In the ever-evolving landscape of generative artificial intelligence, language models have emerged as revolutionary tools, fundamentally changing the way we interact with technology. Today, prominent models like chatGPT, Claude, and Bard have become integral parts of our lives, assisting us with a wide array of tasks and inquiries.
Whether it's unraveling complex questions, providing insights on diverse topics, crafting imaginative narratives, or even generating code, these AI-powered systems have showcased their remarkable versatility and practicality.
As these language models gain increasing popularity, you may have encountered the terms "prompt" and "completion." These seemingly simple words, in fact, play a pivotal role in how language models operate and deliver their outputs. In this blog, we'll delve into the essence of prompt and completion, uncovering their profound significance in shaping the capabilities of large language models.
But before we dive deep into prompt and completion, let's take a moment to understand what a large language model entails.
What is a Large Language Model?
Large language models represent the cutting edge of artificial intelligence, specifically in the domain of natural language processing (NLP). These advanced systems are built upon deep learning architectures and are trained on massive datasets to develop an extensive understanding of human language and context.
As a result, they have the remarkable ability to generate human-like text and perform a wide range of language-related tasks, including translation, summarization, creative writing, and even code generation.
The "large" in large language models refers to the enormous amount of training data and parameters they use during their training process. The more data and parameters a model has, the more comprehensive its understanding of language becomes, enabling it to handle complex language tasks with greater accuracy and finesse.
The strength of large language models lies in their ability to generalize from the vast amounts of data they've been exposed to during training. By understanding the underlying patterns and correlations in language, these models can adapt to various tasks and produce high-quality outputs for different inputs.
However, it is crucial to note that the effectiveness and accuracy of these models heavily rely on the quality and diversity of their training data. Biases and inaccuracies in the training data can inadvertently influence the model's responses, leading to potential challenges in certain applications.
Applications of Large Language Models
Large language models have a wide range of practical applications that showcase their capabilities. Below are some fundamental use cases:
Natural Language Understanding:
Large language models excel in tasks involving the comprehension and interpretation of human language. This includes tasks like sentiment analysis, named entity recognition, and text classification.
Language Translation:
Empowered by large language models, translation models facilitate seamless language translation, breaking down barriers and enabling smooth cross-lingual communication.
Text Generation:
Large language models possess the ability to generate coherent and contextually appropriate text, making them invaluable for applications in creative writing, content generation, and even poetry.
Code Generation:
Harnessing the power of large language models allows for automated code generation, streamlining tasks for software developers and significantly enhancing their productivity.
Now let’s understand what a prompt is.
What is Prompt in the Large Language Model?
In the realm of large language models, a prompt refers to the initial input given to the AI system. It serves as the starting point for the AI to generate a specific response. By providing a prompt, we direct the AI's text generation process toward a particular outcome. The prompt can take various forms, such as a sentence, a phrase, or a set of keywords, and it helps set the context for the AI's completion.
Think of prompts as a way to instruct the language model to perform specific tasks. Instead of coding in a programming language, you achieve your desired result by using regular English words and text.
So, when you interact with your favorite large language models like chatGPT, Bard, or Claude, the initial inputs you provide to them are referred to as prompts. Here are some examples of prompts that you might encounter in your daily interactions with these language models:
Question Answering
What are the symptoms of COVID-19? Provide a detailed list of common and severe symptoms associated with the virus.
Creative Writing
Write a short story about a time traveler who accidentally changes a significant historical event and must find a way to restore the original timeline.
Sentiment Analysis
Please analyze the sentiment of customer reviews for ProductX. Provide a summary of the overall sentiment and any key recurring themes or concerns.
Classification
Given a dataset of emails, classify them into categories - 'Spam,' 'Promotions,' and 'Personal.'
The prompt's role in shaping AI-generated text is crucial. When users provide a well-crafted prompt, they can influence the language model's response and ensure that the output aligns with what they want. The effectiveness of the prompt lies in its ability to convey the desired context and constraints, which direct the language model's creativity in a focused manner.
The process of writing an effective and well-crafted prompt that produces accurate and desired responses is known as prompt engineering. Prompts can be classified in various ways, but the most prominent classification is based on the level of guidance they provide. So, let's explore different types of prompts based on their level of guidance.
Different Types of Prompts for Language Model
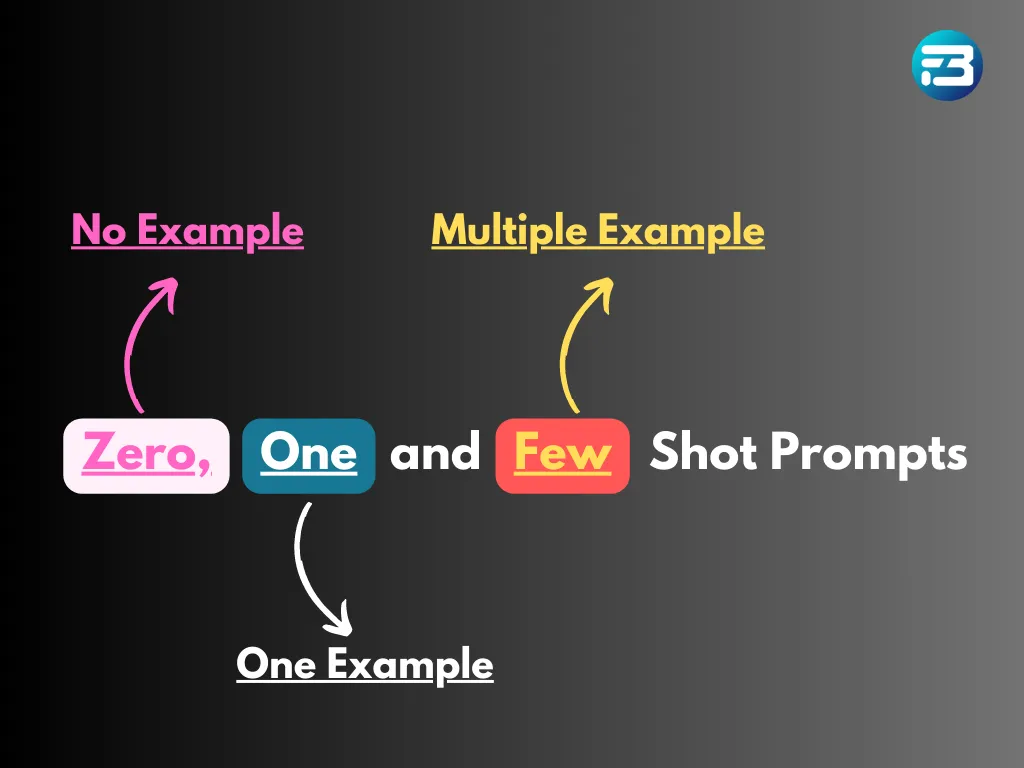 Zero-shot prompt
Zero-shot prompt
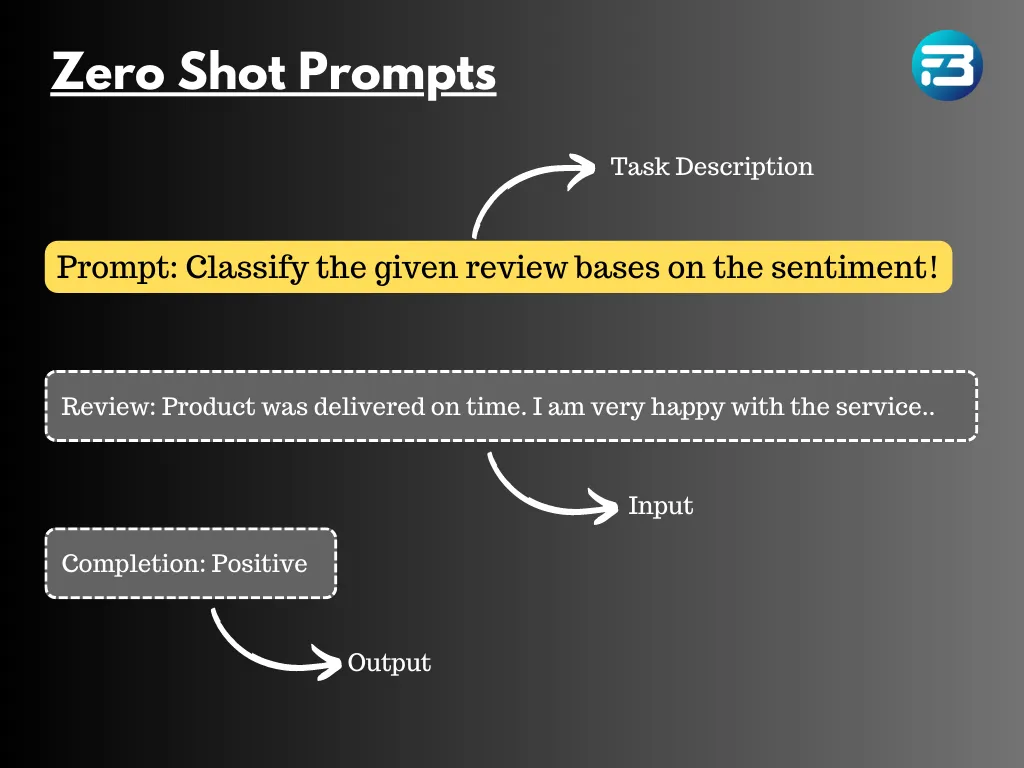
A zero-shot prompt is a basic form of instruction given to a language model. It involves providing a description of a task or some initial text to get the language model started. The prompt can take various forms, such as a question, the beginning of a story, or even instructions. It is essential to make the prompt text clear, as this helps the language model better comprehend what output is expected.
In a zero-shot prompt scenario, the language model does not receive explicit information about the task or the desired response. Instead, it relies solely on the context provided by the user's prompt to generate a reply. This context can be as simple as a few keywords, a sentence, or a question. Despite the lack of explicit guidance, the language model utilizes its extensive pre-trained knowledge to infer the desired completion. This showcases the remarkable ability of the language model to process and understand human language effectively.
 Limitations of Language Models for Zero-Shot Prompts:
Limitations of Language Models for Zero-Shot Prompts:
Ambiguity:
When using language models for zero-shot prompts, there is a lack of explicit conditioning, which can lead to the generation of ambiguous or less accurate responses for certain tasks. Without specific guidance, the model may produce outputs that are not precisely tailored to the intended context.
Out-of-Distribution Inputs:
If the zero-shot prompt contains words or concepts that are outside the training distribution of the language model, the generated completions might be less coherent or contextually appropriate. Language models rely on the patterns and information present in their training data, so encountering unfamiliar terms can pose challenges.
Domain-Specific Knowledge:
Language models trained for zero-shot tasks might struggle with assignments that demand domain-specific knowledge not covered in their pre-training data. Without exposure to specialized information, the model's responses may lack accuracy and relevance in tasks that require expertise in particular fields or industries.
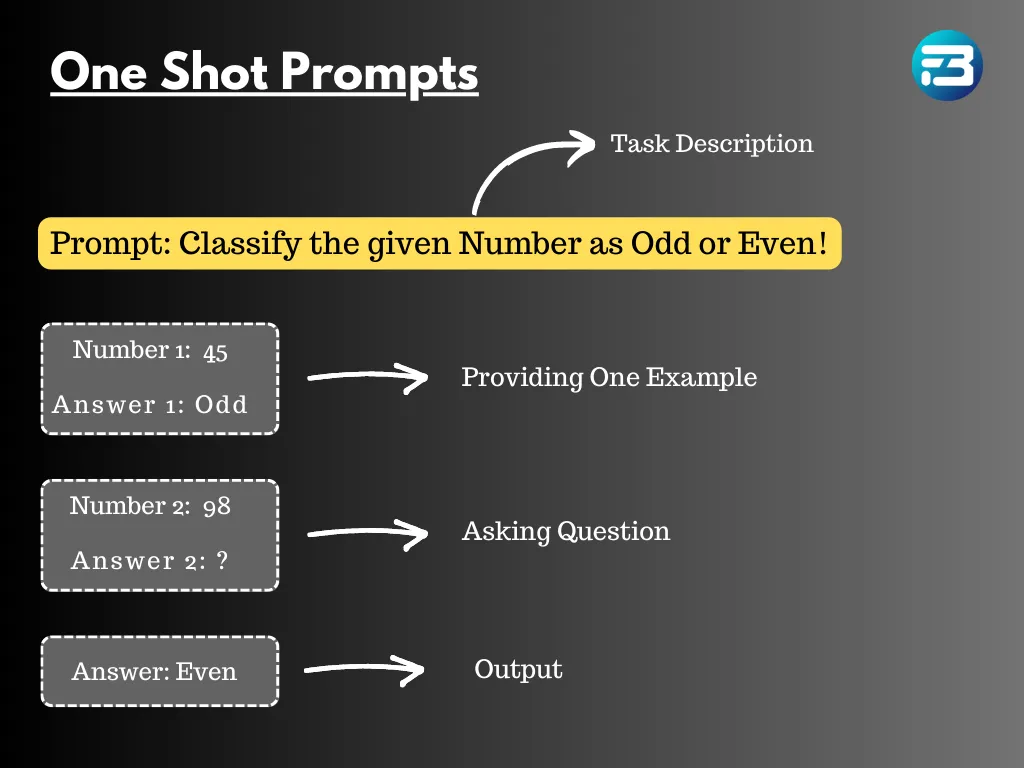
One-shot prompt
A one-shot prompt is an example used to train a language model on how to complete a specific task effectively. In the field of large language models and natural language processing (NLP), a one-shot prompt is a particular type of input that provides the AI system with just one example as a cue to generate a specific response.
It serves as a guiding signal, nudging the language model to follow a specific pattern or format while generating text. The objective of using one-shot prompts is to direct the AI's output towards a desired context or style, making it a powerful tool for various text generation tasks.
 Limitations of Language Models with One-S hot Prompts:
Limitations of Language Models with One-S hot Prompts:
Limited Context:
When using one-shot prompts, language models receive only a single example to process, which might not be enough to fully grasp the context or complexity of a given task. Consequently, the AI's output might lack the necessary depth and accuracy required for tasks that involve intricate details or nuanced information.
Ambiguity:
One-shot prompts are prone to ambiguity because a single example might not encompass the entire range of possibilities or variations needed for the desired output. This ambiguity can lead to inconsistent or unintended responses from the language model.
Specificity:
In certain cases, one-shot prompts might lack the specificity needed to guide the language model accurately towards the desired response. For tasks that require precise and detailed outputs, a single example may not provide sufficient information, making it challenging for the AI to generate accurate completions.
Overfitting:
Over-reliance on one-shot prompts can lead to overfitting, where the language model becomes too dependent on the provided example and struggles to adapt well to new or slightly different inputs. This limitation can hinder the model's ability to handle diverse contexts effectively.
Complexity of Tasks:
One-shot prompts may not effectively guide language models in generating multi-faceted completions, especially for tasks that involve multiple steps or require intermediate information to arrive at the correct answer. The lack of additional context can limit the model's performance on more complex tasks.
Few-shot prompt
Few-shot prompts are a crucial concept in the realm of large language models. These prompts involve presenting the language model with a some number of examples to guide its response. Unlike zero-shot prompts, where the AI has complete freedom without any conditioning, or one-shot prompts, which provide just a single example for guidance, few-shot prompts strike a balance between flexibility and specificity.
By providing multiple examples, typically ranging from tens to hundreds, the few-shot prompt allows the language model to discern patterns and gain a better understanding of the task it needs to perform. This learning from multiple examples can significantly enhance the quality of the model's completions.
The significance of few-shot prompts lies in their ability to enable language models to carry out specific tasks with minimal examples. Instead of requiring an extensive dataset for training, few-shot prompts leverage the power of transfer learning to grasp the context and requirements of a task, even with limited data.
This approach becomes particularly advantageous in scenarios where data availability is scarce or when users want to prompt the model with specific instructions or conditions. Few-shot prompts offer a practical and efficient way to instruct language models and obtain accurate responses without the need for extensive training data.
 Advantages of using Few-Shot Prompts for Language Models (LLMs):
Advantages of using Few-Shot Prompts for Language Models (LLMs):
Rapid Adaptation:
Few-shot prompts enable LLMs to quickly adapt to new tasks and contexts. By providing the model with a small set of examples, it can swiftly adjust its parameters and fine-tune its knowledge to suit the specific task at hand. This adaptability ensures that LLMs remain relevant and up-to-date in dynamic environments where tasks and requirements frequently change.
Cross-Lingual Tasks:
LLMs equipped with few-shot prompt learning can effectively handle cross-lingual tasks. With just a small number of examples in different languages, the model can generalize and perform tasks in languages for which extensive training data might not be available. This cross-lingual capability is especially valuable in global settings and multilingual applications.
Adaptation to New Domains:
Few-shot prompts allow LLMs to adapt to new domains with ease. By providing relevant examples or instructions from the target domain, the language model can quickly specialize its knowledge and generate contextually appropriate responses. This adaptability makes LLMs versatile tools that can cater to diverse domains and industries.
Generalization to Similar Tasks:
LLMs trained using few-shot prompts often exhibit improved generalization to similar tasks. The model can leverage the knowledge acquired from a small set of examples to perform well on related tasks, even without extensive training on each specific task.
Now, let's explore the concept of completion:
What is Completion in the Large Language Model?
A language model's completion refers to the process of generating text or output based on an initial input or prompt provided to the model. In this context, a language model utilizes its extensive knowledge and understanding of language to produce coherent and contextually relevant text as a response.
When we talk about completion, it means the text generated and returned by the language model as a result of the given prompt or input. Unlike some other NLP systems, the language models may not be pre-trained for a specific task during their initial training. Instead, the language model is a general-purpose language processing system. However, it can be taught to perform specific tasks using meta-learning.
Meta-learning, also known as "learning to learn," is a machine-learning technique where a model learns how to learn more efficiently or adapt quickly to new tasks. Instead of traditional machine learning approaches where models are trained for specific tasks using large amounts of labeled data, meta-learning focuses on training models to be able to learn from smaller amounts of data and generalize well to new tasks.
Meta-learning plays a crucial role in empowering language models to generate accurate completions or responses for tasks they may not have been pre-trained on with extensive data. One key aspect of meta-learning is "few-shot learning," which enables a language model to quickly learn the nuances of a new task from just a few examples provided in the prompt.
In few-shot learning, the prompt contains a small set of examples relevant to the task at hand. These examples act as the training data for the language model, allowing it to grasp the patterns and intricacies of the task. By analyzing and understanding these few-shot examples, the language model becomes capable of generating more accurate and contextually relevant responses for the given task.
This approach is particularly advantageous when dealing with tasks for which the language model has not been fine-tuned or explicitly trained. Instead of requiring a massive amount of labeled data specific to that task, few-shot learning leverages the model's meta-learning abilities to adapt quickly to new scenarios. This not only saves time and computational resources but also enhances the model's ability to perform well on diverse tasks without needing extensive retraining.
It's important to note that the success of few-shot learning heavily relies on the language model's ability to generalize from the provided examples and apply that knowledge to new, unseen tasks. The model's capacity to identify relevant patterns and relationships within the few-shot examples contributes to its effectiveness in producing accurate and coherent responses for a wide range of tasks.
Now that we have the basics covered, we can discuss the prompt and completion datasets.
What is Prompt and Completion Dataset?
A prompt-completion dataset is a valuable collection of prompt-completion pairs specifically designed to train and fine-tune large language models. Each pair consists of an initial input sequence (the prompt) and its corresponding high-quality and accurate completion. These datasets play a crucial role in teaching language models to grasp the context, generate relevant responses, and refine their behavior for specific tasks.
While training a large language model on an extensive corpus of text data is vital for acquiring general language patterns, grammar, context, and world knowledge, it may not always guarantee the desired outputs for specific prompts. This is where fine-tuning on prompt completion datasets becomes highly beneficial.
Fine-tuning involves taking a pre-trained language model like GPT-3 and exposing it to the prompt completion dataset. By doing so, the model can learn from the diverse set of prompts and corresponding completions, enabling it to adapt and specialize its responses for particular applications and tasks. This process enhances the language model's ability to provide more accurate and contextually appropriate outputs when given specific prompts.
Scale Your Language Model Endeavors With FutureBeeAI
Having a data partner like FutureBeeAI can provide essential support to scale and optimize your language model projects. With our assistance, you gain a competitive advantage by ensuring a robust and unbiased large language model through comprehensive and high-quality training datasets.
Our services encompass a wide range of language model-related tasks. Whether you require text datasets, prompt and completion datasets, annotation services, reinforcement learning with human feedback, or any other large-scale human-in-the-loop tasks, we have you covered!
No matter what stage you are at in adopting a large language model, we are here to help. Feel free to contact us today and let us alleviate the burden of training data with our end-to-end ecosystem of skilled global crowd communities, SOPs, and advanced tools.






