Healthcare NLP
EHR Automation
How Doctor Dictation Data Shapes Clinical AI Tools
Discover what makes doctor dictation data vital for strong clinical AI performance and how ethical, realistic datasets drive better outcomes.
Healthcare NLP
EHR Automation
Discover what makes doctor dictation data vital for strong clinical AI performance and how ethical, realistic datasets drive better outcomes.

Doctor dictation is not just another type of medical audio. It’s the spoken blueprint of clinical documentation: concise, purposive, and structured in ways that mirror written notes. For teams building clinical ASR, documentation automation, ambient scribes, or coding tools, training on doctor dictation data, not generic medical conversation, materially improves how models interpret clinical intent, format findings and extract coding-relevant details.
This article explains why dictation-style speech matters, what makes it distinct, how ethical simulated collections fill access gaps and what dataset features matter most for robust clinical AI. Throughout, I use the term doctor dictation data to mean audio that captures clinicians speaking documentation-style summaries, impressions and plans that are recorded in realistic acoustic settings and paired with rich metadata suitable for downstream clinical tasks.
Clinicians have long used dictation as part of documentation workflows. What’s new is voice-first automation: tools that convert spoken clinical content directly into structured EMR fields, coded diagnoses or final reports. Those tools succeed only when models learn from the specific patterns of dictation: the way a radiologist sequences findings into “history → technique → findings → impression,” or how a primary-care clinician summarizes assessment and plan in compact, actionable sentences.
Training on conversational or patient-facing audio doesn’t teach these patterns reliably. Conversational speech includes interruptions, lay language and narrative digressions that are common in clinic conversations but absent from documentation. Doctor dictation data supplies the compressed, information-dense speech that documentation automation and clinical ASR must learn to interpret.
Real clinical dictations contain protected health information (PHI) and voice characteristics that can identify speakers. Privacy regulations such as HIPAA and analogous frameworks internationally make sharing raw patient-linked dictation difficult. Hospitals and health systems rightly restrict access; de-identifying audio is non-trivial because removing identifiers from speech goes beyond redacting text.
That constraint has shaped the ethical path forward: realistic, simulated-but-unscripted dictation recorded by verified clinicians or trained contributors. Simulated here means contributors produce unscripted dictations based on clinical scenarios, not read or synthetic speech. Simulated ≠ synthetic: we avoid machine-generated voices or rigid scripts because these lose the spontaneity and phrasing that clinicians use when documenting.
Simulated collections are such when governed by strict consent, credential checks where needed and HIPAA-minded processes that preserve the linguistic and structural realism required for clinical ASR while minimizing patient privacy risk.
 Dictation differs from other medical speech in three practical ways:
Dictation differs from other medical speech in three practical ways:
Clinicians speak to documents. They use concise phrases, standardized report sections, and repeated patterns (e.g., “Impression: …”, “Plan: …”) that map directly to EMR sections. This structure helps models learn segmentation (where one clinical thought ends and the next begins) and mapping to structured fields.
Example (radiology micro-snippet):
“History: 34-year-old female, left knee pain after fall. Technique: MRI without contrast. Findings: small medial meniscal tear, no ACL disruption. Impression: medial meniscal tear, consider arthroscopy if symptomatic.”
This short passage contains the signals models need: labeled sections, concise findings and an impression that maps to diagnosis codes.
Different specialties use different terms and sequencing. Radiology reports are highly templated and dense; emergency medicine dictations are rapid and descriptive; cardiology notes emphasize function and measurements. A useful doctor dictation audio dataset captures these differences rather than treating all medical speech as interchangeable.
Clinicians record in exam rooms, reading stations, hallways, or on mobile devices. They speak with many accents and at varied rates. High-quality datasets intentionally preserve this variability because production models will encounter it.
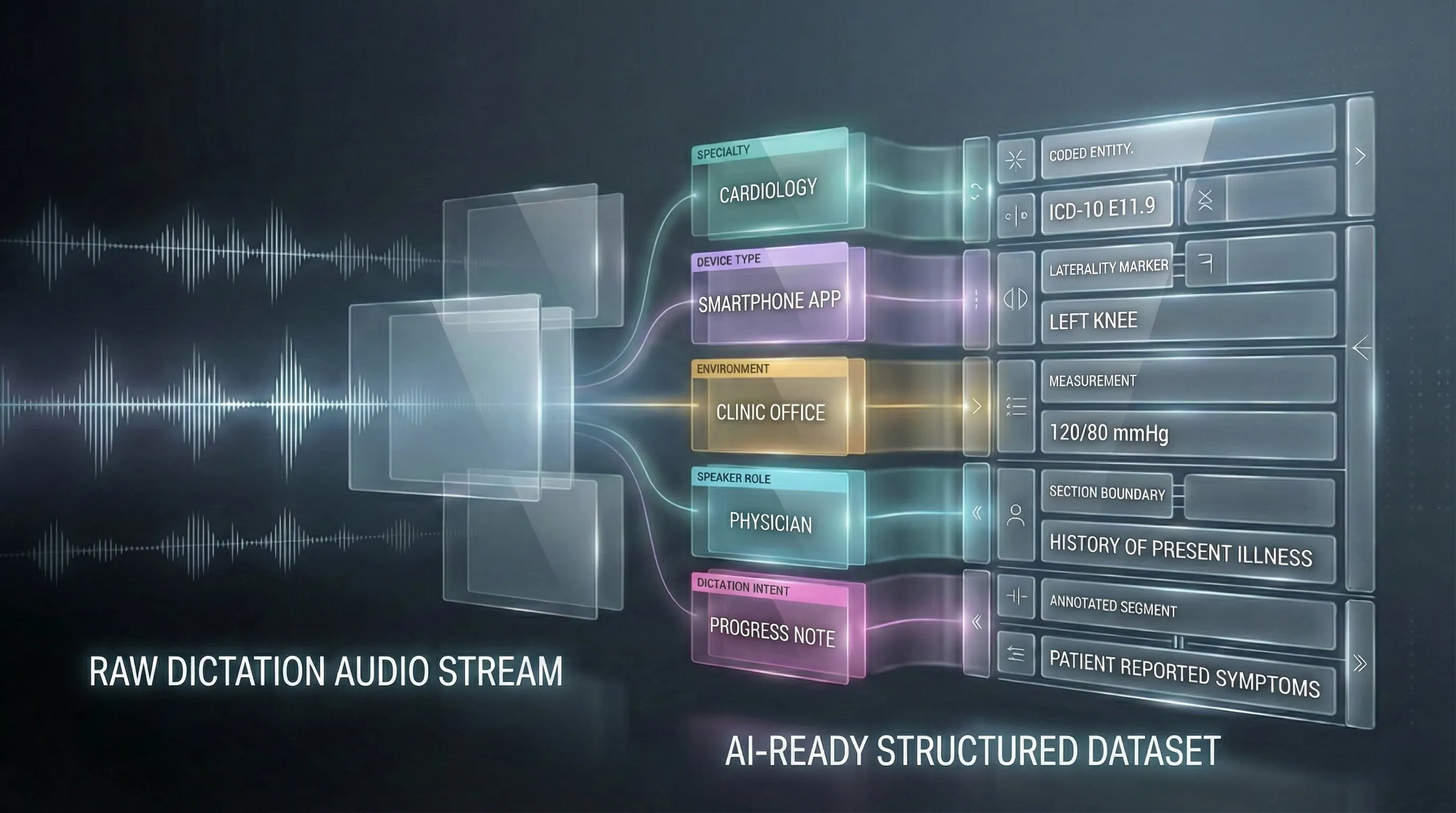 Audio alone is useful, but metadata transforms recordings into effective clinical AI training data. Useful metadata includes specialty, speaker role (attending, resident), device type, recording environment, and the clinical intent of the dictation (e.g., final report vs. quick note). This context enables models to adapt behavior: a radiology-style cadence can be processed differently than a primary-care summary.
Audio alone is useful, but metadata transforms recordings into effective clinical AI training data. Useful metadata includes specialty, speaker role (attending, resident), device type, recording environment, and the clinical intent of the dictation (e.g., final report vs. quick note). This context enables models to adapt behavior: a radiology-style cadence can be processed differently than a primary-care summary.
A concrete example: tagging a clip as “radiology, MRI knee, reading station microphone” helps the model learn typical lexical patterns and microphone characteristics for that use case. When downstream code must extract measurements or map impressions to ICD or CPT codes, that extra structure reduces ambiguity and improves classification accuracy.
Annotation depth also matters. High-quality transcripts should include medical terminology accuracy and explicit markup for sections and key entities (measurements, laterality, modifiers). These annotations are the bridge between raw audio and structured outputs like EMR fields or billing codes.
Not every healthcare AI need depends equally on dictation-style speech, but several high-value applications do:
Models that turn clinician speech into formatted notes learn most reliably from dictation because dictation reflects how clinicians consciously structure documentation.
Radiology is the clearest example: decades of dictated reports create repeatable linguistic structures that AI can learn to reproduce and summarize. Specialty-tailored datasets (cardiology, oncology, orthopedics) are necessary to generalize across disciplines.
Voice-driven EMR fields require accurate capture of values (dosages, measurements, laterality). Dictation contains many of those discrete, structured elements.
Procedure descriptions and impression phrases in dictations frequently contain the terms coders need. Training extraction models on dictation improves recall of coding-relevant language.
Even when AI operates on patient-facing conversations, exposure to dictation-style summaries helps models generate the concise, clinical “summary voice” clinicians expect.
Across these use cases, the difference between models trained on generic medical speech and those trained on doctor dictation data shows up in segmentation quality, terminology accuracy, and the fidelity of structured outputs.
 A production-ready dictation corpus balances realism, breadth, and governance. Key attributes include:
A production-ready dictation corpus balances realism, breadth, and governance. Key attributes include:
Datasets should cover the target specialties and the vocabulary unique to them.
Clinical systems are deployed globally. Multilingual medical dictation and accent coverage reduce bias and failure modes at deployment.
Include recordings from diverse devices and real clinical environments, not only pristine studio audio.
Specialty, device, environment, speaker role, and section markup for transcripts.
Consent, contributor verification (medical credentials verified only where required), and HIPAA-aligned handling of recordings.
FutureBeeAI’s approach emphasizes simulated-but-unscripted collections to capture natural phrasing, plus metadata and annotation standards designed for downstream clinical workflows.
Collecting high-quality dictation data is operationally heavier than recording conversations. It requires contributor recruitment, realistic scenario design, device and environment diversity, and careful annotation. But the payoff is models that generalize to the structured demands of clinical documentation.
As healthcare AI evolves, teams should prioritize datasets that reflect the workflows they intend to automate. That means selecting collections that match the specialties, languages, and recording conditions of their target deployments. For many organizations, ethically collected, simulated dictations provide the fastest, lowest-risk route to high-fidelity training data.
 FutureBeeAI builds doctor dictation data with three priorities: realism, ethics, and operational rigor. Collections are created by verified medical experts or trained contributors through our contributor platform Yugo, with attention to demographic validation, device variety, and unscripted clinical phrasing. Metadata and annotation practices are embedded into every project, and consent and privacy controls follow HIPAA-minded workflows.
FutureBeeAI builds doctor dictation data with three priorities: realism, ethics, and operational rigor. Collections are created by verified medical experts or trained contributors through our contributor platform Yugo, with attention to demographic validation, device variety, and unscripted clinical phrasing. Metadata and annotation practices are embedded into every project, and consent and privacy controls follow HIPAA-minded workflows.
We design datasets to support clinical ASR training, documentation automation, ambient scribe models, and coding extraction systems. Where specialty credential verification is required, we apply it; where natural clinical phrasing is the priority, we use experienced contributors trained in realistic dictation capture.
Doctor dictation data is a distinct and practical category of clinical audio. It captures the structure, terminology, and brevity that documentation systems require, and it exposes the acoustic and linguistic variation real-world models must handle. Because patient privacy restricts sharing raw clinical dictations, responsibly designed simulated-but-unscripted dictation collections offer an ethical and effective path to building clinical ASR training data, doctor dictation audio datasets, and multilingual medical dictation resources.
For teams building documentation automation, ambient scribes, or coding tools, the choice of training data is not peripheral; it determines whether your model understands the language of clinical documentation or just the language of conversation. Contact us for investing in high-quality, ethically collected doctor dictation data, which is a practical step towards reliable, deployable healthcare AI.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





