In the rapidly evolving landscape of speech recognition technology, we are overwhelmed with the new speech recognition models coming into the market frequently. A few of them have good accuracy and are able to recognise multiple languages. But still, some challenges are there.
Like us, humans are remarkably good at focusing their attention on a particular person in a noisy environment, mentally “muting” all other voices and sounds. Known as the cocktail party effect, this capability comes naturally to us humans.
But automatic speech separation, separating an audio signal into its individual speech is very difficult for ASR models and for them, audio-visual speech recognition can be a game changer. Audio-Visual Speech Recognition (AVSR) leverages both auditory and visual cues to enhance accuracy and robustness in understanding spoken language.
Many companies, including Google, are working on AVSR models. Although audio-visual speech recognition models have shown better speech recognition, they are also facing challenges such as a lack of training data.
So, this blog explores the significance of visual speech data and its pivotal role in advancing AVSR systems.
Understanding Audio-Visual Speech Recognition
Traditional speech recognition systems solely rely on audio input, making them susceptible to noise and ambiguous utterances. AVSR, on the other hand, harnesses the visual cues from the speaker's facial movements, lip patterns, and gestures, synergizing them with audio signals for a more comprehensive understanding of speech.
In other words, AVSR is like a clever friend that listens not just to what you say but also watches how your face moves. First, it captures your words and studies the way your lips, tongue, and face move when you talk. These details from what it hears and sees are synchronized, making sure everything matches up in time.
Then, it picks out the important parts from what it hears (like how words sound) and what it sees (like how your face moves). These details are mixed together to create a full picture of what you're saying. Imagine it as learning from watching and listening at the same time. A smart computer learns from lots of talking and moving to understand different voices, accents, and even how people express themselves. So, when you talk to it, it can figure out not just the words but also the feelings and actions behind them. It's like having a friend who understands you really well!
But friends also need stories to understand you better, and for AVSR, those stories come from the data it learns from. So, let’s discuss the visual speech data.
What is Visual Speech Training Data?
Visual speech training data is a specific type of data used to train computers to understand spoken language by looking at lip movements in videos. To prepare this type of data, we record people's videos while they speak in different environments like noise, different lighting conditions, etc.
We can just ask a question and ask people to record their thoughts. For example: “What is your favorite dish?” People will then record their thoughts and this is how we will get natural expressions.
So, it is a combination of speech and video of humans.
As I mentioned earlier, this visual speech data is helpful to understand speech through lip movements, and facial expressions. Let’s understand in detail how it can actually help AVSR.
The Role of Visual Speech Data
Lip Movements and Phoneme Recognition
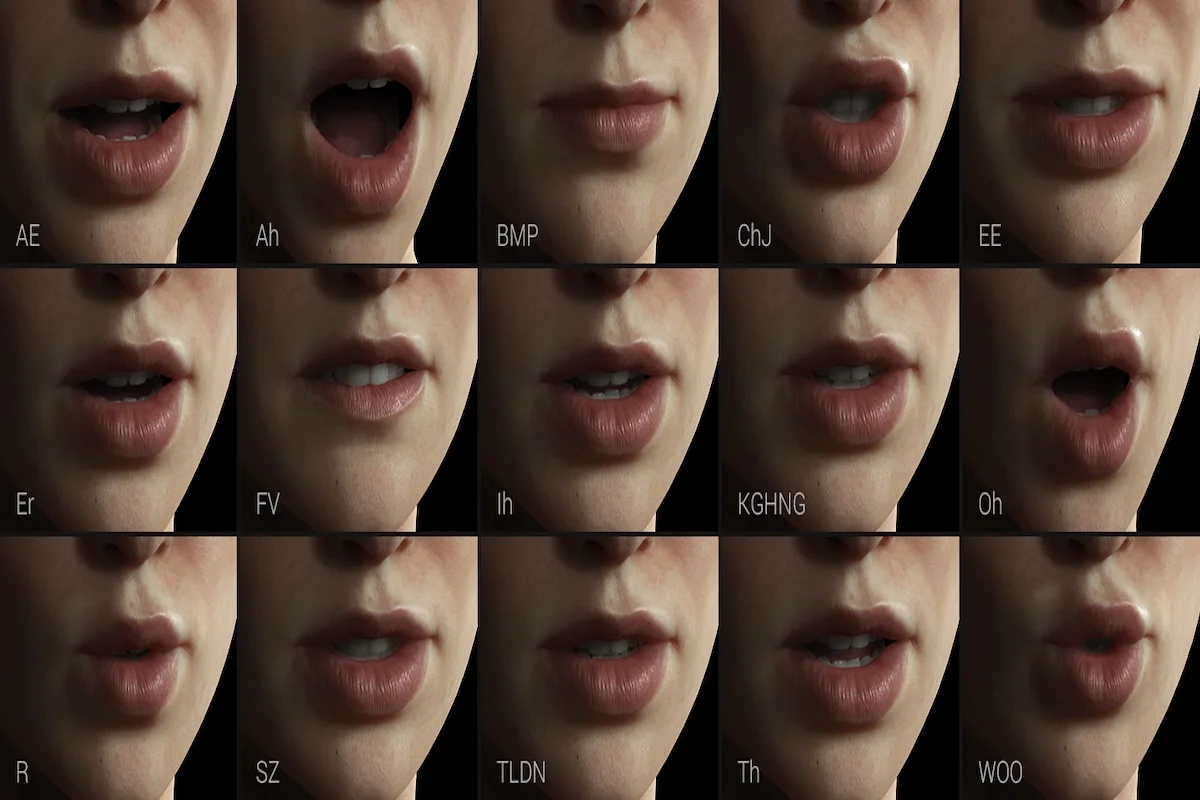
Visual speech data captures the intricate movements of the lips, tongue, and facial muscles during speech. This information is invaluable for distinguishing between phonemes, enhancing the system's ability to recognize and differentiate sounds that may be acoustically similar.
Many English words sound similar and in different conditions, it can be very difficult for a speech recognition model to recognise the spoken words correctly. For example: saying "bat" and "pat" might sound similar, but your lips move differently. So, an AVSR model trained with high-quality visual speech data that contains words like the above example can pick up on these subtle lip movements, and help in recognising the correct word.
Improved Accuracy in Noisy Environments
In noisy environments where audio signals may be distorted, visual cues provide a supplementary source of information. AVSR, with visual speech data, becomes more robust in such conditions, ensuring accurate recognition even in challenging situations.
Imagine chatting away in a bustling cafe. If given this type of audio, many ASR model accuracy will collapse because they only rely on the sound. But an audio visual speech recognition model trained with similar data can produce better results because it doesn't just rely on sound; it's got the visual scoop too. This makes it a pro at handling noisy situations.
Enhanced Speaker Diarization
Everyone has a unique way of speaking, a sort of speech fingerprint. Visual speech data contains facial features and expressions and AVSR uses these facial features and expressions, like a secret handshake for your voice, to know it's you doing the talking.
Contextual Understanding
Visual speech data adds a contextual layer to the interpretation of spoken language. The fusion of audio and visual information enables the system to understand not just what is being said but also how it is being expressed, allowing for a more nuanced comprehension of the speaker's intent.
Just understanding the spoken words is not enough because the same words can be used to reflect different emotions. Audio-visual speech recognition model goes beyond just words; it's about understanding how you say them.
Accessibility Breakthroughs
Visual speech data contributes significantly to breaking down barriers to accessibility. AVSR, by incorporating visual cues, becomes a valuable tool for individuals with hearing impairments. The fusion of audio and visual information ensures a more inclusive and effective communication platform, empowering users across different abilities.
So, now we understand the benefits of visual speech data and their role in powering better speech recognition. It is a great solution but a great solution comes with some great challenges.
Challenges and Solutions for AVSP
The integration of visual speech data into Audio-Visual speech recognition systems brings along certain challenges, including variations in facial expressions, changing lighting conditions, occlusions, and the complexity of combining information from multiple modalities.
To address these challenges, ongoing advances in computer vision techniques and deep learning models focus on recognizing diverse facial expressions and adapting to unique ways people move their lips and facial muscles during speech.
Robust data preprocessing methods play a pivotal role in handling issues such as varying lighting conditions, ensuring consistency in visual data quality, and mitigating the impact of occlusions by employing facial landmark tracking and three-dimensional modeling.
Furthermore, the complexity of multimodal fusion, involving the combination of audio and visual information, is tackled through advanced deep learning architectures and fusion techniques. These collective efforts aim to make AVSR systems increasingly reliable, allowing them to adapt to the dynamic and diverse nature of real-world communication scenarios and capture both auditory and visual nuances effectively.
Free Visual Speech Data by FutureBeeAI
We understand the importance of data accuracy for model training. Training data accuracy and diversity are the most important factors for any AI model and we are providing visual speech data in multiple languages. So, if you are an organization working on AVSR research or training models, then you can reach out for free samples.
FutureBeeAI: Training Data Provider
We offer custom and industry specific speech, text video and image training data collection services, as well as ready to use 200+ datasets for different industries. Our datasets include facial training data, driver activity video data, multilingual speech data, visual speech data, human historical images, handwritten and printed text images, and many others. We can also help you label,annotate and transcribe your data.
We have built some SOTA platforms that can be used to prepare the data with the help of our crowd community from different domains.
You can contact us for samples and platform reviews.
[Image Credit: Reallusion]