Large language models are the talk of the town, dominating headlines and sparking conversations at every corner. With all our curiosity about how these models are being developed who doesn’t want to know the nitty-gritty of the development phases of these large language models?
Have you ever wondered how these colossal language models, with billions of parameters, come to life? Today we are going to uncover each phase of LLM development in detail.
But before we start we need to first establish our guiding star on what we want to achieve with large language model in general. These language models are here to serve, to provide us with completions and responses that are not just intelligent but also imbued with a sense of ethics. We're talking about responses that are Helpful, Harmless, and Honest – the coveted 'HHH' trifecta.
With that being clear now let’s deep dive into development phases now.
Different Phases of LLM Training
Imagine building a language model is like baking a perfect cake. You don't just mix all the ingredients in one go and hope for the best. Instead, you follow a precise recipe, layering flavors and textures step by step until you achieve a masterpiece.
Similarly, large language models (LLMs) undergo a journey of development, a perfect recipe for innovation. This development phase includes:
1) Pre-training
2) Supervised Fine Tuning
3) RLHF
Let’s talk about each of these in detail
 [Courtesy to twitter.com/anthrupad]
[Courtesy to twitter.com/anthrupad]
Pre-training
In this phase of model training, it has been fed with a vast amount of data available on the internet. Picture this vast ocean of data, an endless stream of words, phrases, and ideas pouring in from sources as diverse as high-quality data from Wikipedia's wisdom to the chaotic and low-quality data from Reddit and other user forums.
At this point, your language model is like an eager sponge, soaking up the personalities of billions of people from countless digital channels. It's trying to mimic them all, to understand how they speak and think.
But if you were to ask LLM a question or throw a prompt at it just after its pre-training phase, you might get a response that's a bit... unpredictable. It's not entirely sure what's factual or accurate, so you might get some answers that are, well, a bit off.
But that’s okay because, in the pre-training phase, our purpose is quite different. At this stage, we want to train our LLM to learn how to predict the next word and produce a completion from all the provided training data from the internet.
All the different levels of tasks that we are doing with LLM like ChatGPT in our regular life are nothing but completion tasks. For example, you give “How are you in Spanish is” as a prompt for the model, and for the model it is nothing else but a filling-the-blank. It tries to fill in the blank and come up with “Cómo estás”.
Similarly, other tasks like summarization, brainstorming, classification, extractions, and others are nothing else but completion tasks.
So, after this initial phase of pre-training, your model can generate responses that are, well, a bit hallucinatory. They might not always make sense, and they might not be the most helpful, honest, or harmless. It's like you've handed the keys to a car to someone who's never driven before.
At this stage, the LLM doesn’t know what exactly the user is looking for and it doesn’t have enough knowledge on how to produce a well-written response that makes sense to the user.
That's why we move on to the next step: supervised fine-tuning (SFT). It's here that we teach our AI some manners and give it a sense of direction in the world of language!
Supervised Fine Tuning aka SFT
It is the phase where pre-trained model is being fine-tuned to produce more coherent and meaningful responses.
As seen earlier, pre-training gives the capability to LLM to produce a completion and a pre-trained model is nothing else but a completion machine at its core.
Now let’s say you ask pre-trained language model:
“How to ride a horse” as a prompt.
As the pre-trained model is a completion machine it does not know exactly what the user is asking for. It will consider it as a fill in the blank and may come up with anything like:
Scenario 1: How to ride a horse in the forest?
Scenario 2: How to ride a horse like an expert?
Scenario 3: How to ride a horse I am new to this.
Scenario 4: Or, if luck is on your side, it might just offer a straightforward answer on the art of horse riding.
Scenario 4 is what actually optimum for the user and at this phase of SFT, we actually want to train LLM to come up with scenario 4-like results in every case.
The magic happens during the supervised fine-tuning phase of large language model development. Here, we're not teaching it new tricks but refining its talents. Think of it as a performance rehearsal, where we guide the model to produce responses that align with what users are actually looking for.
To fine-tune the LLM to generate the most accurate and meaningful form of answer we use human-generated demonstration data. We provide examples of prompt and response pairs to the LLM on how to respond appropriately for different use cases.
But what exactly is this "demonstration data," you ask? Well, let's dive in and find out.
What is Demonstration Data in SFT?
The demonstration dataset is the collection of human-generated responses to the sample prompts. To build this dataset, we can use prompts from sample datasets, real user queries, or even prompts conjured up by our very own human creators.
We use a highly qualified human workforce that includes domain experts and language experts to prepare the most meaningful responses to the given prompts. This demonstration dataset contains the prompt and completion pairs for different use cases that include generation, question answer, classification, summarization, rewrite, extraction, brainstorming, etc.
Now, here's where it gets interesting. We don't just grab any old humans off the street for this task. Oh no, we enlist the help of highly qualified individuals, including domain and language experts. These brainiacs work their magic to provide the most meaningful responses to a wide range of prompts. We're talking about prompts that cover everything from generating text, answering questions, classifying information, summarizing content, rewriting sentences, extracting knowledge, brainstorming, and whatnot.
Why do we go through all this trouble? Well, it's all about teaching our AI models how to respond like a pro. Think of it as cloning the style of these domain and language experts. This phase is even referred to as – "behavior cloning." We want our models to learn the ropes, understand what's expected in response, and become masters of their craft.
Now, here's the twist – during this phase, we're not so concerned about preventing LLMs from going all hallucinatory. Nope, our main focus is on getting them to generate responses in a constructive and meaningful way. We're not adding new data to their internal knowledge base here; we're just showing them how to make the most of what they already know.
So, if you give a prompt to a LLM post-SFT, it might just whip up a response that's well-structured and makes sense. But here's the catch – we can't guarantee it'll always be accurate or ethically sound. To tackle that, we'll need to delve into the realm of reinforcement learning from human feedback within the LLM space.
Reinforcement Learning from Human Feedback
In our previous blog post on “Reinforcement Learning” we dipped our toes into the waters of reinforcement learning and discovered its pivotal role in bridging the gap left by supervised learning.
It allows the model to receive a reward or penalty on its output and build an optimal reward policy. Based on it, the model tries to produce output that is most acceptable for the users and has a maximum reward associated with it.
We have also seen that there are some limitations of standard reinforcement learning in the LLM space because of LLM’s high sample complexity and safety and ethical concerns.
Now, traditional reinforcement learning is like a chef perfecting a recipe through endless trials in the kitchen. It experiments, sometimes resulting in a mouthwatering masterpiece, while at other times, creating culinary catastrophes.
Reinforcement learning develops its optimal reward policy after enough number of iterations. In these iterations, the model may produce unacceptable outputs as well. For LLMs developing this optimal reward policy can be even more complex due to its high sample complexity.
This trial-and-error method of traditional reinforcement learning can be dangerous in real life for LLMs as it may produce unethical, toxic, and misleading responses. So we need something to add up in the traditional reinforcement learning to catch up with these limitations of traditional reinforcement learning.
This additional element is “Human feedback” in the traditional RL system which makes the very important phase of Reinforcement Learning from Human Feedback in LLM training.
RLHF phase is where we further train the SFT model on producing good-ethical responses as in SFT we are training the model to generate a plausible response but not focusing on how good it is.
In RLHF we are basically performing two tasks; one in which we are training a reward model and the other in which we are optimizing the language model to generate responses to which the reward model gives high scores.
The reward model is a scoring mechanism that later trains the LLM to produce responses with higher scores. Let’s talk about the reward model in a little more detail.
Reward Model & Fine Tuning SFT Model
For a reward model to produce a score for a pair of a prompt and response, we need to train it on comparison data. Now what is this comparison data? Let’s understand.
Comparison data is a curated collection of prompts, paired with both winning and losing responses, labeled by human evaluators. The process starts by selecting prompts from a pool of prompt samples. Then multiple responses are generated by LLM on these prompts.
Human labelers are entrusted with the task of ranking these generated responses according to specific guidelines. These guidelines are like the North Star, guiding the labelers on how to assess and rank the responses. The guidelines hinge on the purpose of training the reward model. Are we seeking factual accuracy, non-toxicity, or some other criterion? It all depends on the desired outcome.
Multiple human labelers independently evaluate these responses, and their collective wisdom is used to calculate an average rank for each response. This intricate process forms the foundation for training the reward model.
Let’s understand it with an example:
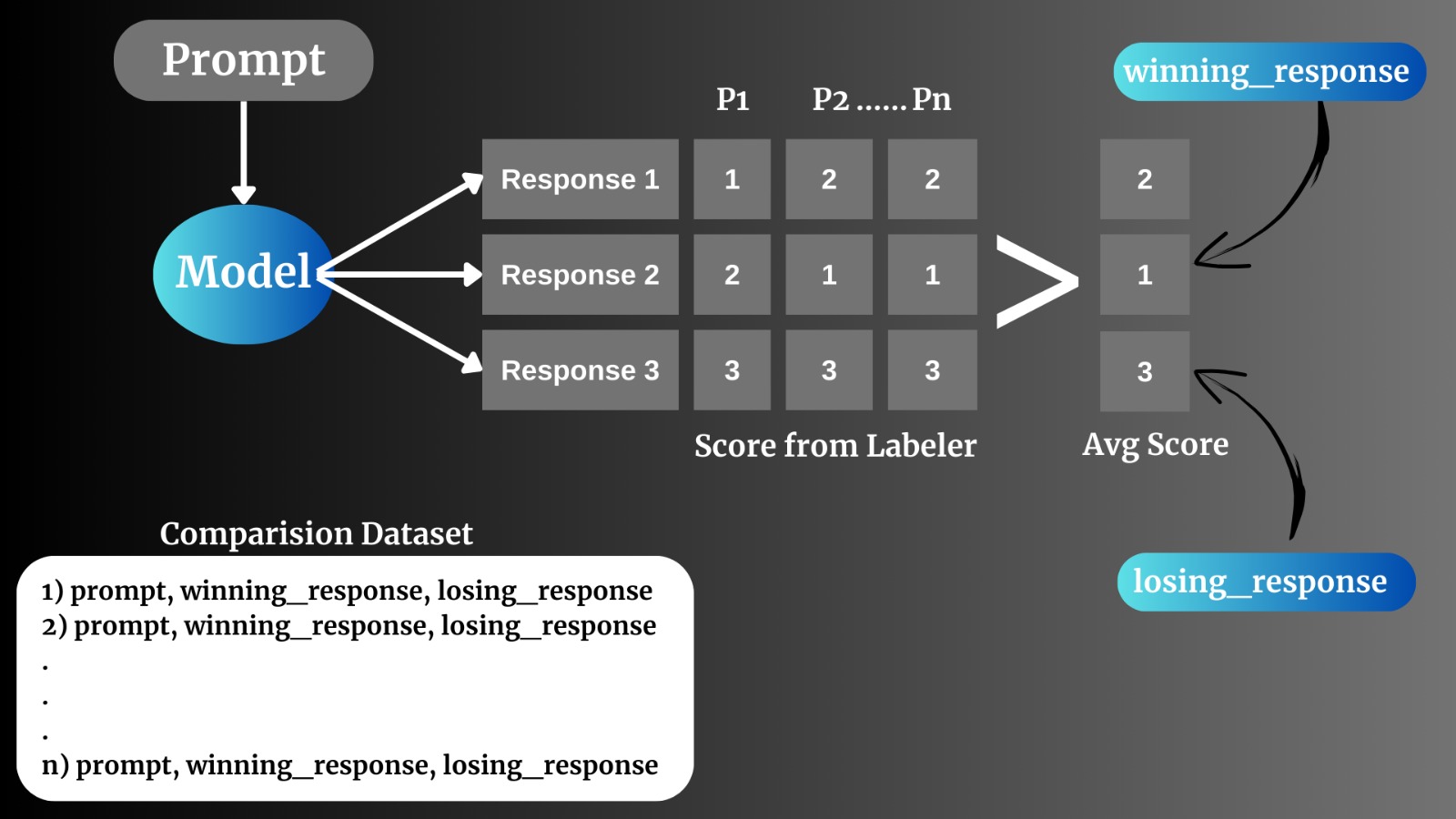 As you can see in this image model “M” generates 3 responses R1, R2, and R3. These generated responses are then sent to different labels and they give rank to these with their intelligence.
As you can see in this image model “M” generates 3 responses R1, R2, and R3. These generated responses are then sent to different labels and they give rank to these with their intelligence.
Based on all these ranks for these responses, the average rank is taken out as shown in the above image. Then the comparison dataset is prepared. As in this example response 2 is winning_response and response 3 is losing_response considering score 1 as the best response and score 3 as the worst response.
Later this comparison dataset is being used to train the reward model to give a scoring to LLMs responses accurately. Once the reward model has been honed to perfection, it steps onto the stage to fine-tune the SFT model.
In the process of fine-tuning the SFT model on the reward model, random prompts are being used from a vast distribution including actual user prompts. Then SFT model is asked to generate a response to these prompts. For each response, the reward model provides a score for the generated response. In this way SFT model is fine-tuned to produce responses that can get positive rewards in terms of scores from the reward model.
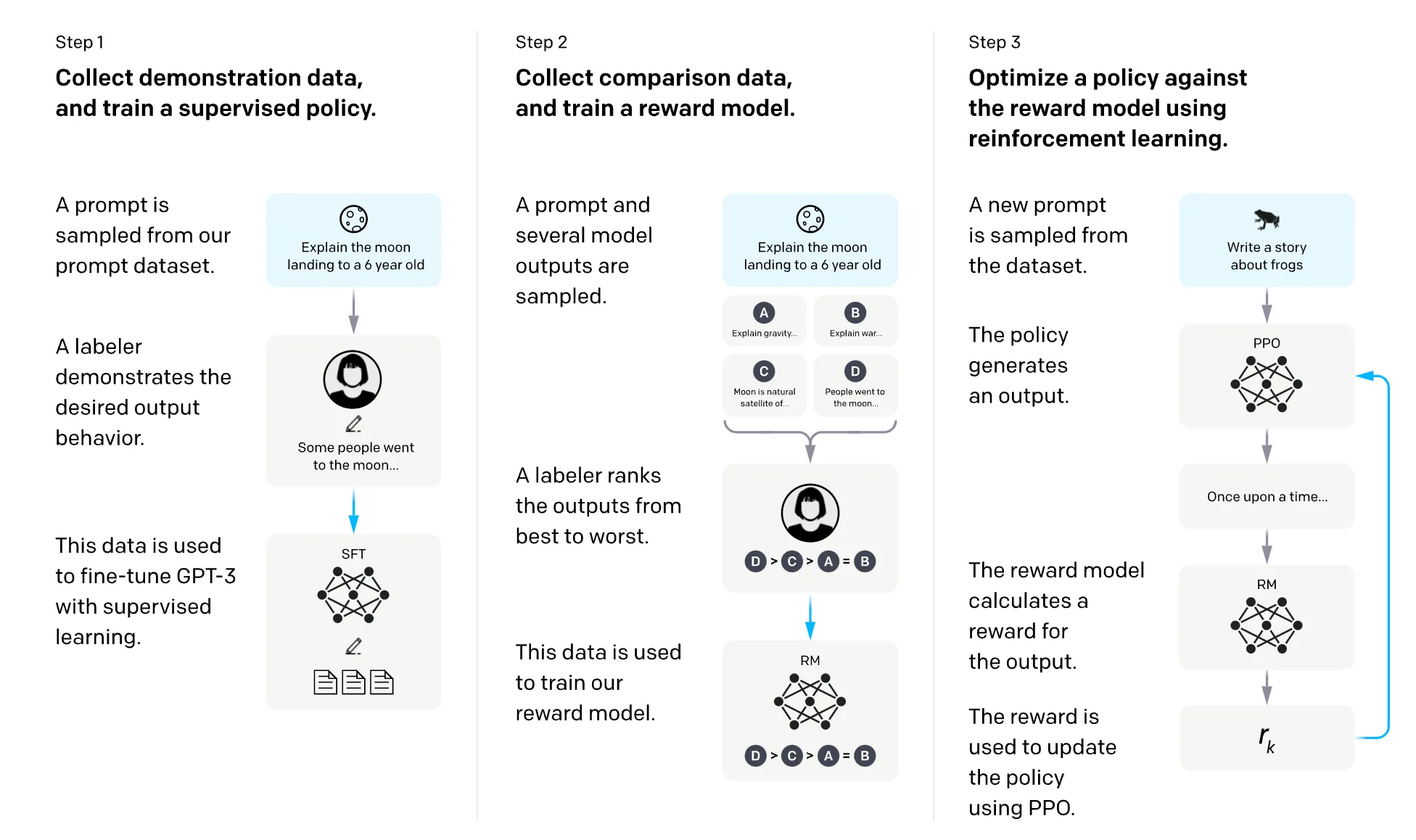 [Courtesy to openai.com]
[Courtesy to openai.com]
And that is how reinforcement learning with human feedback works in the landscape of large language models. Each of these phases of development has its own unique purpose and combined they all work in a direction to produce responses to users' queries that fulfill the HHH trifecta; helpful, honest, and harmless
Conclusion
 It’s clear that the journey of training a large language model is a complex one, filled with intricate phases that carry immense importance. Having a data partner and a crowd community of domain experts with language and cultural diversity is nothing short of a blessing.
It’s clear that the journey of training a large language model is a complex one, filled with intricate phases that carry immense importance. Having a data partner and a crowd community of domain experts with language and cultural diversity is nothing short of a blessing.
Here at FutureBeeAI, we stand ready to help you with your LLM endeavors. Our global crowd community is a collection of domain experts from various fields like technology, coding, mathematics, science, history, culture, etc from all around the globe covering more than 50+ languages.
Equipped with our in-house team of RLHF experts, we're prepared to assist you in crafting RLHF guidelines, assembling your dream team of domain experts, and scaling your RLHF project to new heights.
But our commitment doesn't stop there. We are continuously involved in preparing large-scale demonstration datasets in more than 40+ languages with our expert crowd community to help you scale your LLM’s supervised fine-tuning process. You can check out all published demonstration prompt and respones datasets here.






