NLP
Text Annotation
Different Types of Text Annotations in Natural Language Processing
Exploring text annotation in natural language processing and its different types in preparing text data for machine learning models.
NLP
Text Annotation
Exploring text annotation in natural language processing and its different types in preparing text data for machine learning models.

Artificial intelligence and its applications are here to stay. This technology has changed the way we interact with the world, and it has gone from a science fiction dream to a critical part of our lives. Some of the most developed sub-field of AI are machine learning, deep learning, neural networks, natural language processing, and computer vision. These sub-fields have different applications, and most of the time, these sub-fields work in convergence. For example, many natural language processing models use machine learning to establish communication channels between humans and machines.
You may have used Grammarly to improve your writing, but we barely know how these platforms detect that there is something wrong in the given sentence. How are they suggesting the correct grammar or sentence structure?
What Grammarly has done is use natural language processing to analyze every nuance of the language, down to the character level, all the way up to words and full paragraphs of text.
Grammarly's artificial intelligence system was originally provided with a lot of high-quality training data to teach the algorithm by showing examples of what proper grammar looks like. This text corpus—a huge compilation human researchers organized and labeled so the AI could understand it—showed, as an example, not only proper uses of punctuation, grammar, and spelling but also incorrect applications so the machine could learn the difference.
For more info, you can also read the article The Amazing Ways Google and Grammarly Use Artificial Intelligence to Improve Your Writing by Bernard Marr.
Similar to the above example, there are a lot of text-based models that use natural language processing and machine learning to predict and get the required output.
In this article, we will discuss natural language processing and different methods of annotating text data for NLP models, although not all models need annotation and labeling.
Natural language processing (NLP) is one of the biggest sub-fields of artificial intelligence that enables computers to understand, manipulate, and interpret human language. Natural language processing models use text and speech data to train various models like chatbots, machine translation engines, voice bots, and sentiment analysis, which improves productivity for a lot of businesses like healthcare, banking, insurance, e-commerce, telecom, etc.
Many of the NLP text-based models are developed in convergence with supervised or semi-supervised machine learning and for developing a natural language processing model based on this learning, we need a lot of annotated text corpora.
An annotated text corpus means text data in huge quantities with proper annotation of each and every entity for given use cases. For example: In order to gauge consumer sentiment towards your product, it is necessary to analyze the sentiment of reviews provided by individuals, right?
You can use a model that understands sentiments in a given set of reviews to check reviews of human sentiments for your product. To make any natural language processing model understand the sentiments of your clients, we have to train the model with a pre-labeled review text corpus with labels like positive, negative, and neutral.
Labeling this type of data is not going to be an easy task but luckily FutureBeeAI is here with experienced annotators for dealing with such a huge amount of unlabeled data. In the shortest turnaround time, FutureBeeAI will help the NLP developers get all the text data labeled so they can train their model for sentiment analysis.
Upon completion of model development, product reviews can be utilized as input to gain insight into consumer sentiment toward the product. Utilizing the results, strategic decisions can be made to enhance the overall performance of the business. This approach holds significant potential for driving growth.
In a similar vein, it is possible to develop a wide array of text-based models such as NLP, sentiment analysis, text classification, language translation, etc. Each of these models may require unique annotations in order to function effectively. Therefore, it is important to explore the concept of text annotation and its various forms in order to effectively address specific use cases.
Text data annotation can be defined as assigning labels or metadata to an entire document or different parts of its content, like keywords, phrases, and sentences. The annotated text helps machines understand the context of human languages.
Similar words used by people may have different intentions or sentiments, and text annotation techniques help us to understand the true meaning of words or the context of any given sentence or text document.
For Example
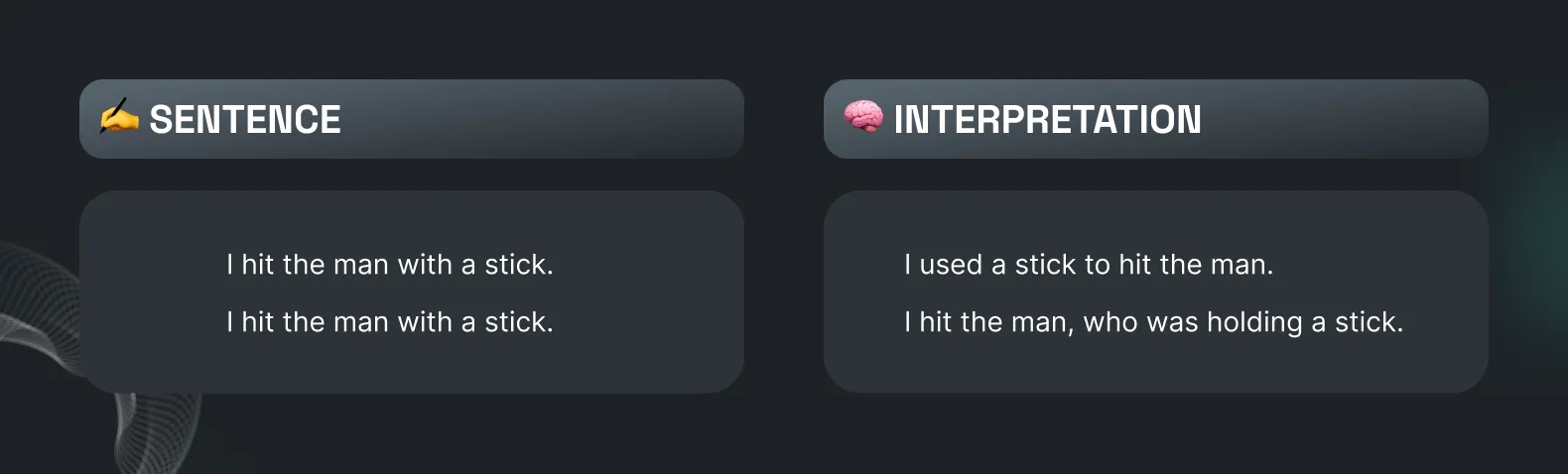 In the above example, the machine will never understand the actual meaning without proper labeling and annotation of the entire scene, even if we cannot interpret this without reading the entire scene.
In the above example, the machine will never understand the actual meaning without proper labeling and annotation of the entire scene, even if we cannot interpret this without reading the entire scene.
Developing text models needs proper annotation, and based on different use cases, we have many different types.
As the name suggests, it is used to label unstructured sentences with important entities. The entity may have a name, location, key phrase, verb, adverb, etc. This is often used for chatbot training and can also be defined as the act of locating, extracting, and tagging entities in text. Depending on use cases, we can further describe this annotation in the following ways:
This is used for identifying and labeling named entities in text. Named entities are specific persons, organizations, locations, or other concepts that are mentioned in the text.
For example, in the sentence, “FutureBeeAI started its business in 2018 from India, " the named entities "FutureBeeAI, " "2018,” and “India” would be identified and labeled as an organization, year, and location, respectively.
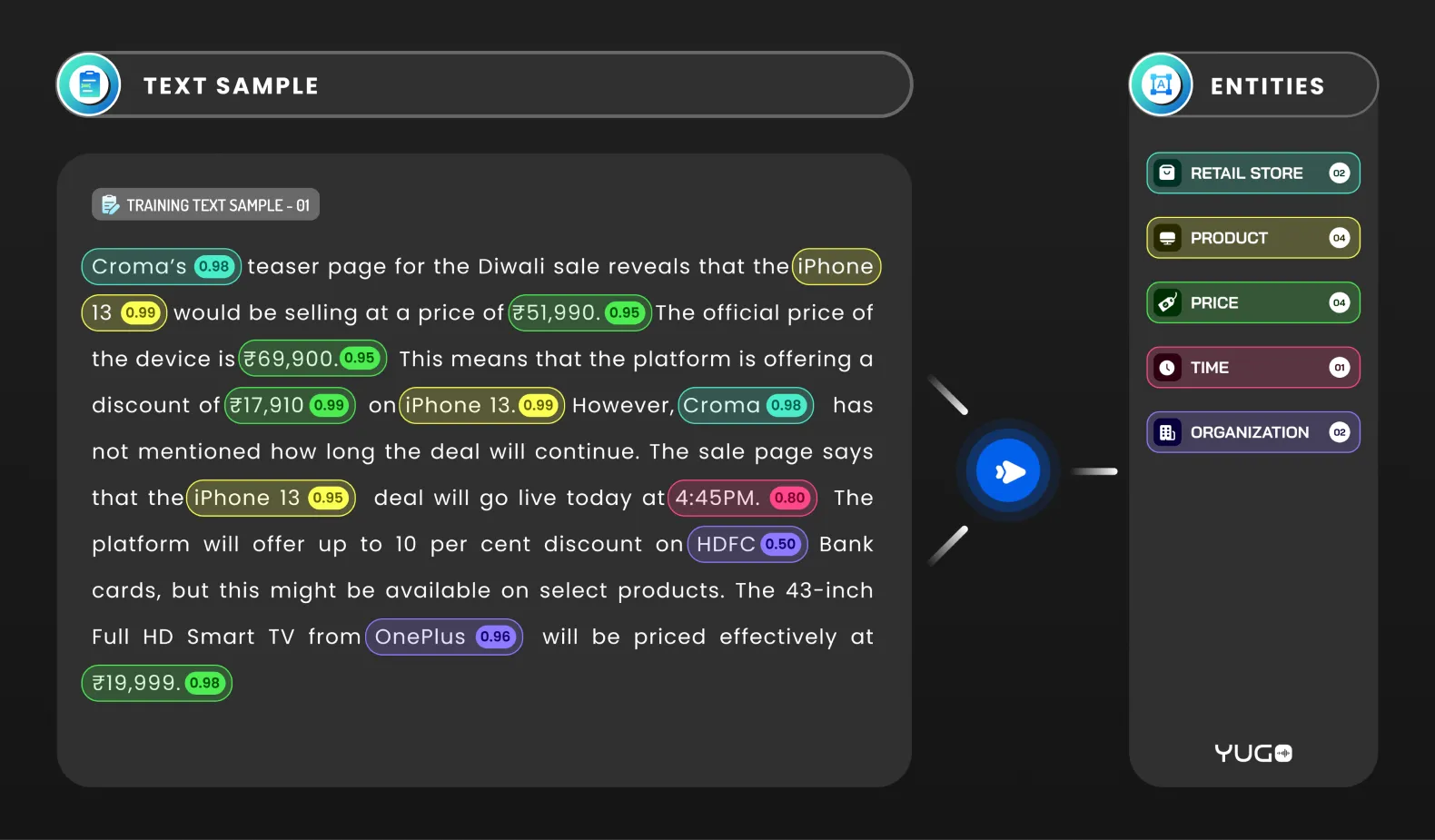 NER can be performed using a variety of techniques, including rule-based approaches, machine-learning algorithms, and hybrid methods that combine both rule-based and machine-learning approaches.
NER can be performed using a variety of techniques, including rule-based approaches, machine-learning algorithms, and hybrid methods that combine both rule-based and machine-learning approaches.
NER is useful for a variety of NLP tasks, such as information extraction, machine translation, and text summarization, and can also be used to improve the accuracy and effectiveness of search engines and other information retrieval systems. Grammarly, Siri, and Google translate excellent examples of NLP that use NER.
Part-of-speech tagging helps us parse sentences and identify grammatical units, such as nouns, pronouns, verbs, adverbs, adjectives, prepositions, conjunctions, etc.
In other words, it helps to identify the underlying grammatical structure of a sentence and can be used to disambiguate word meanings and improve the accuracy of other NLP tasks, such as parsing and information extraction.
This one can be described as locating and labeling keywords or keyphrases in textual data Keyphrase tagging is useful for a variety of natural language processing tasks, such as text summarization, information retrieval, and document classification. It can also be used to improve the accuracy and effectiveness of search engines and other information retrieval systems.
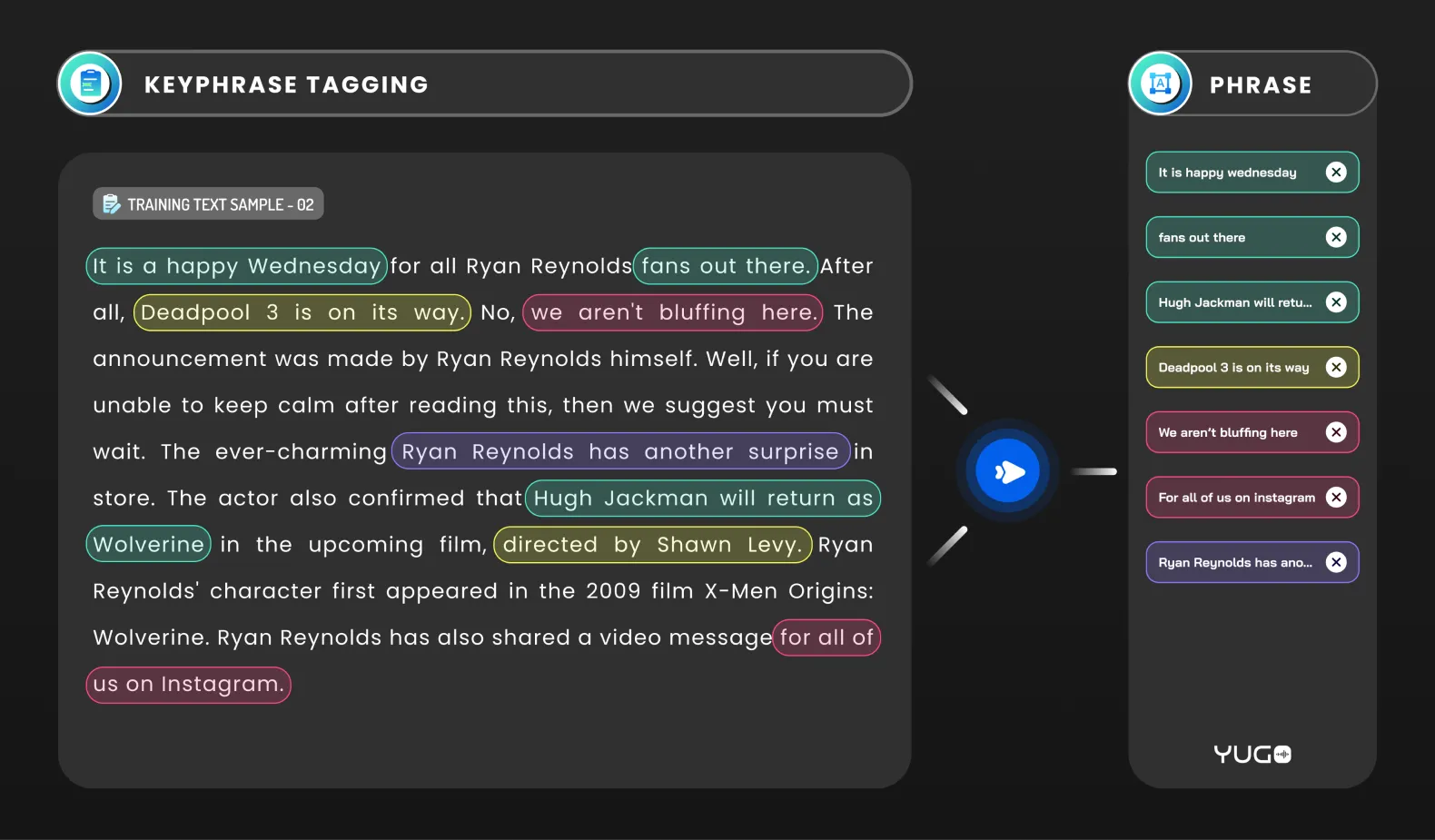 The above three types of entity annotation often go hand-in-hand with entity linking to help models contextualize entities further.
The above three types of entity annotation often go hand-in-hand with entity linking to help models contextualize entities further.
Entity linking, also known as named entity linking (NEL), is the process of identifying and linking named entities in a text to their corresponding entries in a knowledge base or database. For example, if a text mentions "Barack Obama," entity linking would identify that the named entity refers to a specific person and link it to the corresponding entry in a database of people, which may include additional information about the person such as their biographical details and career achievements.
Entity linking is useful for a variety of natural language processing tasks, such as information extraction, question answering, and text summarization. It can also be used to improve the accuracy and effectiveness of search engines.
Text classification is the process of assigning a label or category to a chunk of text or lines with a single label. It is used in a variety of applications, including spam filtering, sentiment analysis, topic classification, document categorization, etc.
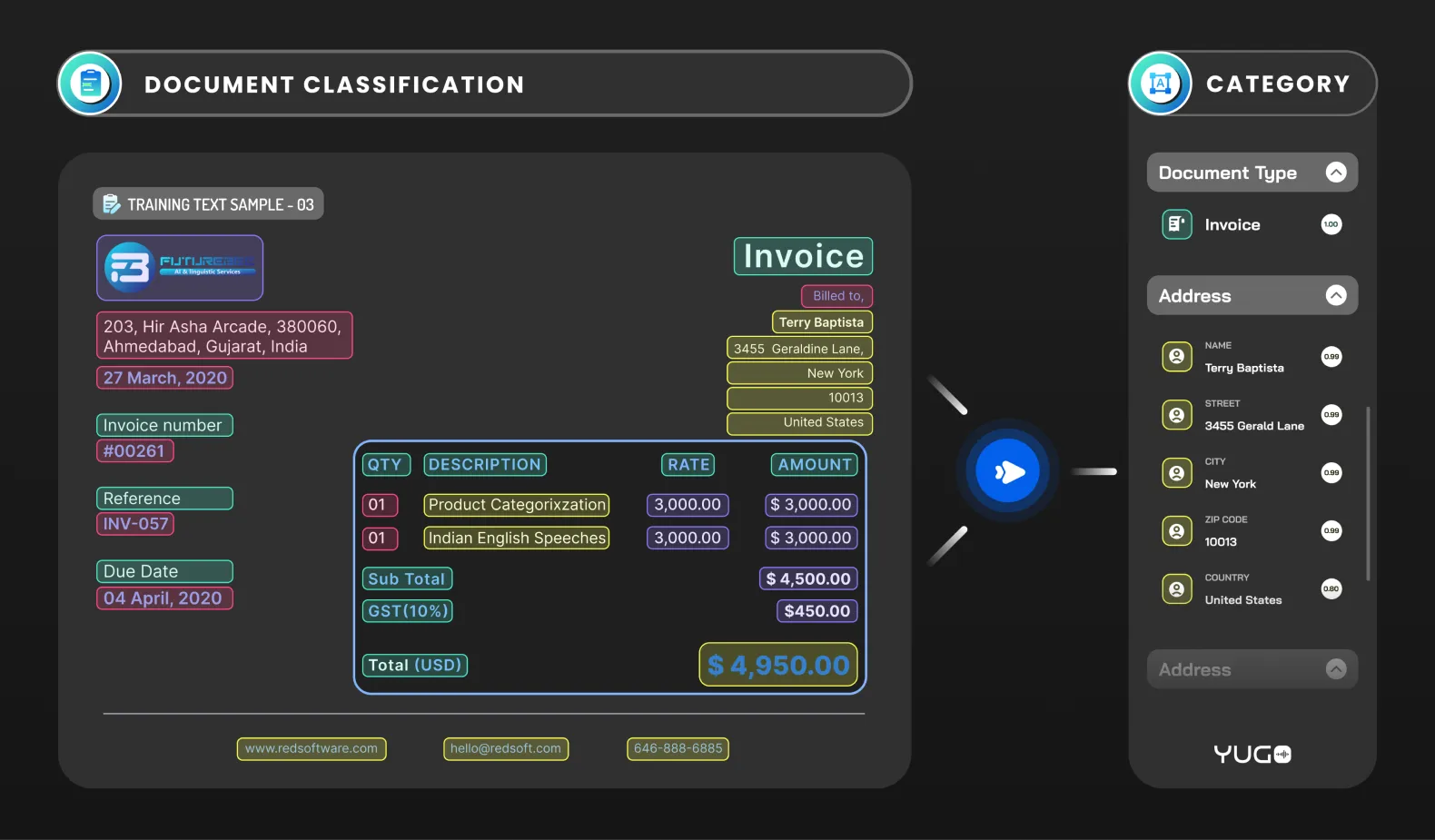 Document categorization is the process of assigning a label or category to a document based on its content. It can be useful for the intuitive sorting of massive amounts of textual content.
Document categorization is the process of assigning a label or category to a document based on its content. It can be useful for the intuitive sorting of massive amounts of textual content.
Product categorization is the process of assigning a label or category to a product based on its characteristics or features. Product categorization is used to organize and classify products into predefined categories or labels, which can be used for various purposes such as product search and navigation, recommendation systems, and marketing analysis.
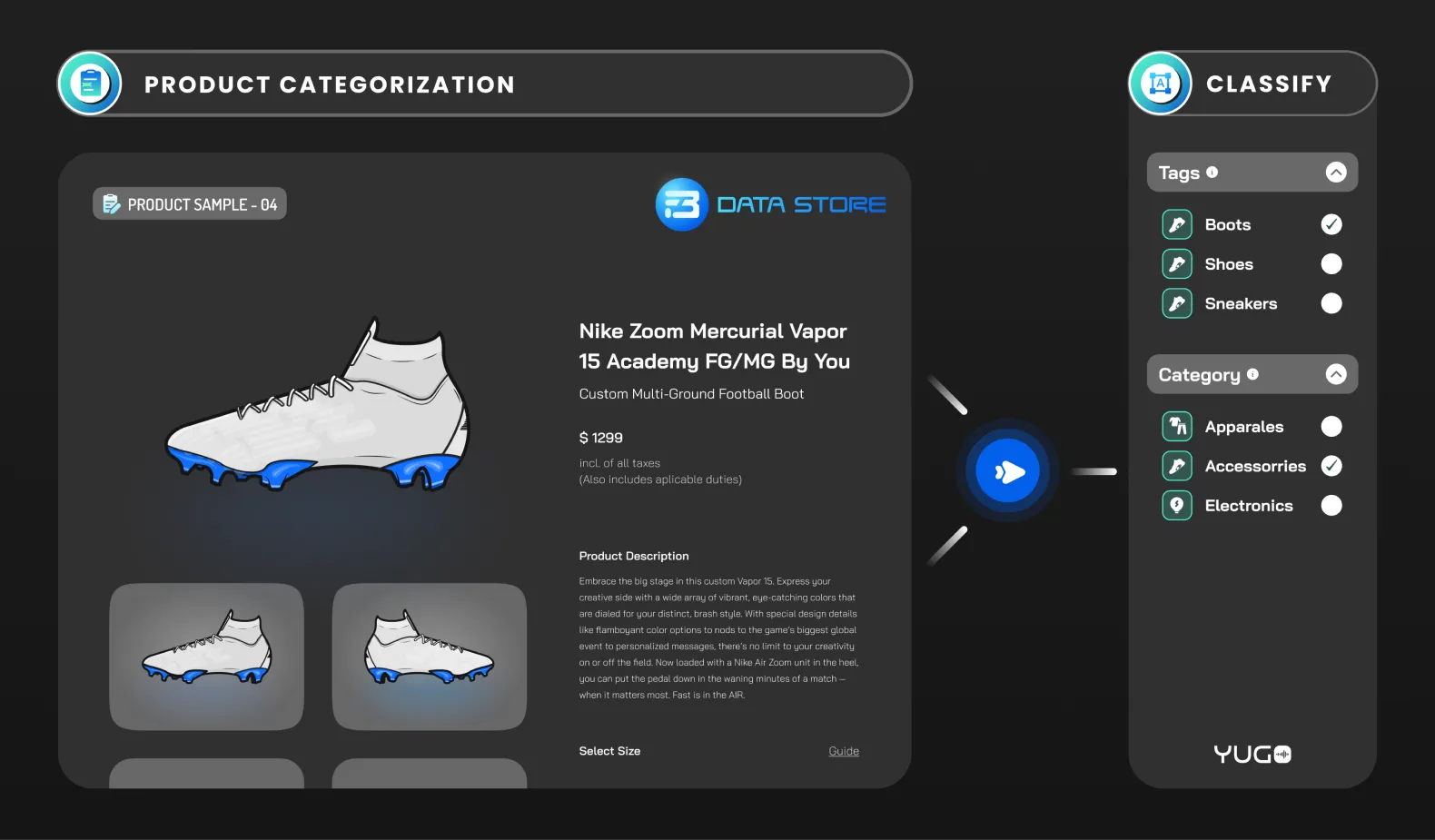 Text classification is a broad category and similar to the above-explained text classification types we have sentiment annotation and intent annotation are technically just specialized forms of text classification. Let’s understand them in detail:
Text classification is a broad category and similar to the above-explained text classification types we have sentiment annotation and intent annotation are technically just specialized forms of text classification. Let’s understand them in detail:
Sentiment annotation, also known as sentiment analysis or opinion mining, is used to identify and label emotions (like sad, happy, and angry) and opinions in any given text data or individual segments of text as positive, negative, or neutral.
 Here is an example of a sentiment annotation:
Here is an example of a sentiment annotation:
Text: “The food at the restaurant was terrible. The service was slow, and the prices were too high. On the plus side, the atmosphere was nice.”
Examples of sentiment annotation:
Overall sentiment: Negative
In this example, our sentiment annotator has identified that the text expresses a mostly negative sentiment about the restaurant, with one positive element (the nice environment).
Sentiment annotation is useful for a variety of natural language processing tasks, such as social media analysis, customer service, and market research. It can also be used to gain insights into public opinion on various topics or to understand how people feel about a particular product or service.
Intent annotation, also known as "intent classification", is the process of identifying and labeling the intention or purpose behind a piece of text or a user's input. Intent annotation involves classifying a text or input into one or more predefined categories or classes, such as a request for information, a request for help, a complaint, or a request to make a purchase.
Here is an example:
Text: “I’m looking for a good Indian restaurant in Paris."
Intent annotation:
Overall intent: Request for information about an Indian restaurant in Paris.
In this example, our intent annotator has identified that the text expresses a request for information about an Indian restaurant in Paris.
Intent annotation is often used in the development of natural language processing (NLP) systems such as chatbots, virtual assistants, and language translation systems. These systems rely on being able to accurately understand the intentions or meanings conveyed by text inputs in order to provide appropriate responses or actions.
Text annotations play a crucial role in natural language processing. From named entity recognition to sentiment analysis, annotations provide structure and context to unstructured text data, enabling algorithms to understand and extract meaningful information. Understanding the different types of annotations and their applications can help you make informed decisions in your NLP projects. Whether you're working on sentiment analysis, information extraction, or any other NLP task, understanding the different types of annotations and their use cases is essential.
Obsessed with helping AI developers over 5 years in the industry, we here at FutureBeeAI thrive on world-class practices to deliver solutions in every stage of AI dataset requirements, from selecting the right type of data and structuring unstructured data to stage-wise custom data collection and pre-labeled off-the-shelf datasets.
Feel free to check out other resources
🔗 futurebeeai.com/text-annotation
🔗 futurebeeai.com/blog/data-annotation-and-labeling-for-different-machine-learning- applications
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!