Overfitting
Underfiltering
Simplest Guide on Overfitting and Underfitting in Machine Learning
Learn the fundamental concepts of Overfitting and Underfitting with some real life examples. Explore causes of Overfitting and Underfitting.
Overfitting
Underfiltering
Learn the fundamental concepts of Overfitting and Underfitting with some real life examples. Explore causes of Overfitting and Underfitting.

Machine learning has had a tremendous impact on our ability to tackle complex problems by enabling us to develop models that can recognize patterns, make predictions, and learn from data. However, like any other tool, machine learning has its own set of challenges, such as overfitting and underfitting. These issues arise when our models become too complex or too simplistic, resulting in poor performance when faced with new data.
In this article, we aim to simplify the concepts of overfitting and underfitting so that readers can understand and avoid these pitfalls when developing models that can generalize to new situations. Regardless of whether you're a seasoned machine learning expert or just starting out, our guide will provide you with the essential concepts of overfitting and underfitting and their real-life occurrences. So let's get started on demystifying these two concepts that people often find confusing.
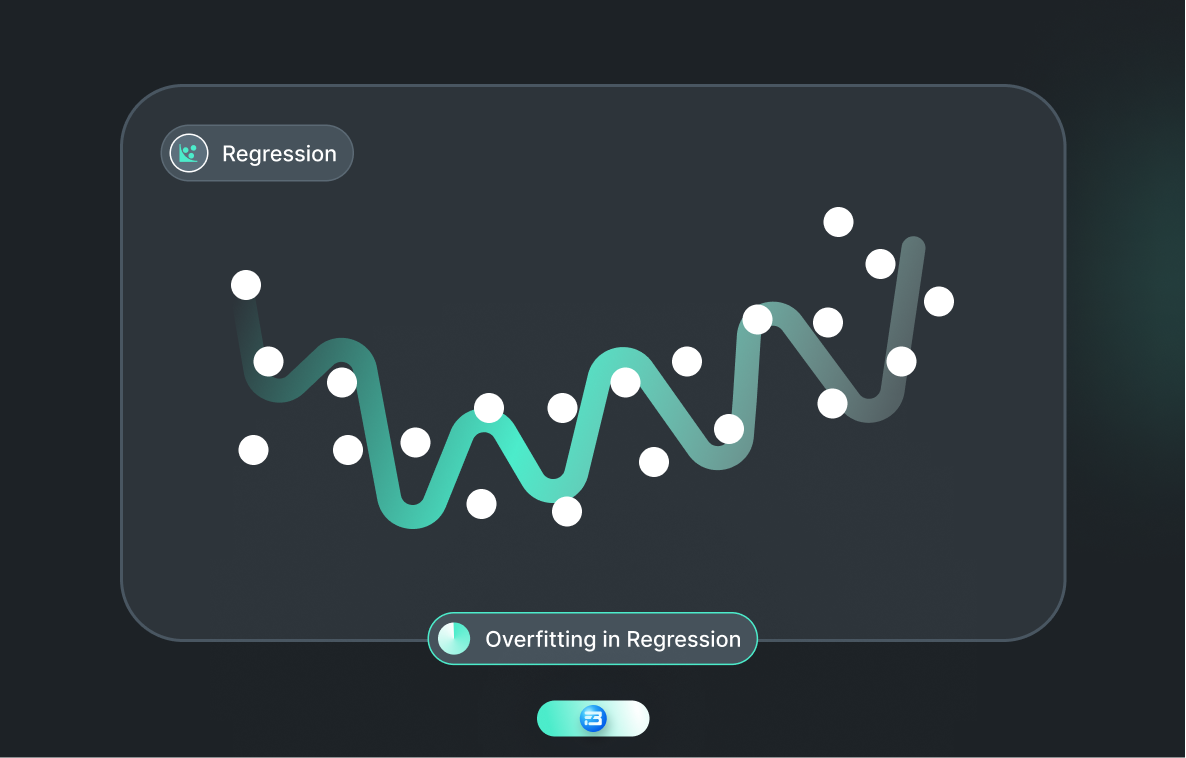 Imagine a student who can mug up any number of textbooks. He can memorize a textbook so well that you can recite it word for word, but when you're asked to apply that knowledge to a new problem, he is completely lost.
Imagine a student who can mug up any number of textbooks. He can memorize a textbook so well that you can recite it word for word, but when you're asked to apply that knowledge to a new problem, he is completely lost.
The same thing can happen with machine-learning models as well. Such models that perform exceptionally well on the training data but fail to maintain accuracy when encountering new data are referred to as “overfit models.”
So, overfitting is a common challenge in machine learning where a model becomes too complex and fits too well to the training data, resulting in poor performance on new or unseen data.
It occurs when the model captures the noise and random fluctuations in the training data, which can lead to a loss of generalization and an inability to make accurate predictions on new data.
You might be wondering what this complexity and generalization mean. Let's try to comprehend that.
Complexity in the context of machine learning refers to the level of sophistication or intricacy of a model. A more complex model has more moving parts and can capture more detailed patterns in the data. However, it can also be more challenging to interpret and use. Conversely, a less complex model may be easier to understand and use but may not capture as much information from the data.
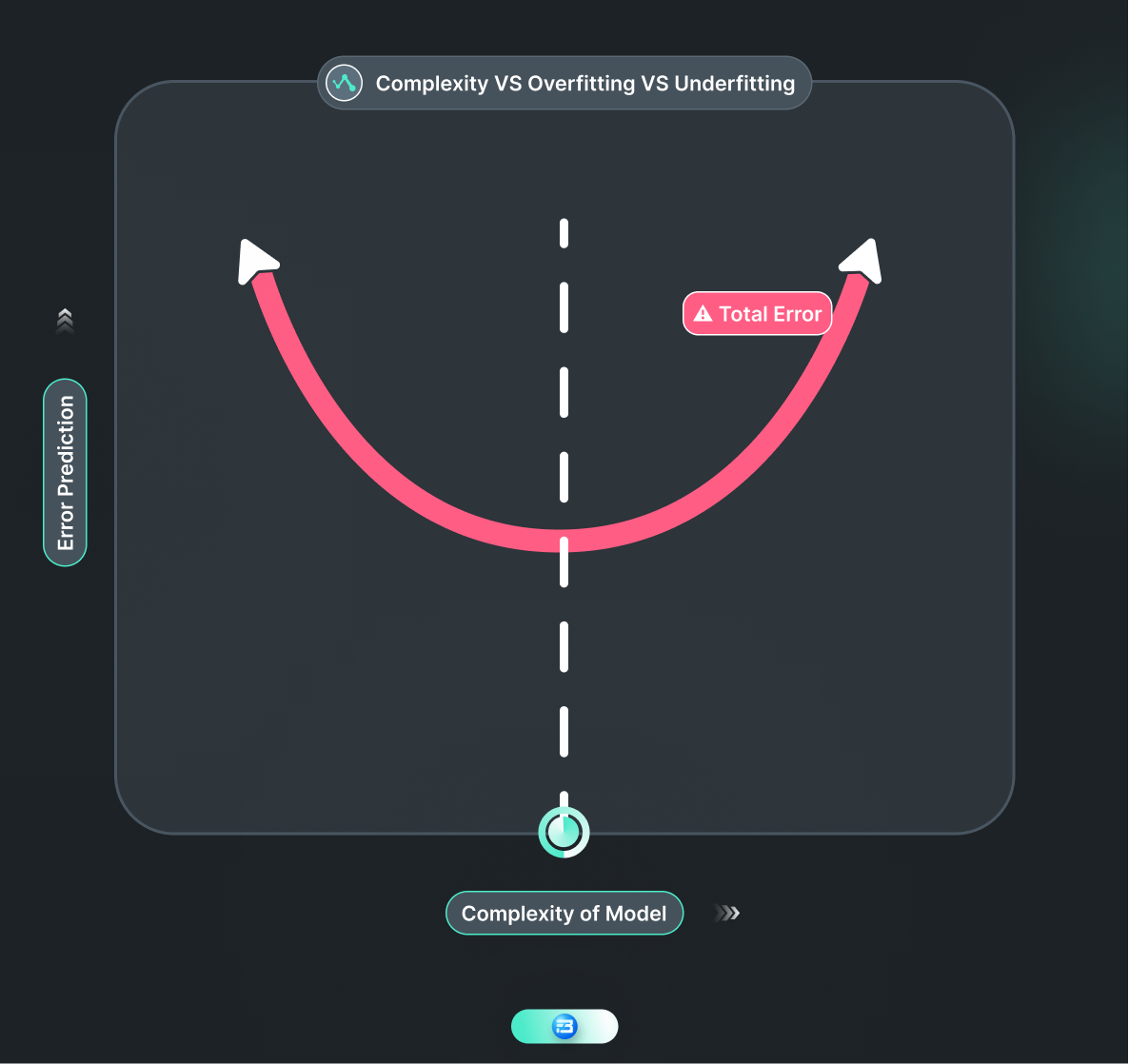 To measure model complexity, we consider the number of parameters or features the model has and how they are interconnected to make predictions. A complex model may have many parameters, layers, or nonlinear functions that can capture complex relationships and patterns in the data. In contrast, a simple model may have fewer parameters, layers, or nonlinear functions that may not capture the full complexity of the data.
To measure model complexity, we consider the number of parameters or features the model has and how they are interconnected to make predictions. A complex model may have many parameters, layers, or nonlinear functions that can capture complex relationships and patterns in the data. In contrast, a simple model may have fewer parameters, layers, or nonlinear functions that may not capture the full complexity of the data.
Imagine that you are trying to learn a new language. You could start by learning the basic vocabulary and grammar rules, but that might not be enough to have a conversation. Alternatively, you could study complex idioms and slang, but that might make it difficult to communicate with others.
In this scenario, the complexity of language learning corresponds to the complexity of a machine learning model. A more complex model may be able to capture more detailed patterns in the data, but it may also be more difficult to interpret and use. So neither a too-complex nor a too-simple machine learning model is ideal in this case. We need to find the right balance between both.
Generalization, on the other hand, refers to a model's ability to perform well on new, unseen data. To continue with the language learning analogy, let's imagine that you have learned the language and are now traveling to a new country where they speak that language. Some people might be easy to understand and speak slowly, while others might speak quickly with a strong accent.
In this scenario, the ability to understand different speakers of the language corresponds to the generalization of a machine learning model. A model with good generalization can apply what it has learned from the training data to new data and make accurate predictions. On the other hand, a model with poor generalization may have only memorized the training data and be unable to make accurate predictions on new data.
Now let’s understand what is underfitting.
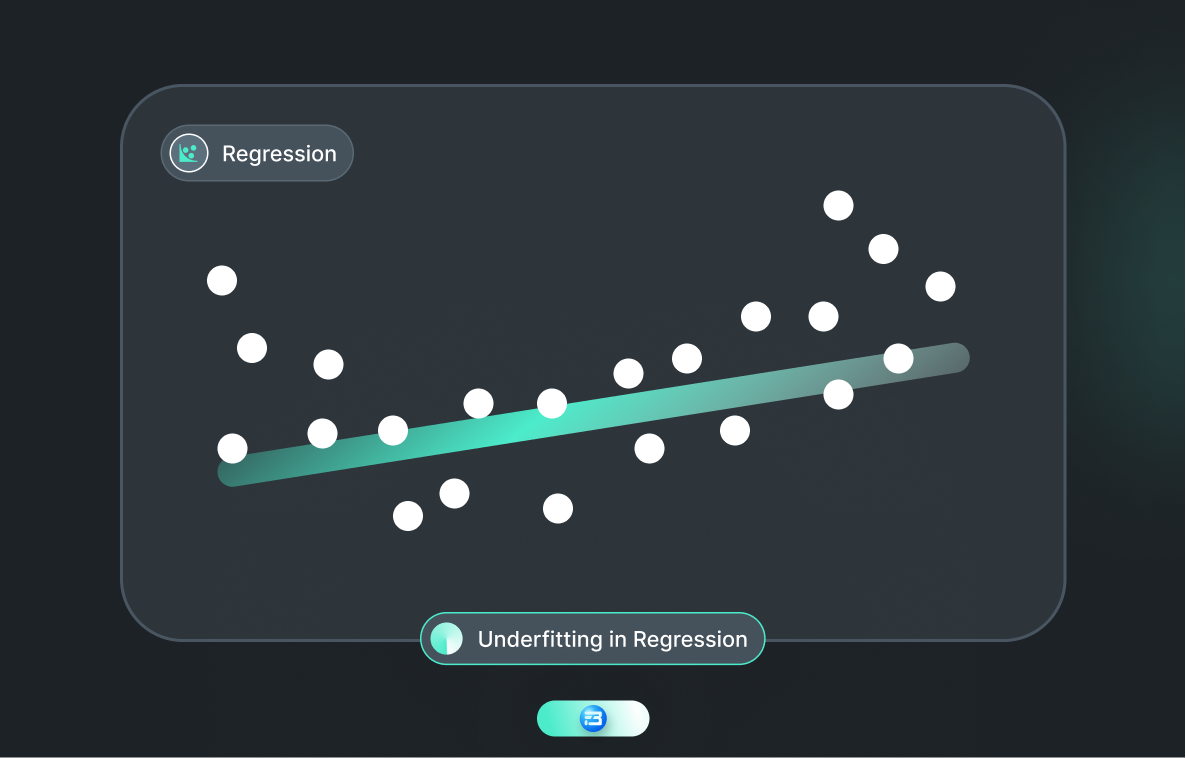 Underfitting is comparable to a person who only possesses fundamental knowledge of a subject and is unable to comprehend or apply more complex concepts. The reason may be that he is not capable enough to grasp complex theorems or has not been trained for enough time. Much like how this person may find it challenging to solve intricate problems, an underfitting model may struggle to comprehend the intricacies and complexity of the data.
Underfitting is comparable to a person who only possesses fundamental knowledge of a subject and is unable to comprehend or apply more complex concepts. The reason may be that he is not capable enough to grasp complex theorems or has not been trained for enough time. Much like how this person may find it challenging to solve intricate problems, an underfitting model may struggle to comprehend the intricacies and complexity of the data.
As an example, consider an individual who has only acquired basic knowledge of addition and subtraction but is requested to solve a complex equation. They may lack the necessary expertise to solve the problem and may arrive at an incorrect answer. Similarly, an underfitting model may not possess sufficient complexity or adaptability to capture the relationships and patterns in the data, thus impeding its ability to make accurate predictions.
Underfitting is a commonly encountered obstacle in machine learning, where a model is too rudimentary to apprehend the patterns and associations in the training data. As a result, this can lead to suboptimal performance when confronted with new or unobserved data.
To avoid underfitting, it's important to ensure that the model is complex and flexible enough to capture the underlying trends in the data. This can be achieved by using more complex models, adding more features or variables, increasing the amount of data used to train the model, and giving the model enough training time.
"The key to better model performance is striking the perfect balance between model complexity and generalization for accurate, real-world predictions"
A good fit model will look something like this:
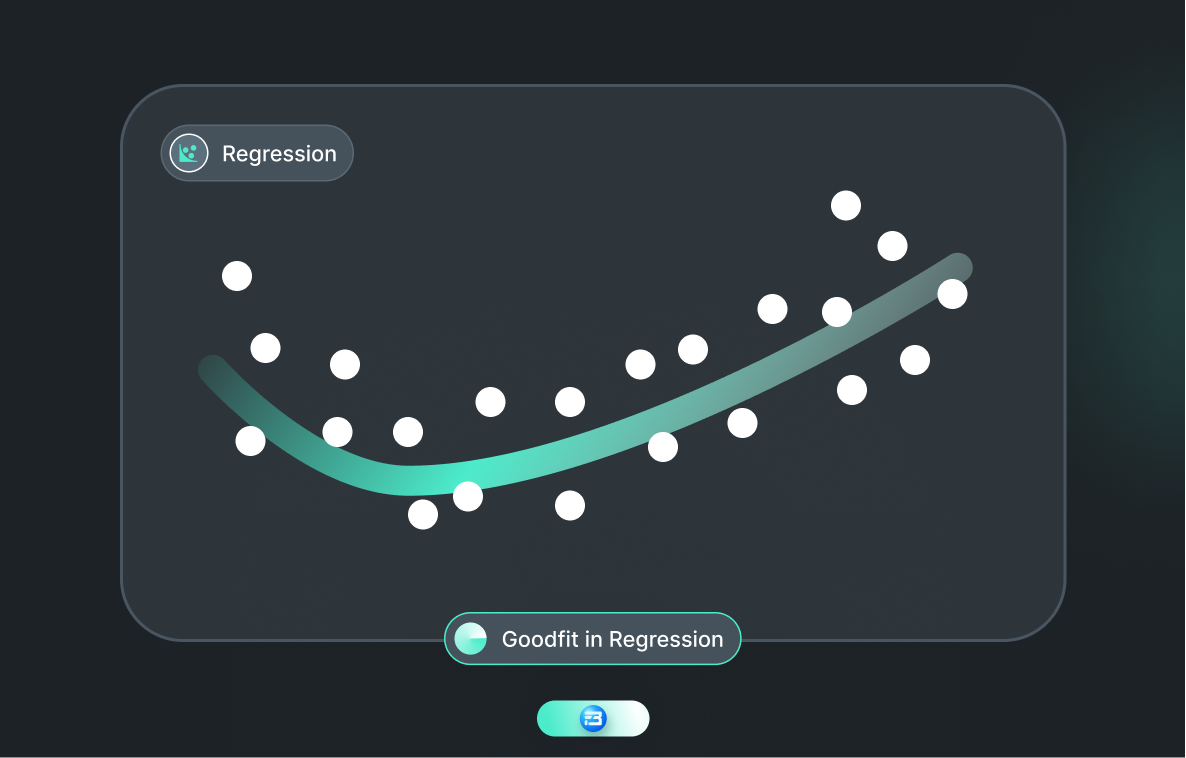 The following difference between overfitting and underfitting will help you revise the overall concept.
The following difference between overfitting and underfitting will help you revise the overall concept.
Model fits too closely to the training data
Model does not fit the training data well enough
Model captures noise and randomness in the data
Model fails to capture underlying patterns and relationships in the data
Model is too complex
Model is too simple
Good performance on training data, poor performance on test data
Poor performance on both training and test data
Can be caused by too many features or parameters
Can be caused by too few features or parameters
Occurs when the model has learned the noise in the data
Occurs when the model is unable to learn the underlying patterns in the data
Can lead to model being unable to generalize to new data
Can lead to model being unable to learn from the available data
Can be visualized by comparing the training and test error curves
Can be visualized by comparing the training and test error curves
Can be caused by training a model for too long
Can be caused by not training a model for long enough
Now let’s understand what overfitting and underfitting look like in real life AI technology.
Automatic Speech Recognition (ASR) is a machine learning application that involves converting spoken words into text. However, ASR models are susceptible to common challenges such as overfitting and underfitting, which can affect the accuracy and performance of the model.
Overfitting in ASR arises when the selected model is so complex that it captures unnecessary noise and randomness from the training dataset. It can also happen when such a complex model is being trained on a limited dataset.
For instance, a speech recognition model that's exclusively trained in American English may perform poorly when attempting to transcribe British or Australian English. This is due to the model having learned to recognize specific features and patterns in the training data that are not present in other accents or languages.
Excessive training on such a limited dataset may make the ASR model overfit, and such a model performs well on a training dataset but cannot replicate the same accuracy in the case of unseen real-life data.
On the other hand, underfitting in ASR occurs when the model is too simplistic and fails to capture the subtleties and variations in the speech dataset. This can also occur when the ASR model is not trained for enough time. In such limited training time, the model may not be able to capture the pattern and learn from it. Such ASR models perform poorly on either training or unseen real world data.
Computer vision (CV) is a powerful application of machine learning that involves the analysis of images and videos to extract meaningful information. However, just like with other machine learning applications, overfitting and underfitting can be significant challenges in CV that affect the accuracy and performance of the model.
When the selected computer vision model is too complex and being excessively trained on a limited and biased training dataset, it will eventually cause overfitting. For example, a complex facial recognition model that is overtrained in a specific group of people may struggle to accurately recognize faces from a different demographic or age group. This happens because the model has learned to recognize only specific patterns and features from the training data that may not be applicable to new data.
On the other hand, underfitting in CV happens when the model is too simple and unable to capture the complexity of the images or videos. For instance, an object detection model that only looks for basic shapes may struggle to detect more complex objects with irregular shapes or patterns. This happens because the model has not learned enough from the training data to recognize and classify more complex images or videos accurately.
Natural Language Processing (NLP) is an application of machine learning that involves the analysis and comprehension of human language. However, overfitting and underfitting can be significant challenges in NLP that affect the accuracy and performance of the model.
When a model in natural language processing is overfit, it underperforms on fresh or untrained data just like any other machine learning model. For example, a sentiment analysis model that is overtrained on customer reviews from a specific industry may perform poorly when analyzing reviews from a different industry. This occurs because the model has learned to recognize specific language patterns and features in the training data that may not generalize well to new data.
In this case, overfitting occurs because of training on a too small, biased dataset. and when such a complex model, which can grasp unnecessary underlining noise present in the dataset, is trained on a limited dataset, it performs well on the training dataset but poorly on the new dataset, which is referred to as an overfit model.
In contrast, underfitting in NLP occurs when the model is too simple and cannot capture the complexity of the language. For example, a language model that only considers basic vocabulary and sentence structure may struggle to accurately predict more nuanced language patterns, such as idiomatic expressions or sarcasm. This happens because the model has not learned enough from the training data or has not been trained for enough time to accurately recognize and generate more complex language patterns.
Now that we are aware that overfitting and underfitting are the real issues, let's examine their root causes.
Now you must have observed in our discussion up until now that insufficient or biased training data was present in the entire discussion.
In the case of overfitting, when the model is trained on a limited or biased dataset, it may fail to learn the underlying patterns and relationships in the data. Instead, it may memorize the noise and randomness present in the training data, leading to overfitting. This causes the model to perform well on the training data but poorly on new or unseen data because it cannot recognize the underlying patterns and relationships in the new data.
On the other hand, insufficient or biased data can also result in underfitting, where the model is not complex enough to capture the underlying patterns and relationships in the data. When the model is trained on a small or biased dataset, it may not have enough examples or variations in the data to learn the underlying patterns and relationships, resulting in underfitting. The model may perform poorly on both the training data and new or unseen data because it has not learned enough from the data to accurately capture the underlying patterns and relationships.
Both overfitting and underfitting can be caused by model complexity in machine learning.
When a model is too complex, with an excessive number of parameters relative to the size of the dataset, it can lead to overfitting. In this case, the model fits too closely to the training data and may capture irrelevant patterns and randomness in the data instead of the underlying patterns. This can result in poor performance on new data since the model has memorized the training data rather than learned the underlying patterns and relationships that generalize well to new data.
In contrast, when a model is too simple with insufficient parameters to capture the underlying patterns and relationships in the data, it can lead to underfitting. For instance, a linear model may be too simple to capture complex, non-linear relationships between the input and output variables. As a result, the model may fail to accurately capture the underlying patterns in the data and perform poorly on both the training and new data.
Overfitting can occur when a model is trained for too long, allowing it to fit too closely to the training data and capture noise and randomness in the data. When a model is trained for too many epochs or iterations, it may start to memorize the training data instead of learning the underlying patterns and relationships in the data. This can lead to overfitting, where the model performs well on the training data but poorly on new or unseen data.
Underfitting can occur when a model is not trained for long enough, preventing it from learning the underlying patterns and relationships in the data. When a model is not exposed to enough examples or variations in the data, it may not have enough information to capture the underlying patterns, resulting in underfitting. This can lead to poor performance on both the training data and new or unseen data.
The complexity of a machine learning model is defined by its architecture, which encompasses the model's structure, including the number and type of layers, connections between them, and the activation functions used. The architecture ultimately determines the model's capacity or flexibility to learn complex patterns and relationships within the data.
A model with a complex architecture typically has many layers, neurons, or non-linear activation functions, allowing it to capture intricate relationships and patterns within the data. In contrast, a model with a simple architecture may have fewer layers, neurons, or linear activation functions, potentially resulting in an incomplete representation of the data's full complexity.
However, the complexity of the model's architecture can significantly impact the model's performance and result in over- or under-fitting. A model with excessive complexity may overfit to the training data, memorizing the noise and randomness in the data instead of the underlying patterns, leading to poor performance on new data. Conversely, a model with insufficient complexity may underfit the data, failing to capture the underlying patterns and relationships accurately.
Hyperparameters are parameters of the machine learning model that are set prior to training and control aspects of the learning process. These are parameters that are not learned during training but rather are set by the practitioner. Examples of hyperparameters include the learning rate, batch size, number of layers, number of neurons in each layer, regularization strength, and activation functions used.
Hyperparameters such as learning rate, batch size, and regularization strength can also impact the performance of the model and lead to overfitting or underfitting.
A learning rate that is too high can lead to overfitting, where the model updates the parameters too aggressively and fails to converge to the optimal solution. A learning rate that is too low can lead to underfitting, where the model updates the parameters too slowly and fails to learn the underlying patterns and relationships in the data.
Similarly, a batch size that is too small can lead to overfitting, where the model overfits to the noise in the data, while a batch size that is too large can lead to underfitting, where the model is not exposed to enough variations in the data.
Overfitting and underfitting pose significant challenges when working with machine learning models, as they can significantly impact a model's performance and ability to generalize well. To combat these challenges, it's essential to select appropriate models and hyperparameters that balance complexity and simplicity and leverage regularization techniques such as dropout and early stopping. High-quality training data is also critical to building accurate and generalizable machine learning models.
At FutureBeeAI, we understand the importance of high-quality training data and can provide unbiased and structured training datasets for various applications, including computer vision, natural language processing, and automatic speech recognition. We offer both off-the-shelf and custom training dataset collections to meet your specific needs promptly.
Contact us today to discuss how we can support your training dataset requirements and help you build accurate and reliable machine-learning models.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





