about breathing; the patient coughs and says, “It’s worse when I climb stairs… and last night I felt a squeeze, um!” Was it pressure?” the clinician overlaps while asking a clarifying question. A faint corridor noise appears. For an experienced human transcriber, this is navigable; for a model trained on clean broadcast speech, it results in dropped entities, missed speaker turns, and misrecognized medication names. That gap between what models are trained on and what they must handle is why dataset design matters.
What “AI-ready” means in a doctor–patient speech dataset
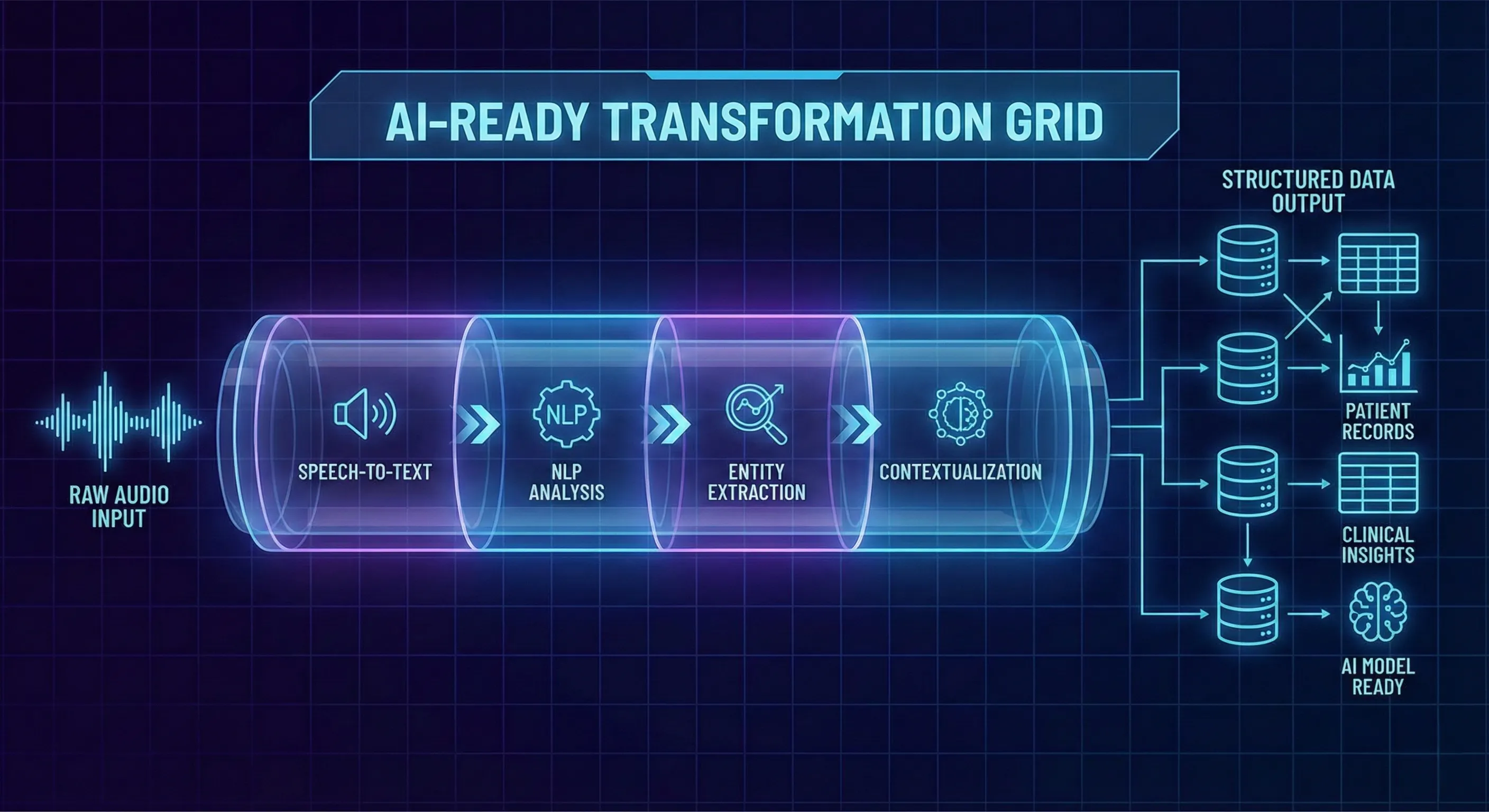 Calling a dataset “AI-ready” is shorthand for a set of properties that go well beyond audio fidelity. An AI-ready clinical speech dataset preserves conversational nuance while packaging data so models can learn the right mappings from sound to structured meaning.
Calling a dataset “AI-ready” is shorthand for a set of properties that go well beyond audio fidelity. An AI-ready clinical speech dataset preserves conversational nuance while packaging data so models can learn the right mappings from sound to structured meaning.
Concretely, AI-readiness means the audio is paired with consistent, machine-friendly structure: speaker roles and timestamps, clinically informed annotation layers, rich metadata describing the recording and speakers, multilingual coverage that reflects deployment targets, and auditable consent records. Clean audio for its own sake is not the goal; robustness is. Models need to see the kinds of disfluency, overlap, and accent variation they will meet in hospitals and telehealth sessions. When those phenomena are present and well-labeled, a dataset becomes practical training material rather than an academic artifact.
Core criteria of an AI-ready dataset
An effective doctor–patient speech dataset includes: reliable speaker separation (diarization); timestamps and fine-grained utterance segmentation; entity-level annotations (symptoms, medications, diagnoses); intent or dialog-act labels where useful; and consistency enforced through annotation guidelines. It must also be deliberately diverse: balanced across languages, accents, age groups, and clinical specialties. Finally, every recording must be traceable to a consent record and rights agreement so downstream users can verify permitted uses.
Why treating voices as personal data reshapes the process
Voices are not inert: they carry identity and personal health context. That’s why consent for voice data cannot be a perfunctory checkbox. Contributors must be told how recordings will be used, what rights they grant, and how withdrawal works. For published datasets, a best practice is to capture consent in an auditable system and tie every delivered file back to that consent. This requirement changes how projects log metadata, handle deletion requests, and design access controls because compliance and model utility must be engineered together, not retrofitted later.
Why real doctor–patient conversations matter and why they’re hard to collect
Raw, real-world medical conversations are the most valuable training signal for clinical AI because they contain natural phrasing, realistic turn-taking and contextual errors that mirror deployment conditions. Yet collecting recordings of true clinical encounters is both ethically and operationally fraught: consent logistics, institutional review, and the presence of personally identifiable information make broad, scalable capture of live patient data impractical in most cases.
To resolve that tension, teams commonly create simulated but realistic conversations guided by licensed physicians. In this approach, clinicians and trained patient contributors role-play clinical scenarios in controlled but realistic settings. The goal is to capture authentic dialog dynamics interruptions, hesitations, domain language, multilingual switching without recording real patient health records. This method enables intentional coverage across specialties and languages while keeping the data free of actual patient identifiers.
How Full Lifecycle of Doctor–Patient Speech Dataset built?
 Turning conversation into an AI-ready clinical speech dataset is a deliberate, multi-stage process. Each stage is designed to preserve realism, ensure compliance, and produce machine-friendly structure.
Turning conversation into an AI-ready clinical speech dataset is a deliberate, multi-stage process. Each stage is designed to preserve realism, ensure compliance, and produce machine-friendly structure.
Contributor onboarding and verification through Yugo
Most projects begin inside Yugo, our contributor and workflow platform, which handles identity verification and captures contributor attributes. Licensed clinicians submit credentials; patient contributors verify demographic and language details. Yugo records permissions and enrolment metadata so every participant’s profile is tied to the recordings they produce. This upfront verification is essential to achieve demographic balance and clinical validity.
Specialty-focused participant setup
Medical vocabulary and dialog patterns vary by specialty. Before recording, projects create specialty cohorts like cardiology, dermatology, psychiatry, ENT and so on. So clinicians can role-play plausible scenarios and contributors can be briefed on likely symptom narratives. This targeted setup ensures the dataset includes domain-specific terminology and interaction patterns.
Consent as a process, not a checkbox
Consent is logged and auditable. Use the exact language approved for consent: “Contributors grant project-specific usage rights, logged and auditable in Yugo.” Withdrawals are operationalized: if a contributor requests removal, their files are removed from active datasets and excluded from delivery, and the deletion or restriction is recorded for audit. This approach aligns ethical practice with operational traceability.
Realistic yet unscripted recording
Recordings are captured in clinically realistic environments, simulated exam rooms, telehealth setups, or quiet offices using common devices (mobile phones, headsets, laptop mics, or phone lines). The sessions are unscripted within clinically guided scenarios: clinicians prompt, contributors respond naturally and conversation is allowed to unfold. Background noise, overlapping speech and regional accenting are not artificially removed; they are preserved as signals models must learn to handle.
Annotation, labeling and quality checks
After collection, audio is transcribed and annotated according to clear audio dataset annotation guidelines. Labels include intents, symptom mentions, medications, diagnoses, empathy markers, speaker role tags and timestamps. Medical reviewers cross-check domain-specific labels against clinical plausibility, while linguistic annotators ensure consistency. The workflow uses a two-layer QA process, annotation plus medical review to preserve high inter-annotator agreement without exposing numerical QA thresholds.
Compliance, packaging, and delivery
Final datasets are packaged with transcripts, annotation files, and metadata bundles. Audio is delivered in standardized formats (WAV, 16 kHz, 16-bit, mono or stereo) and accompanied by documentation describing annotation conventions, consent provenance, and permitted use cases. Only after final compliance checks confirm that no withdrawn or restricted material is present is the dataset made available for model training.
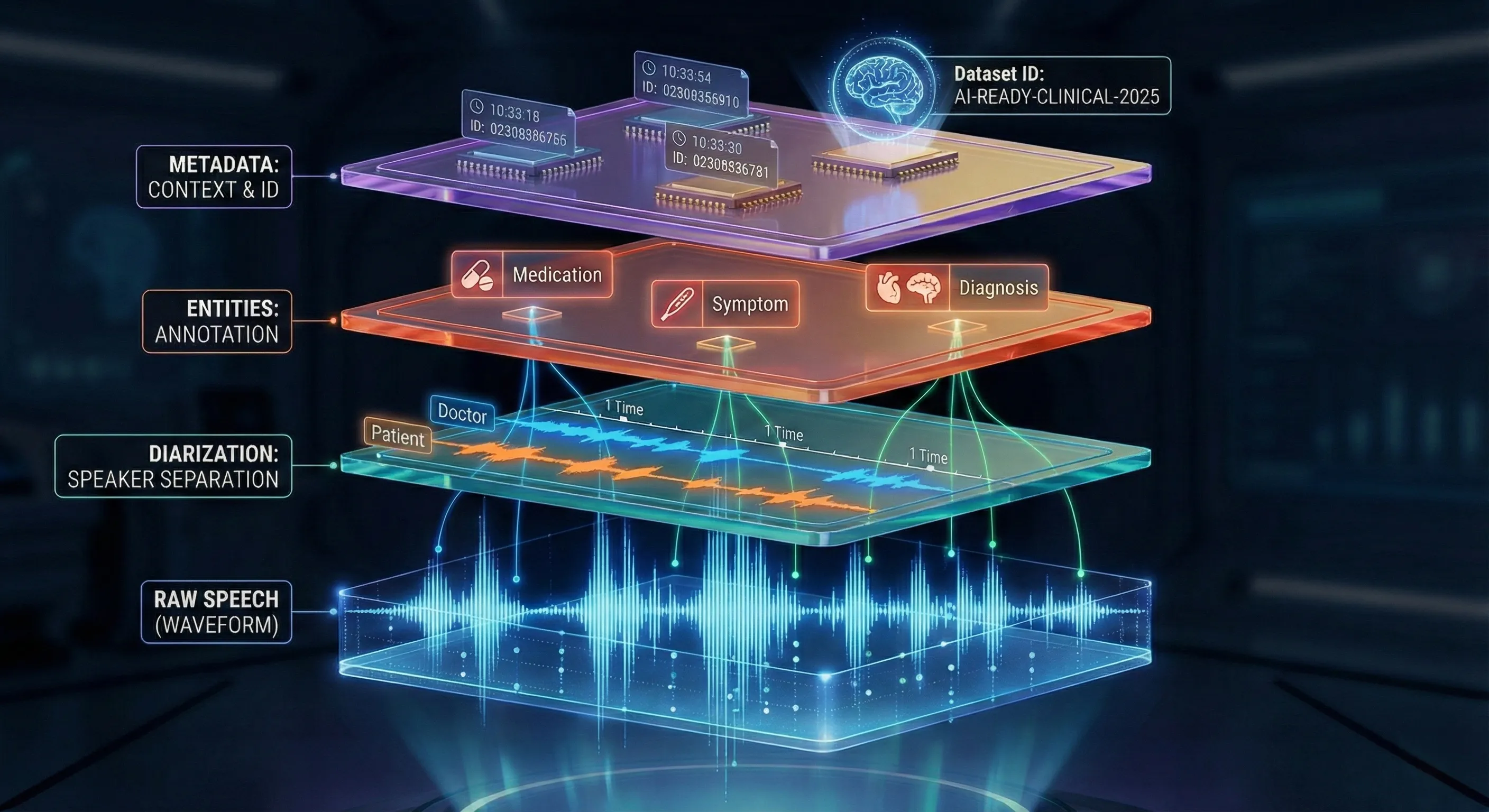 If audio is the raw material, metadata and annotations are the engineering scaffold that makes a clinical speech dataset useful for ML. They convert opaque recordings into data researchers can filter, balance, and experiment with.
If audio is the raw material, metadata and annotations are the engineering scaffold that makes a clinical speech dataset useful for ML. They convert opaque recordings into data researchers can filter, balance, and experiment with.
Core metadata fields should be present for every file: language, accent/region, age group, speaker role (doctor/patient), doctor qualification or specialty, recording environment, device type, duration, and noise level. This speech dataset metadata allows teams to analyze model performance across accents, filter by specialty, and build stratified evaluation sets that reveal where models fail.
How annotations give structure to messy medical speech
Annotations separate speakers, mark symptom mentions, tag medication names, annotate disfluencies and interruptions, and capture dialog acts or intent. These layers let downstream systems extract precise entities and support tasks such as automated note generation, symptom extraction or triage prioritization. Equally important: annotation provenance, annotator IDs, timestamps and revision logs must be recorded so changes are auditable and training pipelines can incorporate consensus logic.
Ethics and Operational Compliance in Clinical Speech Data
 Ethics in clinical speech is not an add-on; it is embedded into each operational choice. Protecting contributors, preserving trust, and documenting permissions are as important as transcription accuracy.
Ethics in clinical speech is not an add-on; it is embedded into each operational choice. Protecting contributors, preserving trust, and documenting permissions are as important as transcription accuracy.
Protecting sensitive voice data
Audio can contain accidental identifiers or contextual clues. Standard safeguards include redaction, beep masking, and use of placeholder tags (for example, <NAME> or <CITY>) where needed. Access controls, secure storage, and encryption protect files in transit and at rest. Importantly, projects must state compliance plainly and exactly: “Adheres to major global privacy frameworks including GDPR, HIPAA ect, and regional health data regulations.” That phrase belongs in the ethics documentation and project brief. These commitments should be reflected in clearly documented privacy and compliance policies.
Auditability, documentation, and trust
Traceability builds trust. Yugo logs consent actions, annotator activity, metadata updates, and review edits, producing an end-to-end audit trail. Dataset documentation should include a clear mapping from files to consent records and an atlas of metadata fields and annotation conventions. This transparency allows technical teams and compliance reviewers to validate data lineage and ensures that anyone using the dataset can verify permitted uses.
Closing thoughts
Building an AI-ready doctor–patient speech dataset requires more than recording conversations; it requires coordinated engineering, ethical practice, and rigorous workflows. Clinical speech is nuanced and variable, and models will only generalize when the training data reflects that reality that complete with accents, interruptions and realistic clinical phrasing. The work that converts messy dialog into machine-ready material depends on careful contributor verification, auditable consent, structured annotations, and rich metadata.
FutureBeeAI supports this level of dataset rigor through both off-the-shelf doctor–patient conversation datasets and fully custom collections. This also includes specialized doctor dictation speech datasets for medical transcription and documentation workflows. Our OTS catalog covers 50+ global and Indian languages and our custom programs extend to 100+ multilingual combinations when projects require specialized breadth.
Most projects begin inside Yugo, our contributor and workflow platform, which manages onboarding, consent logging, metadata capture, annotation tracking and secure delivery, helping ensure datasets are ethically sourced, auditable, and fit for clinical AI development. For more perspectives on clinical AI datasets and annotation, explore additional resources in the FutureBeeAI blog. If you’re evaluating or planning a doctor–patient speech dataset and would like documentation or a technical conversation, contact us for a demo.






