Have you seen the recent launch of Gemini by Google? As you may have noticed in the video shared by Google, someone was drawing on paper and asking Gemini to predict the same. The platform, Gemini, was not only predicting but also sharing information related to the given drawing. This type of model is considered multimodal because it is capable of reasoning seamlessly across text, images, video, audio, and code.
These models are capable of understanding text, images, video, audio, and code because they are trained with the help of multiple training datasets, including speech data, video data, code, and image data. In our previous blogs, we have discussed speech data, different types of speech data, the speech data collection process, and many other things related to speech and text. So, in this blog, we will discuss image datasets, especially Image based questions answer datasets, that are used to train models like Gemini.
So, let’s start understanding the visual question answering.
What is Visual Question Answering?
 Earlier, we were labling images to predict objects in images and videos. But with advancements in computer vision and natural language processing, we are now able to predict what an image or video contains by just asking an AI model.
Earlier, we were labling images to predict objects in images and videos. But with advancements in computer vision and natural language processing, we are now able to predict what an image or video contains by just asking an AI model.
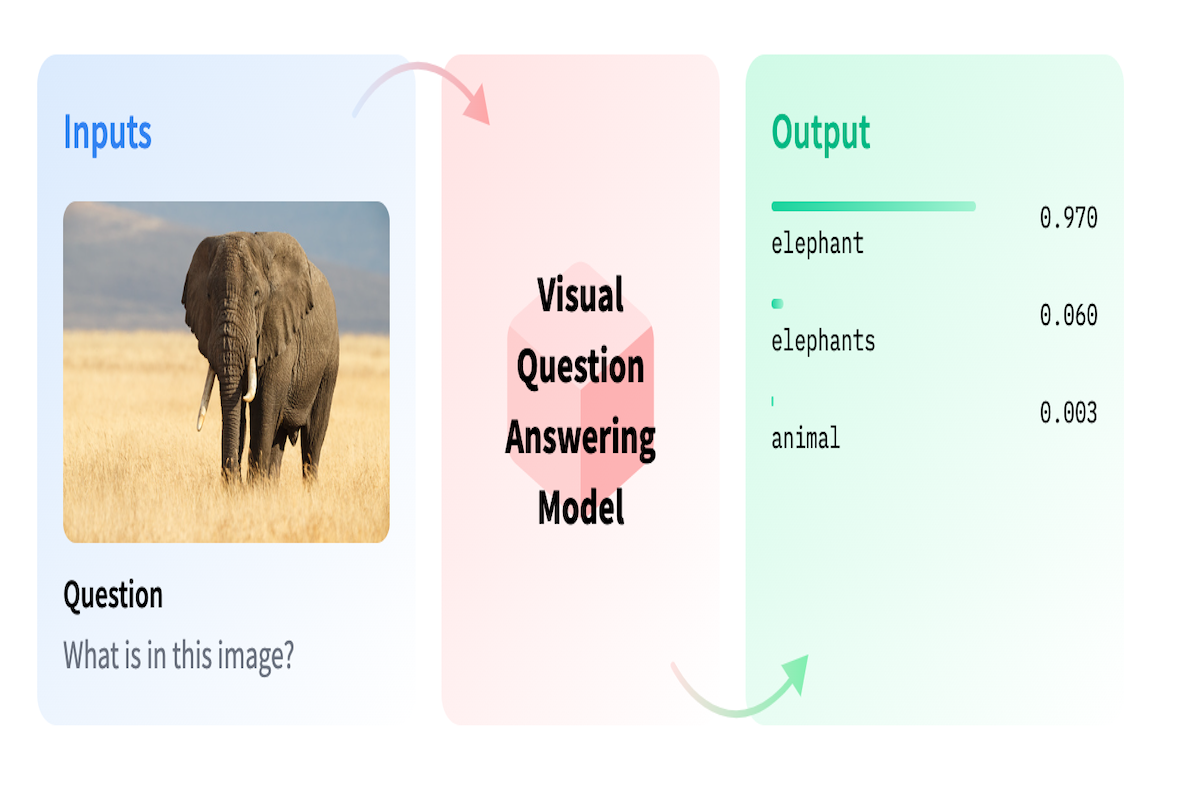
Visual Question Answering (VQA) is a cutting-edge area of artificial intelligence that combines computer vision, natural language processing, and machine learning techniques. It focuses on teaching machines to comprehend and respond to questions about images.
In simple words, a VQA system takes an image and a free-form natural language question about the image as input (e.g. “What is the color of the girl’s shoes?” or “Is the boy jumping?”), and produces a natural language answer as its output (e.g. “black”, or “yes”).
The goal of VQA is to bridge the gap between visual content and textual information, allowing AI systems to process both visual data (images) and textual data (questions) to generate meaningful answers.
To train a model that can read images and predict answers, we need to prepare a dataset that has images and question-answers related to images. Let’s understand what is image based question answer datasets are.
Image Based Question Answer Datasets
 Image-based question answering datasets are collections of images paired with corresponding questions and answers. These datasets are specifically curated to train and evaluate algorithms that aim to comprehend images and respond to questions related to those images.
Image-based question answering datasets are collections of images paired with corresponding questions and answers. These datasets are specifically curated to train and evaluate algorithms that aim to comprehend images and respond to questions related to those images.
These images show lots of different things, like animals, people, places, and more. The questions are written in words and ask things about what's in the pictures, like "What color is the car?" or "How many apples are there?"
To create an image-based question answering dataset, we can start by gathering various use case specific images that showcase different scenes, objects, and activities. After collecting images, let’s say we are collecting images from different magazines. Now we can create a diverse set of questions related to these images, covering aspects like the type of magazine, who is featured on the magazine, what the topic of the magazine is, and actions that people might ask about. And then we will pair each question with its correct answer based on the content of the image.
To ensure diversity in the answers, we can add answers ranging from single words to detailed descriptions.
Many open sourced Image based question answers datasets are available and can be used for initial research and training. Here are some of them;
VQA (Visual Question Answering)
This is one of the most widely used datasets for image-based QA. It contains images from the COCO dataset paired with open-ended questions and multiple-choice answers about the images. The questions cover various aspects, requiring models to understand scenes, objects, relationships, and more.
CLEVR (Compositional Language and Elementary Visual Reasoning)
CLEVR focuses on synthetic images that require reasoning about simple shapes, colors, sizes, and spatial relations. Questions in this dataset often involve logical reasoning and require understanding relationships between objects.
Visual7W
This dataset focuses on seven "W" questions (Who, What, Where, When, Why, Which, and How) associated with images. It contains questions in natural language, each associated with an image from the Visual Genome dataset.
VizWiz
This dataset is specifically tailored for visually impaired individuals. It comprises images captured by blind users along with natural language questions about the images. The questions often involve aspects that sighted individuals might take for granted but are challenging for AI systems without proper training.
Use case specific Image based Question answer dataset
If you are developing a VQA based model and want use case specific image based question answer dataset, then FutureBeeAI can help you collect images and prepare question answers based on the images. FutureBeeAI have extensive team across the globe that is capable of collecting images for different use cases and can support multilingual image based question answer data preparation.
Now that we have understood the basics of VQA and image based question-answer datasets, let’s see some of the applications.
Use cases of Visual question answering models
Visual Question Answering (VQA) models find applications across various domains due to their ability to comprehend images and answer related questions. Some notable use cases include:
Assistive Technology
VQA assists visually impaired individuals by providing information about their surroundings. By capturing and analyzing images, these systems can answer questions about objects, scenes, or text within the visual field, enhancing accessibility.
Content Moderation
Social media platforms and content-sharing websites can employ VQA to moderate content. It can help identify and filter inappropriate or harmful images by understanding the context through questions and answers associated with the content.
Education and E-Learning
VQA can be integrated into educational platforms to create interactive learning experiences. Students can ask questions about images in textbooks or learning materials, receiving immediate answers to enhance their understanding.
Healthcare Imaging Analysis
VQA can aid medical professionals in analyzing medical images by answering questions about anatomical structures, conditions, or anomalies present in the images. This assists in diagnostics and treatment planning.
E-Commerce and Image Search
Online shopping platforms can utilize VQA to enhance image search capabilities. Users can ask questions about products they see in images, making the search process more intuitive and efficient.
Video Search
Specific snippets/timestamps of a video can be retrieved based on search queries. For example, the user can ask, "At which part of the video does the guitar appear?" and get a specific timestamp range from the whole video.
These applications demonstrate the versatility of VQA models in fields ranging from accessibility and education to healthcare and e-commerce. The ability of these models to understand visual content and respond to natural language queries opens up diverse opportunities for innovation and improvement across industries.
Conclusion
The era of multimodal AI models has just begun, and we will see many models like Gemini and Open AI. For building these types of models, the demand for image based question answers will increase, and organizations with quality data and robust models will serve the world better!