Machine Learning
Data Annotation
Data Annotation and Labeling Techniques for Machine Learning: A Beginner’s Guide
Everything about machine learning and data annotation for different machine learning use cases.
Machine Learning
Data Annotation
Everything about machine learning and data annotation for different machine learning use cases.

Artificial intelligence and machine learning algorithms play a significant role in guiding our daily lives, and as per the Fortune Business Insights report on the machine learning market, The global machine learning (ML) market is expected to grow from $21.17 billion in 2022 to $209.91 billion by 2029, at a CAGR of 38.8% in the forecast period. This shows that we will continue to adopt more machine learning solutions to our life but machine learning model development is not an easy task and it involves many steps as well as a lot of quality data. We can use different machine-learning processes for developing machine-learning models.
For example, a machine learning model can be developed using supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and deep learning. All these learning processes have their own pros and cons, and we choose them based on our training data and use cases. Machine learning models generally use audio, video, text, and image data for model development.
Methods like supervised learning need a lot of pre-labeled training data, which means one cannot use raw data or they must convert raw data into a well-structured form so that the machine can understand and predict the output based on any use case.
Converting raw data into a structured form is not an easy task; it involves both technology and a lot of human effort, and sometimes the process may be very time-consuming. But at this time, there is no way for supervised machine learning models to avoid this process, known as data annotation. Data annotation helps the machine to understand what information that data contains. In simple words data annotation made data speak their characteristics.
Depending on the model type and the data they used for development, we have many different types of data annotation for machine learning models, so without further delay, let's start our discussion with the fundamentals: defining machine learning, data annotation, labeling, and understanding different types of data annotation.
The term "machine learning" was coined in 1959 by Arthur Samuel, an IBM employee and pioneer in the fields of computer gaming and artificial intelligence.
Machine learning is a subfield of artificial intelligence (AI) that involves the use of algorithms and statistical models to enable computers to learn and make decisions without explicit programming. In other words, we can say that machine learning trains a machine how to learn.
In machine learning, data is used to train AI models, which are then able to make predictions or decisions based on new input data. The data may have different forms, like an image dataset, a video dataset, a text dataset, or an audio dataset. If you want to learn more about the different types of training datasets, please take a look at our blog post on All about AI Training Datasets.
Depending on machine learning use cases like speech recognition, image recognition, predictive modeling, etc. different training datasets are prepared. These datasets are prepared with the help of different annotation techniques. These annotation techniques depend on the type of data we use like image, video, text, or speech data. In supervised machine learning Image and video data are used to train computer vision applications and similarly Text and speech data are used to train Natural language processing models.
So, let’s start understanding data annotation for machine learning when dealing with different data types or different ML applications.
In machine learning, “the process of labeling and adding metadata to data in various formats, such as text, images, or video, so that machines can understand it is known as data annotation.” Data annotation is a crucial step in the machine learning process, as it helps to ensure that the data being used to train and test algorithms is accurate and relevant. It can also help to improve the performance of machine learning models by providing them with more context and information about the data they are processing.
It is especially useful for supervised machine learning, where the system relies on labeled datasets to process, understand, and learn from input patterns to arrive at desired outputs.
Various types of data annotation techniques can be used, depending on the specific needs of the machine learning task at hand.
But before we discuss the different types of annotation and labeling, let's find a basic but very important difference between annotation and labeling.
Data annotation and data labeling are two terms that are often used interchangeably to refer to the process of adding metadata or labels to data. However, there is a subtle difference between the two in the style and type of tagging the content or object of interest.
Here are the key differences:

The above discussion shows the basics of data annotation, which need to be properly followed while performing annotation tasks. We may have different requirements, and we can use many different data annotation techniques for the same.
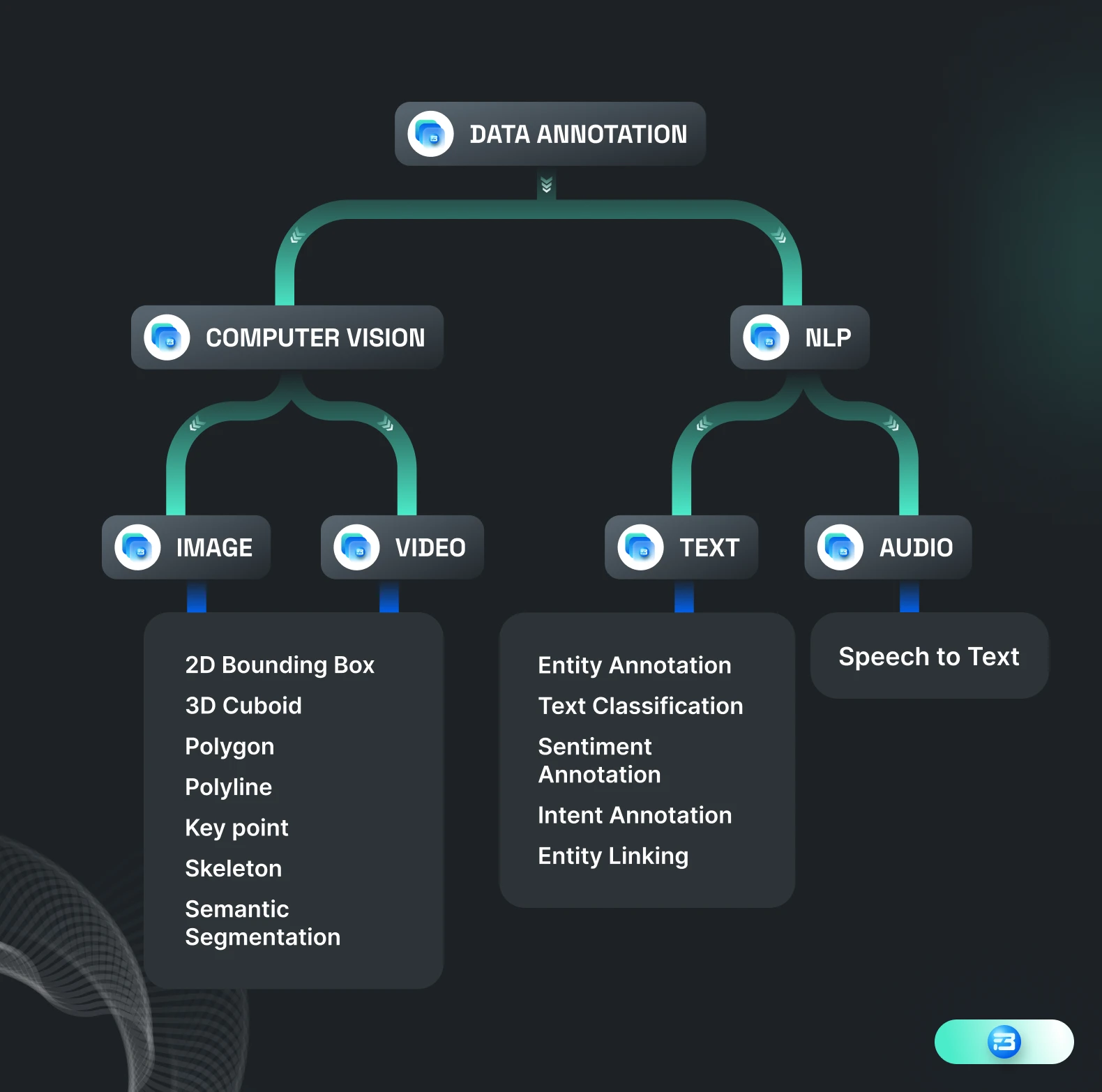
Computer vision is a field of artificial intelligence and computer science that aims to enable computers to understand and interpret visual data from the world around them, just as humans do. It involves the development of algorithms and systems that can automatically analyze, understand, and interpret images and video data. Self-driving cars and object recognition are some examples that work on computer vision. As computer vision only deals with image and video datasets, we can define their annotation techniques as below:
Image annotation is the process of labeling and categorizing images in a structured way in order to provide context and meaning to the data. In this process, we label the objects of interest in the images with specific labels so the model can build patterns and develop an understanding of the object. Image annotation can be used for a wide range of applications, including facial recognition, image classification, medical image analysis, defect inspection, etc., that can transform various sectors and industries around us. Based on different requirements we can use different image annotation techniques, here are the most commonly used data annotation techniques for computer vision.
2D Bounding box: Drawing a rectangular box surrounding a target object and it should cover the outermost boundary of the object.
3D Cuboid: It is similar to 2D bounding box the only difference is it also covers the depth of the target object.
Polygon: Polygons are created around the objects by joining dots or by using a brush. It is used for irregular and complex shapes.
Polyline: As its name suggests, annotators simply draw lines along the boundaries you require your machine to learn.
Keypoint: Keypoint annotation, also known as landmark annotation or dot annotation, is the process of identifying and labeling specific points of interest on an object in an image.
Keypoint skeleton: When we connect different keypoint with vectors then it is known as key point skeleton used for pose estimation.
Semantic segmentation: Semantic segmentation can be defined as the grouping of the same parts or pixels of any target object in a given image or clustering parts of an image together which belong to the same object class.
Each type has different applications and is used for the development of computer vision AI models, there may be some more types of image annotation available.
Video annotation is the process of labeling and categorizing video data in a structured way in order to provide context and meaning to the data. Video annotation can be used for a wide range of applications, including object tracking, activity recognition, and event detection. It involves labeling specific objects or regions within a video frame and tracking those objects or regions over time.
Video annotation uses the same techniques as image annotation and is most commonly used for computer vision AI models.
Natural Language Processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. It focuses on making it possible for computers to read, understand, and generate human language. Some tasks that are commonly associated with NLP include language translation, sentiment analysis, and speech recognition. Natural language processing deals with text and speech data, and based on that, we can define their annotation techniques as below:
Text annotation can be defined as assigning labels or metadata to an entire document or different parts of its content, like keywords, phrases, and sentences. The annotated text helps machines to understand the context of human languages.
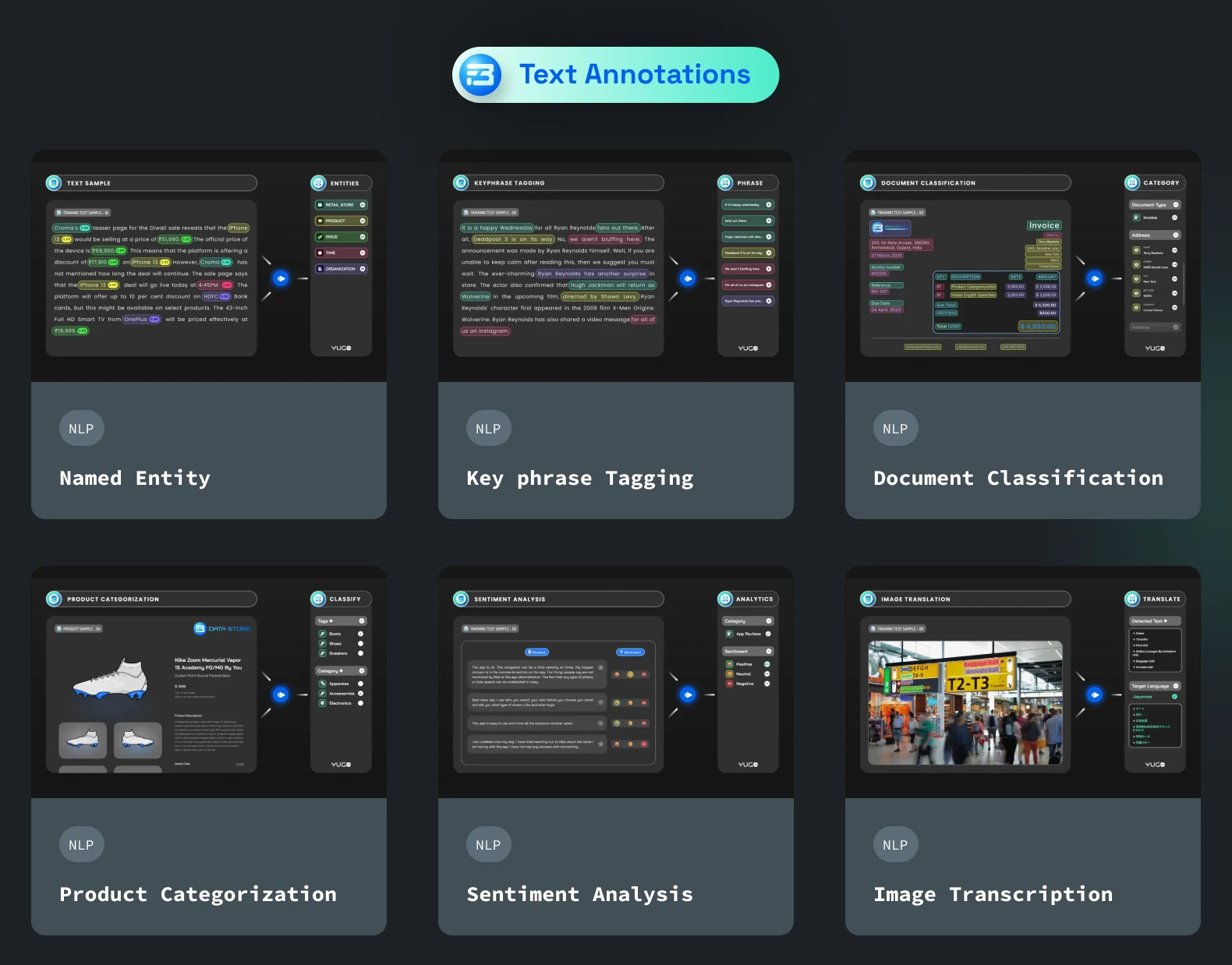
As the name suggests, it is used to label unstructured sentences with important entities. The entity may have a name, location, key phrase, verb, adverb, etc. This is often used for chatbot training and can also be defined as the act of locating, extracting, and tagging entities in text. Depending on the application, we can further describe this annotation in the following ways:
Named Entity Recognition (NER) tagging: : This is used for identifying and labeling named entities from text. Named entities are specific persons, organizations, locations, or other concepts that are mentioned in the text.
Part-of-speech (POS) tagging: Part-of-speech tagging helps us parse sentences and identify grammatical units, such as nouns, pronouns, verbs, adverbs, adjectives, prepositions, conjunctions, etc.
Keyphrase tagging: This one can be described as locating and labeling keywords or keyphrases in textual data.
The above three types of entity annotation often go hand-in-hand with entity linking to help models contextualize entities further.
Entity linking, also known as named entity linking (NEL), is the process of identifying and linking named entities in a text to their corresponding entries in a knowledge base or database. For example, if a text mentions "Barack Obama," entity linking would identify that the named entity refers to a specific person and link it to the corresponding entry in a database of people, which may include additional information about the person such as their biographical details and career achievements.
Text classification is the process of assigning a label or category to a chunk of text or lines with a single label. It is used in a variety of applications, including spam filtering, sentiment analysis, topic classification, document categorization, etc.
Document categorization: Document categorization is the process of assigning a label or category to a document based on its content. It can be useful for the intuitive sorting of massive amounts of textual content.
Product categorization: Product categorization is the process of assigning a label or category to a product based on its characteristics or features. Product categorization is used to organize and classify products into predefined categories or labels, which can be used for various purposes such as product search and navigation, recommendation systems, and marketing analysis.
Sentiment annotation: Sentiment annotation is also known as sentiment analysis or opinion mining used to identify and label emotions (like sad, happy, angry) and opinions in any given text data or individual segments of text as positive, negative, or neutral.
Intent annotation: Intent annotation, also known as intent classification, is the process of identifying and labeling the intention or purpose behind a piece of text or a user's input. Intent annotation involves classifying a text or input into one or more predefined categories or classes, such as a request for information, a request for help, a complaint, or a request to make a purchase.
Audio annotation is the process of labeling and categorizing audio data, such as speech, music, or other sounds.
There are several types of audio annotation, depending on the specific task or application. Some examples include.
Speech annotation: Labeling the transcript of a spoken audio recording, including identifying and labeling words, phrases, and other elements of the transcript.
Music annotation: Labeling the characteristics of a musical audio recording, such as the genre, instrumentation, and mood.
Sound event annotation: Labeling the specific sounds or events in an audio recording, such as car horns, footsteps, or door slams.
Audio annotation is an important task in natural language processing and is used in a variety of applications, such as speech recognition systems, speaker identification systems, language identification systems, and music classification systems. It can also be used to improve the accuracy and effectiveness of audio search engines and information retrieval systems.
Data annotation is an important process in machine learning because it helps to provide structure and context to the data, making it more useful for training machine learning models. When data is properly annotated, it becomes easier for machine learning algorithms to understand and learn from.
There are several reasons why data annotation matters in machine learning:
Improved model performance: Properly annotated data can lead to better performance from machine learning models. By providing the model with clear, structured information about the data, the model is able to learn more effectively and make more accurate predictions.
Increased efficiency: Annotated data can also help to streamline the machine learning process by reducing the amount of time and effort required to understand and process the data. This can help to make the machine learning process more efficient and cost-effective.
Enhanced interpretability: Annotated data can also make it easier to understand and interpret the results of machine learning models. By providing context and structure to the data, it becomes easier to understand how the model arrived at its conclusions and to identify any potential issues or limitations.
Overall, data annotation is an essential part of the machine learning process, as it helps to ensure that the data is suitable for training machine learning models and leads to better model performance and increased efficiency.

Data annotation is a crucial step in the process of developing machine learning models, but it can be a challenging and time-consuming task. Fortunately, FutureBeeAI offers assistance with data annotation and labeling for a wide range of applications. Without proper annotation, it is difficult to create effective predictive models. Let FutureBeeAI help you overcome this obstacle and move forward with your machine learning projects.
Accurate data annotation is critical for the success of machine learning projects. It can be performed efficiently by experienced annotators or through automation. However, not all organizations have the necessary resources to handle large-scale annotation tasks, and relying on inexperienced annotators can result in a significant time and financial investment. FutureBeeAI can assist with planning and executing a successful data annotation strategy through our experienced annotator community. Let us help you ensure the quality and precision of your annotation efforts.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!