Wake word detection is not glamorous. It does not get whitepapers and it rarely appears in model diagrams. Yet, it is the hinge on which every voice system turns. If the wake word fails, nothing else matters.
You can have a state-of-the-art ASR model and a flawless NLP stack. If your assistant never wakes up or wakes up at the wrong time, the experience collapses. And too often, the failure is not in the model but in the dataset that trained it.
This blog is for the teams who have been there: engineers chasing down false activations, researchers balancing false positives and false negatives, and product leads wondering why reliability metrics refuse to improve. We have built wake word datasets across languages, accents, devices, and environments. This is what we have learned about what most datasets miss, how those blind spots show up in production, and how to design data that holds up when it matters most.
When Wake Word Models Fail, Your Dataset Is Speaking

Wake word models rarely break in obvious ways. They simply stop listening when they should or trigger when no one is calling them. In testing, the numbers look fine. Precision and recall meet the targets. Logs are clean. But once deployed, things unravel:
The assistant ignores a voice from across the room.
It wakes up when a TV host says something similar.
It struggles with regional accents or rushed, natural speech.
It misfires with children’s voices or softer tones.
These are not random anomalies. They are the dataset revealing its blind spots. Most teams respond by tweaking architectures or retraining. But the truth is, the failures are feedback: your model is only as good as the data signals you gave it.
Why Wake Word Datasets Are Uniquely Hard
It is tempting to think wake word datasets are just smaller versions of general speech datasets. They are not. The challenges are sharper, the stakes higher.
1. Binary and unforgiving
Wake word detection is yes or no. A decision often made in under a second. There is no partial credit. A false negative frustrates the user. A false positive risks privacy.
2. Real-time under chaos
Wake words are spoken in cars, kitchens, offices, and parks. People whisper, shout, chew, laugh, and multitask. Yet the system must respond instantly, without hesitation.
3. Confusable near-negatives
Noise is manageable. The real threat is words that sound too similar: “Hey Ava” versus “Hey Eva” or “Hey bro.” Without near-negatives in your data, the model cannot learn the difference.
4. Bias shows up instantly
Many datasets skew toward young, male, urban voices recorded in quiet rooms. In production, this becomes obvious. Older users, women and regional speakers are ignored.
Wake word data is not hard because it is large. It is hard because it must be surgical. You are training a model to recognize a precise acoustic fingerprint in messy, noisy, diverse reality.
Principles of Designing Robust Wake Word Datasets
Strong wake word datasets are not accidents. They are engineered with deliberate design. Six principles matter most:
1. Balance positives, negatives, and near-negatives
Do not only collect wake words. Include unrelated phrases (negatives) and confusable ones (near-negatives). This balance trains the model when to wake and when to stay quiet.
2. Engineer diversity at every layer
Cover accents, age groups, genders and regions. Vary devices and environments: cars, kitchens, offices, and outdoor settings. A narrow dataset produces biased performance.
3. Capture natural variation
No one says the wake word the same way twice. Some rush, others stretch, some whisper, some shout. Data must reflect this natural variation or the model will fail in real use.
4. Control quality without killing realism
Check for clipping, distortion, and artifacts. But do not sanitize away everyday noise or reverberation. Overly clean data leads to brittle models.
Audio alone is not enough. Tag speaker demographics, environment, pace, device type, and noise conditions. Metadata makes debugging and rebalancing possible.
6. Align design with deployment
A dataset for smart speakers is not the same as one for cars. Context defines balance. Without this alignment, lab results will not survive production.
The Wake Word Dataset Lifecycle
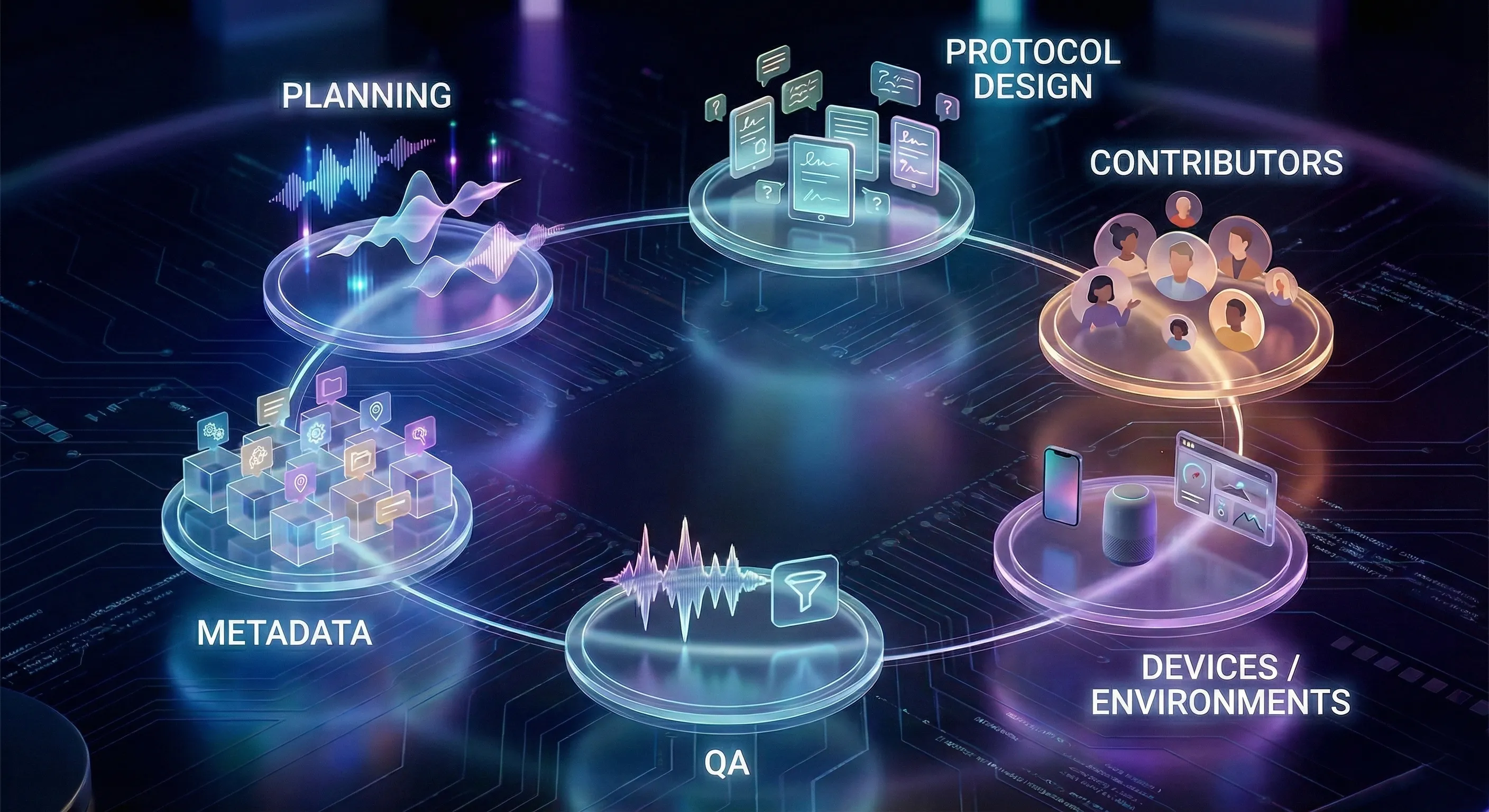
Designing a dataset is not just recording audio. It is a structured life-cycle that ensures reliability:
1. Planning
Define wake words, their variations, and near-negatives. Align with deployment context from the start.
2. Protocol and script design
Craft prompts that encourage natural delivery. Set the mix of positives, negatives and near-negatives. Avoid robotic, scripted recordings.
3. Contributor recruitment and diversity setup
Build a balanced pool across demographics and accents. Apply quotas to prevent bias with the help of crowd-as-a-service solutions.
4. Data collection across devices and environments
Record on multiple microphones, smartphones, smart speakers, and in varied spaces: quiet rooms, kitchens, moving cars. This step is a core part of AI data collection.
5. QA and rejection workflow
Filter out clipping, distortion, silence or mispronunciations. Faulty samples are recollected to maintain integrity.
Add speaker attributes, environment labels, device info, and pacing. Package audio with structured metadata for easy use in pipelines. This is where data annotation services matter.
A wake word dataset built this way is not a pile of recordings. It is an engineered asset, ready for production.
How FutureBeeAI Approaches Wake Word Dataset Design

At FutureBeeAI, we have learned that dataset size alone does not deliver reliability. Precision and design do.
We start with intentional planning: defining wake words, near-negatives and environments of use.
Our Yugo platform enforces discipline: contributor onboarding, demographic verification, device checks, real-time QA and metadata tracking. Compliance and consent are built-in.
Our verified global FutureBeeAI community spans thousands of speakers across languages, regions and devices. This diversity fills the gaps that most datasets leave behind.
The combination of design, platform and community means our datasets mirror reality, not lab conditions. That is why models trained on them behave consistently in production.
Better Data Beats Bigger Models

Wake word detection may not be glamorous but it is where everything begins. Most production failures do not come from weak architectures but from fragile data.
A strong wake word dataset is not about collecting endlessly. It is about designing intentionally: balancing positives and near-negatives, ensuring diversity, capturing natural variation and embedding rich metadata.
Bigger models cannot fix missing signals, better data can. That is the mindset we bring to every project at FutureBeeAI, because reliability does not come from hype, it comes from anticipating the real world before your users ever say the wake word.






