Why is expressive TTS harder to evaluate than neutral TTS?
TTS
Speech Synthesis
Voice Cloning
Evaluating expressive Text-to-Speech systems is significantly more complex than assessing neutral TTS. Neutral TTS prioritizes intelligibility, clarity, and pronunciation accuracy. These attributes can often be measured with structured perceptual scales and supported by objective proxies.
Expressive TTS, however, must convey emotional intent. It must sound joyful when required, empathetic when necessary, and serious when context demands authority. This emotional dimension introduces subjectivity, context sensitivity, and perceptual variability that simple metrics cannot fully capture.
The Core Challenge of Expressive TTS
In neutral TTS, quality is often defined by how clearly the content is delivered. In expressive TTS, quality depends on whether the emotional tone aligns with the intended message. A voice meant to sound reassuring must feel reassuring. A cheerful voice must not sound exaggerated or artificial.
Different listeners interpret emotional cues differently. What sounds authentic to one listener may feel overstated to another. This perceptual variability requires evaluation strategies that move beyond single aggregate scores.
Key Dimensions for Expressive TTS Evaluation
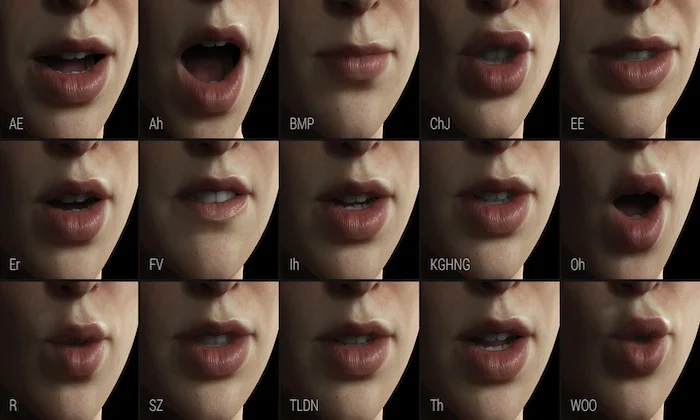
Naturalness: Does the speech flow with realistic timing, emphasis, and human-like rhythm?
Prosody Alignment: Are pitch variation, stress patterns, and pacing appropriate for the intended emotion?
Emotional Resonance: Does the output evoke the intended feeling in listeners?
Contextual Consistency: Is emotional tone stable and appropriate across different content types and scenarios?
Subgroup Sensitivity: Do emotional cues resonate similarly across demographic and cultural groups?
For example, a TTS speech dataset designed for cheerful interaction must preserve emotional consistency even when conversational content shifts. Without structured evaluation, tonal drift can go undetected.
Why Standard Metrics Are Insufficient
Mean Opinion Score can provide a general perception signal, but it does not isolate emotional authenticity. A model may score well on clarity while failing in emotional appropriateness.
Expressive TTS requires attribute-level rubrics, structured paired comparisons, and diverse evaluator panels. Human listeners remain essential for identifying subtle emotional mismatches that automated systems cannot detect.
Designing a Multi-Layer Evaluation Strategy
Attribute-Based Structured Rubrics: Separate emotional expressiveness from naturalness and intelligibility to prevent masking effects.
Diverse Listener Panels: Include evaluators from different linguistic and cultural backgrounds to capture varied emotional interpretations.
Contextual Scenario Testing: Evaluate the same expressive voice across multiple domains such as storytelling, customer support, and instructional content.
Controlled Real-World Simulation: Test under realistic listening conditions to understand how emotional cues survive environmental variation.
Ongoing Monitoring for Drift: Emotional calibration can shift after updates. Continuous evaluation prevents gradual loss of expressiveness.
Practical Takeaway
Expressive TTS evaluation is inherently multi-dimensional. It requires structured perceptual analysis, contextual sensitivity, and continuous refinement. Treating expressive systems with the same evaluation depth as neutral systems leads to blind spots.
At FutureBeeAI, we design structured frameworks tailored for expressive TTS evaluation. Our methodologies combine human insight, attribute-level diagnostics, and contextual validation to ensure emotional authenticity and deployment reliability.
If you are refining expressive TTS systems and seeking a robust evaluation strategy, connect with our team to explore solutions that align emotional performance with real-world user expectations.
What Else Do People Ask?

Related AI Articles

Browse Matching Datasets




Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!
