In our ongoing exploration of the intricacies of invoice data and how AI can streamline invoice processing, our previous blog shed light on fundamental aspects of invoice data and the imperative for AI adoption in this domain.
Today, we aim to zoom in on a specific aspect: the invoice dataset. Our focus will be to dissect each component of an invoice dataset in a straightforward yet informative manner. Let's dive into the details
What is an invoice dataset?
An invoice dataset serves as a carefully organized set of invoices crafted explicitly for training and evaluating artificial intelligence models dedicated to understanding and processing invoices. It forms the bedrock where AI algorithms gain the ability to interpret and extract crucial details from invoices, turning unstructured data into practical insights.
A top-tier invoice dataset is characterized by its inclusive collection of diverse invoices, complete with the necessary metadata and annotations. The inclusion of metadata and annotations adds precision, guiding the model in understanding key elements within the invoices. The result is an invaluable resource that empowers AI systems to navigate the intricacies of real-world invoice processing with accuracy and efficiency.
Importance of Invoice Dataset
An inclusive invoice dataset serves as a valuable resource for training and testing AI models. Its role extends beyond automating the invoice handling process; it transforms seemingly unattainable unstructured data into actionable insights.
Training Robust AI Models
Developing robust AI models hinges on the quality of the dataset used for training. By exposing the model to a diverse array of invoice formats and variations, it learns to generalize and accurately process different types of invoices encountered in real-world scenarios.
The accurate extraction of both structured and unstructured data from invoices is crucial for successful automation. A meticulously curated dataset plays a pivotal role in training models to recognize patterns, ultimately improving the accuracy of information extraction.
Handling-Real-world-Variability
Invoices manifest in various formats, languages, and structures. An invoice dataset that mirrors this real-world variability ensures that the AI model is adaptable, proficiently navigating the intricacies of invoices received from diverse vendors and industries.
Enabling Generalization Across Industries
Different industries boast unique invoice structures and requirements. An inclusive dataset empowers the AI model to generalize its understanding, rendering it applicable not only within a specific sector but across various industries that rely on invoices.
The comprehensive nature of such a dataset enriches the training process, equipping AI models to handle the complexities and variations inherent in real-world invoicing scenarios.
Different Types of Invoice Datasets
In the realm of invoice datasets, various types exist, and it's crucial to align your choice with your specific use case. This section aims to guide you in identifying and determining your precise invoice dataset requirements, serving as a valuable resource as you embark on the journey of dataset acquisition.
Industry-Specific Invoice Dataset
Invoices exhibit nuanced differences across various industries, spanning healthcare, retail, and manufacturing. Each industry's invoices encapsulate crucial and context-specific data, including industry-specific formats, terminology, and nuanced intricacies. This rich and industry-tailored information proves invaluable for training AI models, enabling them to grasp the idiosyncrasies of a particular sector and specialize accordingly.
 When procuring an invoice dataset, it becomes imperative to clearly define your target audience and construct an ideal consumer persona. This strategic approach assists in determining whether to focus on acquiring a dataset specific to a particular industry or opt for a more diversified dataset encompassing various invoice types across different sectors.
When procuring an invoice dataset, it becomes imperative to clearly define your target audience and construct an ideal consumer persona. This strategic approach assists in determining whether to focus on acquiring a dataset specific to a particular industry or opt for a more diversified dataset encompassing various invoice types across different sectors.
Understanding the distinctive features embedded in industry-specific invoices empowers AI models to not only recognize standardized information but also decipher the unique attributes that define each sector. By tailoring the dataset to specific industries, the AI model gains a more profound understanding of the contextual nuances, ultimately leading to enhanced accuracy and efficiency in invoice processing.
Business-Specific Invoice Dataset
Just like how different industries have their way of doing things, invoices also come in various types, depending on the type of business. For instance, invoices for business-to-consumer (B2C) transactions are different from those used in business-to-business (B2B) dealings.
B2C invoice Dataset
B2C invoices operate between the direct consumer and business and a B2C invoice dataset is a specific collection of such B2C transactions across different industries.
Consider an invoice generated by an e-commerce company for an online order. In this scenario, the invoice may include limited but consumer-specific information such as the customer's name, contact details, and address.
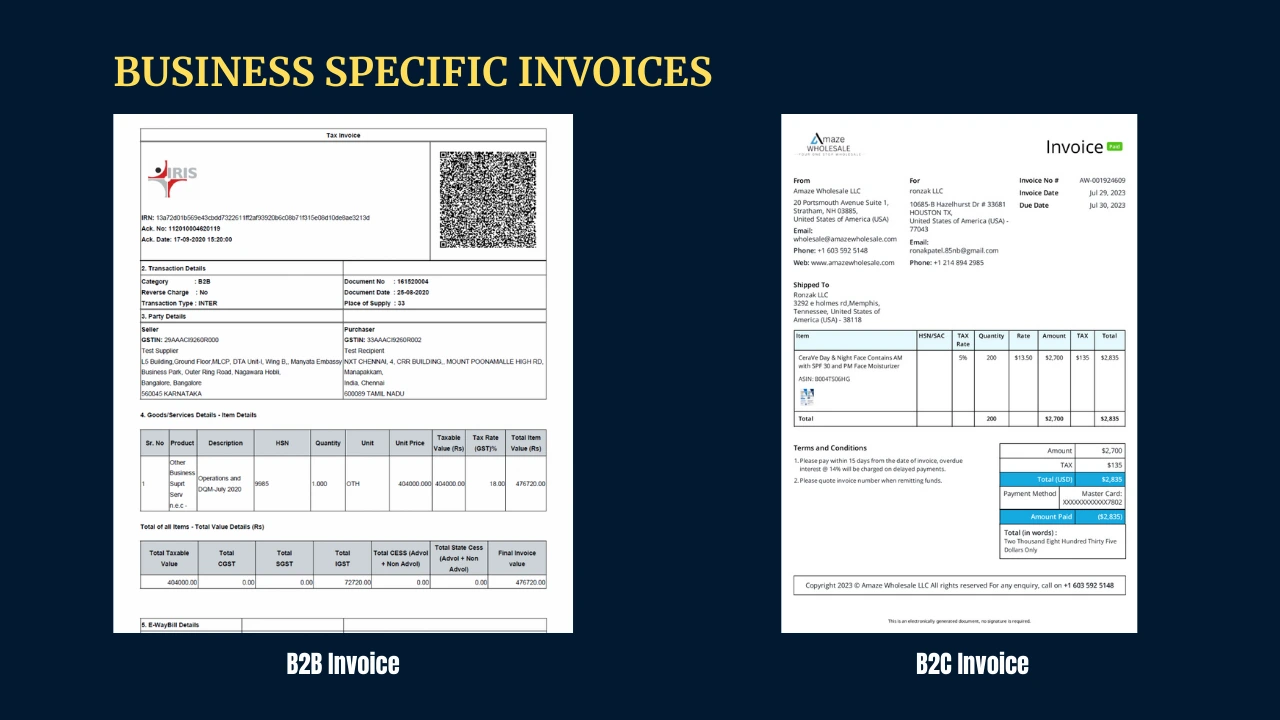 B2B invoice Dataset
B2B invoice Dataset
B2B invoices, on the other hand, involve transactions between businesses. A B2B invoice dataset is a collection of these business-to-business transactions across different types of businesses and industries. Consider an invoice from a supplier to a manufacturing company – it could have a lot more details. This might include important stuff like bank details, addresses of warehouses or storage places, hieratical signature flow, and other specifics relevant to the complexities of business-to-business transactions.
Understanding these different types of invoices is crucial for creating AI models that can handle the various ways businesses structure their data. This helps the AI be smart and adaptable in different business environments.
Multilingual Invoice Dataset
A multilingual invoice dataset comes in two types. The first one includes invoices in various languages, and the second one has invoices with specific details presented in different languages.
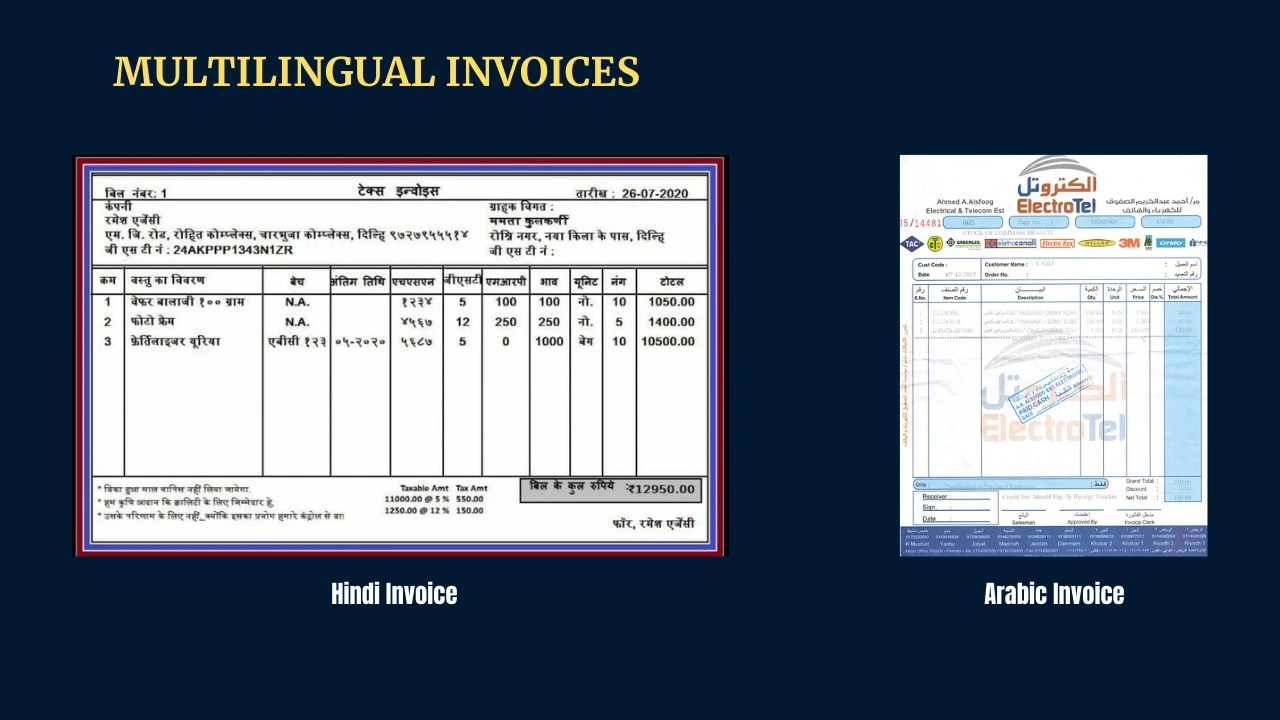 It's important to decide if you need a multilingual dataset based on your specific requirements. If your AI model is supposed to work globally and handle invoices from different language backgrounds, choosing a dataset with invoices in multiple languages is important. But if you're mainly focusing on English-language invoices, a dataset that includes multilingual details within English-language invoices might suit your training goals better.
It's important to decide if you need a multilingual dataset based on your specific requirements. If your AI model is supposed to work globally and handle invoices from different language backgrounds, choosing a dataset with invoices in multiple languages is important. But if you're mainly focusing on English-language invoices, a dataset that includes multilingual details within English-language invoices might suit your training goals better.
Picking the right multilingual dataset ensures that your AI model is ready to deal with different language situations, making it more versatile for real-world use.
Text-form Specific Invoice Dataset
You've probably seen some invoices that are all nicely printed, and others where someone has handwritten the details, right? Well, when it comes to training AI models, we can have datasets specifically for printed invoices and others for handwritten ones.
Printed Invoice Dataset
Printed invoices are usually seen in Business-to-Business (B2B) transactions. These invoices follow a set format – they're created by professionals and have a neat layout and similar fonts, and everything is in its usual place. A printed invoice dataset helps AI models get good at pulling information from these well-organized documents.
 Handwritten Invoice Dataset
Handwritten Invoice Dataset
Now, when it's Business-to-Consumer (B2C) transactions, things often get more personal, and we end up with handwritten invoices. These have a touch of individuality – different writing styles, ink shades, and a unique personal expression. Dealing with this variety calls for a special dataset. It helps the AI model learn to understand and extract info from the more flexible and personal nature of handwritten invoices.
Understanding the difference between printed and handwritten invoice datasets is important when building AI models. It helps them handle the complexities of both B2B and B2C invoicing. Each type of dataset teaches the model in its way, making sure it's well-equipped to deal with all sorts of invoices in different business settings.
Real or Synthetic Invoice Dataset
When getting an AI model ready for invoice processing, you've got two main options for the data it learns from – real invoices or synthetic ones. These choices might sound similar, but they're pretty different.
Real Invoice Dataset
A real invoice dataset is made up entirely of actual, genuine invoices. This means it includes the real deal – the invoices that businesses use every day. It gives the AI model a taste of the real world, with all its diversity, complexity, and differences you find in actual invoices.
Why is this realness important? Well, training an AI model with authentic challenges helps it get used to all the different types of invoices from various industries, vendors, and places. It's like giving the model a sneak peek into what it will face in the real world.
Real invoices can be all over the place – different formats, various languages, and diverse structures. By throwing these challenges at the model during training, it learns to be flexible and understand the many different parts of an invoice.
 Synthetic Invoice Dataset
Synthetic Invoice Dataset
On the flip side, synthetic invoice datasets are a bit like creating invoices in a virtual world. They're not real invoices but are made to look and act like them. At FutureBeeAI, we use a special blueprint to make synthetic invoice datasets that come pretty close to the real deal.
Why go synthetic? Well, it lets developers add in controlled changes, simulate specific situations, and mix things up in the training data. This is handy when you want the AI model to learn from situations that don't happen often in the real world or when you need to whip up a dataset quickly on a tight budget.
Here's the sweet spot – using both real and synthetic datasets together. Real ones give the AI model a solid base of what's real, while synthetic ones bring in a bit of spice and challenge. It's like having the best of both worlds.
Deciding which dataset to use depends on a bunch of things – how complex your needs are, the budget, the timeline, and more. It's about finding the right balance for your AI model to learn and become a pro at handling invoices in the wild!
Time-bound Invoice Dataset
As time goes on, business rules, taxes, and the way companies operate can change. So, if we train our AI model using old invoices, it might not be very helpful. In such cases, we need to consider a few things about how the business environment has changed and decide on a starting point, like a base year.
This time-sensitive invoice dataset includes invoices that represent what's been happening after we've decided on that base year. It's a good way to get a dataset that's up-to-date and helps our AI model get better at handling invoices.
Now, let's chat about the different kinds of invoices in our dataset!
Diversity in Invoice Dataset
Diversity is crucial when it comes to datasets—it's the top priority on the checklist when you're acquiring or collecting a dataset. This holds for invoice datasets too. Now, the level of diversity depends on what you need and how you're planning to use it. But, let's discuss a few things that make a dataset diverse and a good representative of what's out there.
Things change drastically in the invoice with the format. With diverse invoice formats, we mean to have different colors, fonts, styles, header and footer variations, product or service table grids and styles, and many more variations.
Having a dataset that shows all these different styles is super important for teaching artificial intelligence (AI) models. The idea is to let the AI model see all the different ways invoices can look in the real world. This helps it get good at understanding and handling information, no matter how it's formatted.
Including all these different format elements in the dataset isn't just about making the model flexible. It's also about getting ready to deal with tricky situations. Whether it's weird fonts, funky colors, or creative table setups, the dataset is like a practice field for the AI model to learn how to read and grab the right information accurately.
Size and Pages
Invoices exhibit diversity not only in content but also in their physical attributes, varying in size and orientation. They may manifest in either portrait or landscape formats, each presenting unique challenges and nuances in information representation.
Within these formats, the types of information can be structured differently, adding another layer of complexity. For instance, a portrait-oriented invoice might distinctly organize details compared to its landscape counterpart, requiring an adaptive approach in AI model training.
Moreover, invoices extend beyond mere individual pages; they can be single-page documents or span multiple pages. Multipage invoices are a common occurrence, often attributed to an extensive list of products or services. Alternatively, additional exhibits, such as supporting documentation or terms and conditions, contribute to the need for multi-page invoices.
Understanding and accommodating the variability in both size and page count is pivotal in the development of an effective AI model for invoice processing. The model's ability to discern information across different orientations and navigate through multipage documents ensures a comprehensive grasp of the intricacies presented by diverse invoices in the real world.
Printed and Handwritten
As discussed earlier, printed and handwritten invoices present distinctive challenges in the realm of invoice processing.
Printed invoices typically adhere to standardized formats, making them relatively easier for Optical Character Recognition (OCR) technologies to decipher. The structured nature of printed invoices facilitates the extraction of key details such as invoice numbers, dates, and totals with a higher degree of accuracy.
On the other hand, handwritten invoices introduce a layer of complexity. The variability in handwriting styles, coupled with potential illegibility, poses a unique set of challenges for AI models. The adaptability of the model becomes crucial when confronted with the inherent unpredictability of handwritten content.
Navigating through both printed and handwritten invoices in a dataset is essential for a comprehensive AI model. The inclusion of both types ensures that the model is adept at handling the diverse ways in which invoices can be presented in the real world.
Along with that printed invoices are mainly in PDF format whereas handwritten invoices are in scanned or raw image format. A high-quality invoice dataset may include both of these types of invoices.
Industries Variation
As previously highlighted, invoices exhibit considerable diversity, tailoring their content to the specific needs of various industries. A high-quality and representative invoice dataset should encompass a broad spectrum of invoices originating from different industries. This inclusivity is pivotal in enabling the AI model to acquire a versatile skill set, ultimately enhancing its efficiency and adaptability across diverse industries.
The significance of incorporating invoices from various sectors lies in the unique formats, terminologies, and nuances specific to each industry. For instance, healthcare invoices may contain distinct elements compared to those in the retail or manufacturing sectors. By exposing the AI model to this range of industry-specific nuances, the dataset becomes a powerful tool for training the model to recognize and process invoices with precision, regardless of the sector they belong to.
The practical implication of using an industry-diverse dataset becomes evident in real-world applications. Businesses often operate in multi-faceted environments, engaging with partners and clients across different sectors. An AI model trained on a dataset that mirrors this diversity is better equipped to handle the variability in invoice structures encountered in day-to-day operations.
Data Diversity
In addition to accounting for other forms of variation, the diversity in data within an invoice dataset is paramount. The dataset should encompass a comprehensive range of ways in which various types of information are represented. This includes but is not limited to, company names, addresses, contact numbers, email addresses, invoice details, product specifications and descriptions, discounts, taxes, overall amounts, bank details, and more.
Ensuring that the dataset captures the multitude of ways this information can be presented is essential for training a robust AI model. Company names, for instance, may vary in structure, containing abbreviations, special characters, or legal identifiers. Similarly, addresses can manifest in diverse formats, including variations in street names, city spellings, and postal codes.
Contact numbers and email addresses may exhibit different patterns, such as regional variations in phone number formats or diverse email domain structures. Invoice details, encompassing elements like invoice numbers and dates, should be represented in various styles to enable the model to recognize patterns effectively.
Product details and descriptions are often expressed in free-form text, presenting a challenge for the model to extract relevant information. Discounts and taxes may be denoted in percentages, decimal numbers, or varied textual representations. The overall amount, a critical component, can be presented in different currencies and numerical formats.
Additionally, bank details, crucial for payment processing, should encompass the range of structures and formats found in real-world invoices. By simulating this diversity in the dataset, the AI model learns to navigate the intricacies of varied invoice formats, ensuring adaptability to the dynamic nature of data representation in actual scenarios. This emphasis on data diversity is fundamental to the model's capacity to generalize effectively and perform accurately across a spectrum of real-world invoice processing scenarios.
Other Invoice Elements
Beyond the core components, an invoice dataset can encompass a variety of additional elements that are commonly present in real-world invoices. These may include company logos, QR codes, multiple addresses, detailed delivery information, terms and conditions, additional notes, headers, and footers.
Including these diverse elements in the dataset reflects the richness of real-world invoice scenarios. Company logos and branding elements, for example, add a layer of visual complexity, while QR codes may require specialized processing. Multiple addresses and detailed delivery information contribute to a more comprehensive understanding of the supply chain, and terms and conditions provide context to the financial transactions.
Recognizing and extracting information from these additional elements poses a unique challenge. The dataset's inclusion of such elements allows the AI model to learn and adapt to the varying ways in which businesses structure and present their invoices. Incorporating other invoice elements into the dataset expands the scope of the AI model's training, preparing it to handle the intricacies found in real-world invoices.
Ending Noted
I hope our discussion so far has given you a clearer picture of what a typical invoice dataset might have and how diverse it can get. To put it simply, the variety depends on what you need for training your AI or OCR model.
Getting an off-the-shelf (OTS) invoice dataset or collecting your own as per your specific requirements can be a bit tricky, but guess what? We might have a solution for you at FutureBeeAI!
We've got a bunch of ready-made OCR datasets that can make the process of getting your hands on an invoice dataset a whole lot easier. Or, if you've got specific needs, we can help you create a custom invoice dataset that fits the bill.
Feel free to drop us a line if you have any questions about OCR datasets. We're here to help!