SFT
LLM
Supervised Fine-tuning for Large Language Model
A deep dive into the comprehensive guide on supervised fine-tuning for refining large language models for precision and performance.
SFT
LLM
A deep dive into the comprehensive guide on supervised fine-tuning for refining large language models for precision and performance.

Can you believe how quickly things are changing with natural language processing (NLP) and those large language models (LLMs)? They're transforming the way we live and work in more ways than we can imagine. These advancements are not only fascinating but also incredibly practical, enhancing both our personal and business lives.
In our last blog post “How LLMs are Built”, we delved into the intricate details of how these large language models are built, and it was quite the journey, right?
Today, we're taking a closer look at a crucial step in LLM development: Supervised Fine Tuning (SFT). But before we dive headfirst into this phase, let's first get a broad perspective on the training process of these LLMs.
When it comes to training large language models (LLMs), there are a few important stages to consider. This includes pre-training, supervised fine-tuning, and reinforcement learning from human feedback.
One of the initial phases is known as pre-training, where the model is exposed to a massive amount of publicly available text from the internet. Now, from a computational perspective, this pre-training phase can be quite expensive, costing several hundred thousand dollars. However, it's a crucial step in building a robust language model.
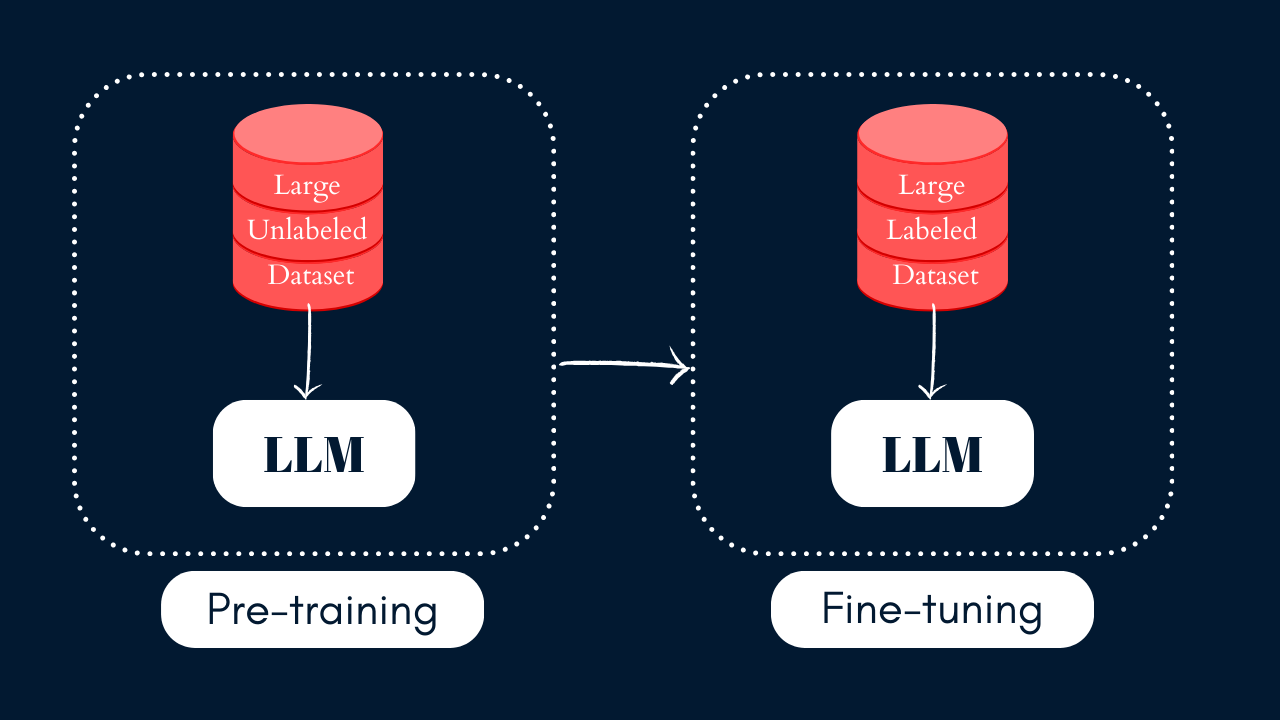 During pre-training, the main goal is to teach the model to predict the next word in a given sentence. This is all about honing its language understanding abilities. But here's the thing, pre-trained models, at this stage, aren't super specific for any particular task. So, they can't be used directly to generate high-quality responses.
During pre-training, the main goal is to teach the model to predict the next word in a given sentence. This is all about honing its language understanding abilities. But here's the thing, pre-trained models, at this stage, aren't super specific for any particular task. So, they can't be used directly to generate high-quality responses.
That's where fine-tuning comes into play. It's like the bridge that helps our pre-trained model provide accurate and desired responses to specific prompts. In the fine-tuning process, we leverage the model's general language understanding capabilities and tailor it to a particular task through supervised learning. This fine-tuning phase can include several steps like SFT and RLHF, and the good news is that it's computationally more budget-friendly compared to the pre-training phase.
So, in a nutshell, pre-training gives our model a strong foundation in language, while fine-tuning helps it specialize in delivering the responses you want.
This three-stage LLM training and alignment process of pre-training, supervised fine-tuning, and reinforcement learning was originally proposed in the ‘Learning to summarize from human feedback’ paper and then successfully adopted for InstructGPT and chatGPT. Later this three-stage training process became very popular and standard for LLM training.
When it comes to what we expect from large language models, we're all about the "HHH trifecta." Let me break that down for you:
First and foremost, the responses generated by these models should be super useful. They should give users exactly what they're looking for without overwhelming them with extra, unnecessary info. Think of it as providing a complete answer with a little extra context to really help the user out.
Honesty is the name of the game. We want responses to be spot-on with the facts, and they should always be up-to-date. No room for making stuff up or presenting false information confidently which is referred as Hellucination in LLM. It's all about keeping it real.
Lastly, we want to make sure these responses follow ethical guidelines. That means no harmful or unethical content, no discrimination, no inappropriate language, and definitely no bias when it comes to things like race or gender. We're all about creating a safe and respectful environment.
To make these language models truly useful, they need to stick to the HHH trifecta. Let's dive into how we make sure they align with these principles.
So, after our little journey so far, it seems like these pre-trained models might not be hitting the mark for users. They don't always give us those triple-H qualities: helpfulness, honesty, and harmlessness. In fact, they can be quite repetitive, not to mention a little wonky in the formatting department.
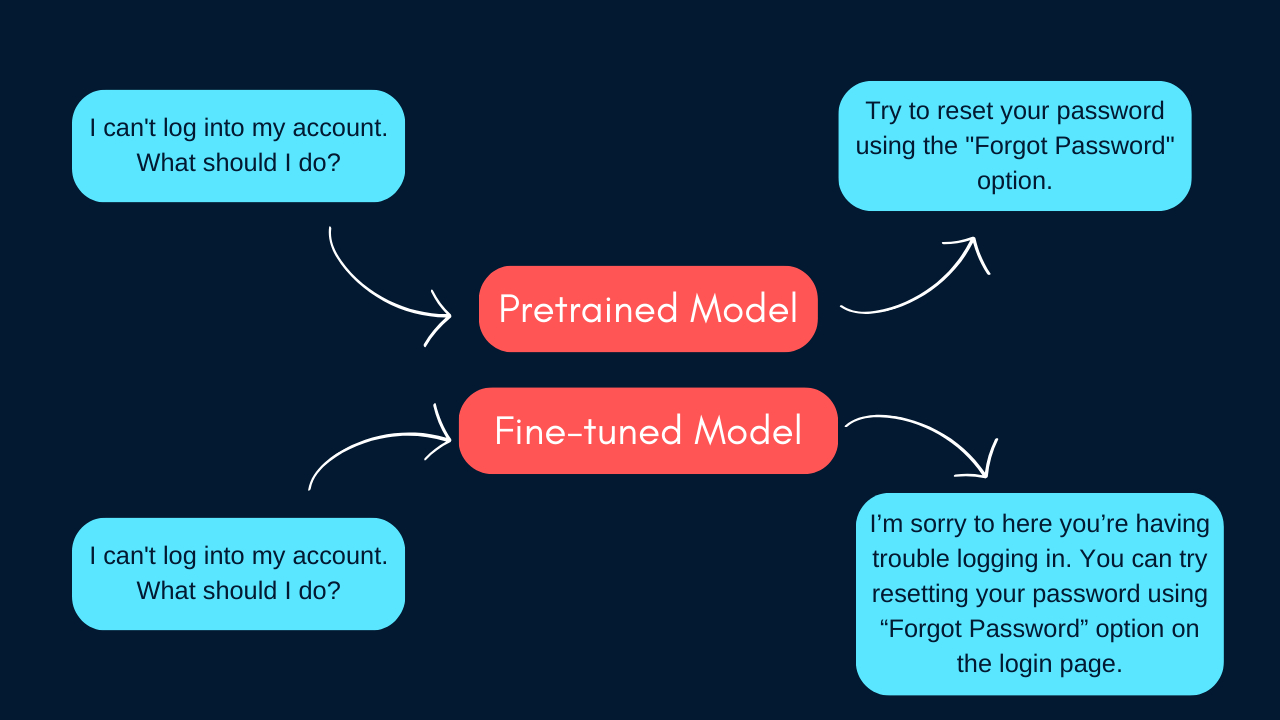 But here's the good news: we can actually make these models more user-friendly. The secret sauce is aligning the language model to produce responses that users really want. Think of it like teaching the model some manners. We do this through a process called fine-tuning, which involves steps like SFT and RLFH.
But here's the good news: we can actually make these models more user-friendly. The secret sauce is aligning the language model to produce responses that users really want. Think of it like teaching the model some manners. We do this through a process called fine-tuning, which involves steps like SFT and RLFH.
During this alignment stage, we're laser-focused on nailing down the perfect response. Our goal is to create policies that ensure our model gives responses that are super helpful, totally factually accurate, and completely free from any harmful or discriminatory content.
Now, SFT is a big player in getting that alignment just right. Let's dive into the details of that, shall we?
Supervised fine-tuning is the starting point in aligning a pre-trained model, and it paves the way for reinforcement learning with human feedback. When we talk about SFT, we're essentially setting up a demonstration dataset and then refining our pre-trained model based on it.
Now, this demonstration dataset is pretty straightforward – it's a collection of prompt-and-response pairs created by real humans, and they're spot on in terms of accuracy and adhering to our desired format guidelines.
We call this stage "supervised" because, well, we're rolling up our sleeves and manually gathering and curating this dataset, then training the language model to mimic it.
In a nutshell, both pre-training and supervised fine-tuning share a common objective – predicting the next token. The key difference? It's the type of data used in each stage. Pre-training relies on a massive, unsupervised text corpus, while SFT banks on a top-quality, human-crafted prompt-response dataset.
You know, there's a pretty interesting distinction between the way we fine-tune deep learning models in general and how we do it for large language models. When we're doing the standard fine-tuning, we're essentially teaching the model to become an expert at a specific task by making it learn how to solve that particular job. It's like training it to be a pro at that one thing. And sure, it'll excel at that task, but it might struggle with anything else you throw at it.
Now, when it comes to supervised fine-tuning (SFT), it's a bit different. We're not training the model for a specific task. Instead, we're kind of nudging it to adopt a certain style or behavior. It's like teaching it to speak in a particular way or act in a particular manner, but we're not pigeonholing it into just one task. So, this type of model doesn't lose its general problem-solving abilities, which is pretty cool, don't you think?
We can clearly see that despite of computationally inexpensive the only challenge with supervised fine-tuning is to create a high-quality demonstration dataset. So let’s discuss that in brief.
Creating a dataset for fine-tuning those massive language models is quite the journey, and it's done either by expert team or a community of domain experts. They put in the manual effort to make it happen.
We're not just throwing words together, though. We've got some guidelines in place. They're like our GPS, showing us the way to format, structure, and even the behavior we want in the responses.
Such demonstration SFT dataset should be diverse in terms of tasks, prompt types, prompt lengths, response, response type, language, domains, etc. But putting all this together is no walk in the park. It's a bit of a challenge, and it takes a good chunk of time. Imagine collecting thousands of prompts and responses – that's what we're dealing with.
This dataset needs to be created by domain experts to ensure factual and helpful information in the response and by experienced content writers to ensure the writing style, response format, and unbiased response.
Let’s talk about the diversity in the demonstration dataset in depth.
Let’s talk about different diversities to keep in mind while creating the demonstration dataset.
When it comes to using Large Language Models (LLMs), we're all in for a variety of tasks. During the SFT stage, it's crucial that our LLM responses match the desired style, format, and behavior for all these tasks. Our demonstration dataset should cover a wide range of prompts and responses for these tasks. Let's dive into what these tasks include:
This one's all about letting the LLM's creative juices flow. You ask it to come up with a unique piece of content, and it gets those gears turning
Sometimes, we just need some fresh ideas. So, in this task, the user asks the LLM to help them brainstorm ideas for a given situation. It's like a virtual brainstorming buddy. Check out our brainstorming type of prompt and response dataset.
Imagine having a virtual encyclopedia at your disposal. You can ask the LLM a question based on established concepts or theories without giving any context, and it provides an answer. Check our open-ended question-answer prompt and response dataset.
Maybe you've got some content, but it needs a makeover. In this task, you ask the LLM to rewrite a piece of content according to specific characteristics and requirements. It's like having a content editor on standby.
When you need to condense a long piece of content, the LLM can summarize it for you.
This is for when you have data, but you haven't categorized it yet. You can ask the LLM to classify the data without predefined categories. Checkopen-ended classification prompt and response dataset.
Sometimes, you've got data, and you want to categorize it into predefined categories. The LLM can do that for you efficiently. Explore closed-ended classification prompt and response dataset.
You have a question, and you provide a context paragraph. The LLM can extract the answer from that context. Check our closed-ended question-answer prompt and response dataset.
If you need specific information from a chunk of data, the LLM can extract that information for you. Check out our extraction type of prompt and response dataset.
When we need an answer to a math word problem, common sense question, complex question, or any reasoning problem and need step-by-step explanation and reasoning to get that answer we can use a chain of thought type of prompt. Have a look at our chain of thought type of prompt and response dataset.
Users may ask the prompt in different types to get the response for any particular task. These prompt types can be
When you use an instructive prompt, you're basically telling the model what to do. It's the go-to method for most users when they interact with LLM. For instance, you might say, "Summarize the key points of the article."
With a continuation prompt, you can either start your request with an incomplete sentence or specify the starting point for the response. For example, you could say, "Starting from 'In the beginning,' please continue the text."
This is where things get interesting. In this type of prompt, you can provide some examples or context to help the model understand your task better. For instance, you might give a couple of examples related to a specific task and then ask the model to perform that task.
Ourprompt and completion supervised fine-tuning dataset should include examples of all these types of prompt types.
The prompts and response pairs should be diverse in terms of domains. This means it should contain examples from a broad range of domains like business, marketing, healthcare, history, geography, culture, literature, religion, politics, entertainment, etc.
When putting together your demonstration dataset, it's essential to include prompts of various lengths. This means having short ones (less than 100 words), medium-sized ones (ranging from 100 to 500 words), and long ones (more than 500 words).
This diversity in prompt lengths is super important because it allows us to cover a wide range of examples for different types of prompts and writing styles.
The response can also be different for different tasks like one word, short phrase, single sentence, and descriptive. However, as LLM responses we mainly focus on producing descriptive responses where we have enough space to provide in-depth information and context to be helpful to the user.
When we're coming up with prompts for our SFT dataset, it's important to make them feel like they're coming from real people. That means we need to include prompts with scene setting, constraints, and persona restrictions as well.
Scene Setting: Instead of just firing off a plain, direct question, we give our LLM a bit of background info. This helps the model better grasp what we're asking for. It's like setting the stage for a conversation.
Constraints: This is where we nudge our LLM in a particular direction. We give it some rules to follow or specific instructions to make sure the responses align with what we're looking for.
Persona Restrictions: We can ask our AI to respond like a certain character/persona or produce a response for a particular persona. It's like asking it to put on a different hat and change the way it talks, the words it uses, and even the format it uses.
We can see that fine-tuning LLM can be really a challenging task just because of the extensive diversification and efforts required to produce the demonstration dataset. The entire effort involves multiple stakeholders ranging from an internal team, a data partner team (domain experts, review team), and an AI team. It's a whole collaborative effort. Let’s briefly explore the process of creating a demonstration dataset.
So, I'm going to walk you through the process of creating a prompt and response dataset. It's quite a journey involving various stages and different people working together.
At this stage, the internal development team gathers the requirement and finalize the diversification needed for their SFT efforts. The team might come up with an idea like we need to produce prompt and response pairs for generation, rewrite, classification, and summarization task only which includes instructive, continuation, and incontext learning type of prompts that is diverse in terms of prompt length, domain and responses should be descriptive only.
The next step involves creating clear guidelines, typically in collaboration with external data partners like FutureBeeAI. These guidelines should outline the expectations for prompt and response writing, format, domain, and ethical considerations. Defining these guidelines is crucial for maintaining consistency and quality in the dataset.
Once the guidelines are in place, FutureBeeAI onboards domain experts to start generating prompt and response pairs according to the specified diversification and guidelines. The focus here is not only on producing high-quality prompts and responses but also on performing specific annotations for each pair. Annotations include categorizing prompts and responses based on prompt type, prompt length, task type, response type, and other relevant attributes.
After the prompt and response generation, there is a critical review process. First, a data partner’s internal team of experts examines the entire dataset to ensure its quality and compliance with the established guidelines. Subsequently, the dataset is forwarded to the client AI team for further review and feedback.
Feedback from both the internal and client teams is used to make necessary adjustments to the processes, guidelines, and overall approach. Depending on the project's requirements and needs, internal and external QA may be repeated on new batches of data to maintain quality standards.
At this stage, the final or milestone-based dataset should be delivered to the AI team for deployment.
I am sure after our intense discussion on supervised fine-tuning we are all agreeing on three points.
Firstly, supervised fine-tuning plays a crucial role in creating accurate and user-friendly large language models.
Secondly, a demonstration prompt and response dataset is a vital component of the supervised fine-tuning process.
Lastly, constructing a diverse and representative high-quality demonstration dataset is a complex and time-consuming task.
Now, imagine having someone like FutureBeeAI by your side to assist you in obtaining off-the-shelf or custom prompt and response datasets in your preferred language and tailored to your specific needs. This could significantly simplify your workflow. You can check all available OTS prompts and response datasets here.
Thanks to our multilingual, ready-to-deploy prompt and response datasets, you can easily streamline the supervised fine-tuning of your language model. What's more, with our global community of domain experts and prompt engineering specialists we can create unbiased and high-quality custom prompt and response datasets.
No matter where you are in your journey with your language model, don't hesitate to reach out to us today. We're here to offer expert support for all stages, from pre-training and supervised fine-tuning to reinforcement learning with human feedback. Let's work together to make your project a success!
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





