A healthcare technology company builds an NLP model for clinical documentation. The model clears internal benchmarks. It passes model evaluation. It goes live. Within weeks, clinicians begin flagging outputs that are inconsistent in ways that do not look random. Certain input patterns produce unreliable classifications and the variance follows a pattern that no one on the model team can fully explain. The post-mortem takes months. When the root cause is finally identified, it is not in the model architecture. It is in the training data. Specifically, it is in annotation inconsistencies that post-collection review never caught, because the inconsistencies were not errors in individual annotations, they were the direct output of task instructions that allowed annotators to interpret the same scenario in legitimately different ways.

This failure is not rare and it is becoming more costly. Enterprises are now scaling domain-specific model training across regulated industries at volumes where the crowd data consumed in a single pipeline far exceeds what teams reviewed manually even two years ago. Quality assurance shortcuts that were manageable at smaller scale are compounding into production failures that look like model problems, get diagnosed as model problems, and are treated as model problems through multiple retraining cycles before anyone traces them far enough back to find the actual origin. The scale of quality assurance in crowd-sourced AI data has changed. The industry's dominant approach to it has not.
Why the industry's default QA approach is structurally insufficient
The dominant practice among AI data vendors is to treat quality assurance as a deliverable metric applied after collection. A dataset is produced, a review layer is run against it, and an accuracy rate is reported. This is the standard. It is also insufficient, not because post-collection review has no value, but because it is a symptom-catcher positioned where cause-prevention should be. It catches errors that have already propagated across the dataset. It cannot retroactively fix the task design that generated them.
There are structural reasons why this pattern persists. High-throughput crowd work operates under volume and speed incentives that compress investment in QA design. A vendor processing large datasets quickly has limited economic incentive to slow the collection workflow for in-process validation checkpoints. The default is to let the collection run at full volume and apply review at the end. This approach produces a reportable metric. It does not produce a quality system.
The accuracy rate is the most visible symptom of this problem. A single percentage figure tells a client what proportion of outputs passed the review filter. It does not tell them where failures originated, which contributor cohorts generated them, whether the task design was the underlying cause or how the error rate varies across subsets of the data that may be critical to the model's performance in production. For enterprises building models for regulated applications, this level of reporting is not an information gap. It is a risk management gap.
There is also a distinction that most vendor conversations treat as irrelevant but should be central: the difference between QA for off-the-shelf datasets and QA for custom data collection. When a client purchases a pre-existing dataset, they inherit the QA history of that dataset. Whatever process governed its original collection is fixed. The client cannot change it, often cannot fully audit it and must accept whatever structural decisions were made at the time. Custom data collection, done with genuine design investment, allows QA to be built around the client's specific domain, use case, risk tolerance and compliance requirements from the start. These are not equivalent vendor relationships and evaluating them as if they are producing exactly the kind of misaligned procurement decisions that show up later as production failures.
What Real Quality Assurance in Crowd Systems Actually Looks Like
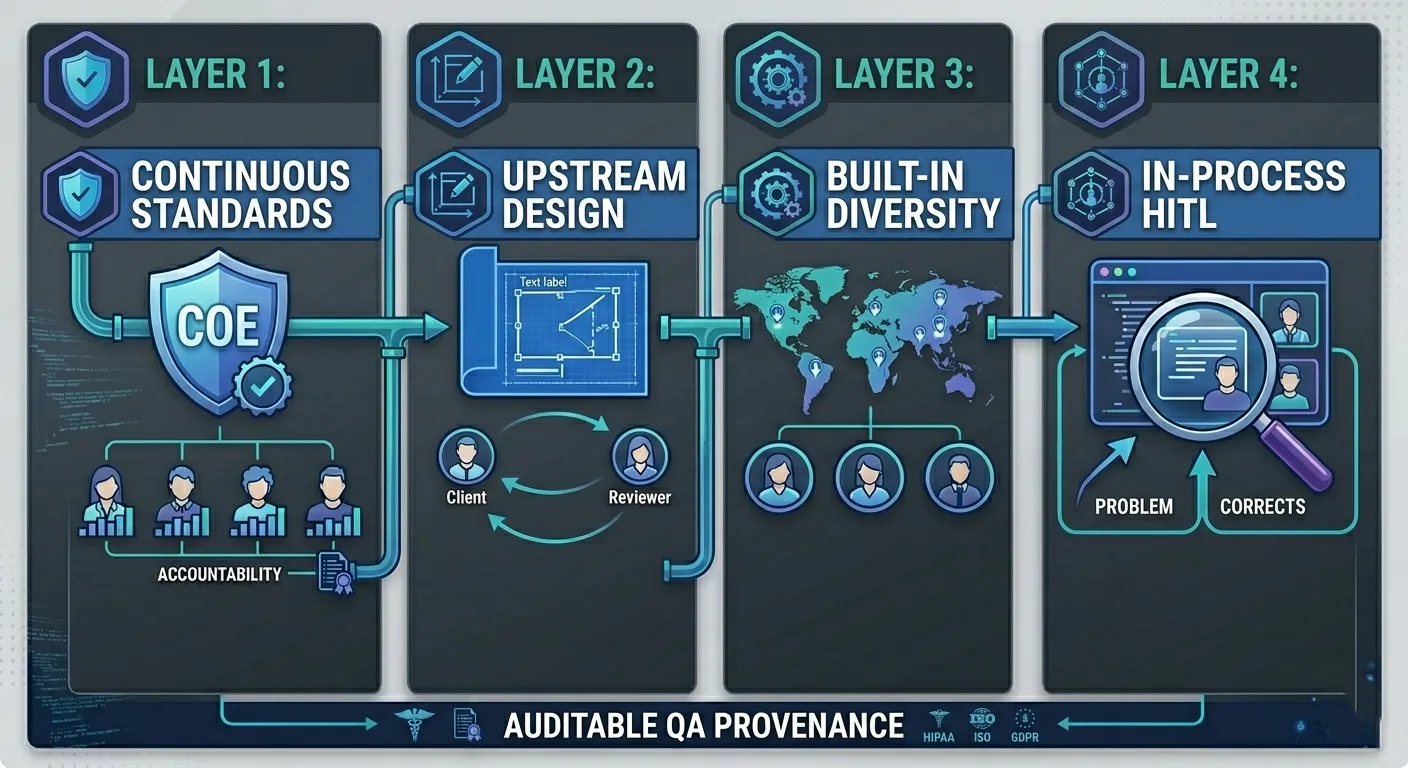
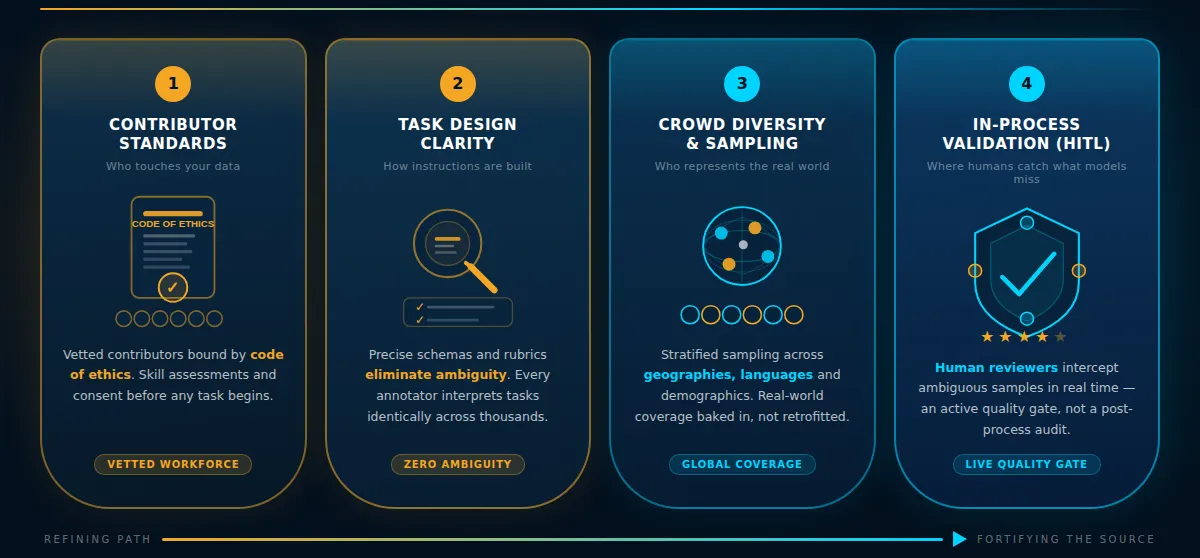
Real QA in crowd-sourced data collection does not happen at one stage. It operates across four distinct layers, each targeting a different origin point of data quality failure. Each layer prevents a specific class of problem. No downstream layer can fully compensate for a weak one upstream, which means the strength of a QA system is determined by its weakest layer, not its most visible one.
Layer 1: Contributor Qualification and Ongoing Standards
Screening contributors at onboarding is the minimum. What separates structural QA from performative QA at this layer is whether contributor standards are enforced continuously throughout the engagement, not just at the point of entry.
A published Crowd Code of Ethics is not a reputational document or a compliance checkbox. It is a quality mechanism that defines what acceptable contribution looks like, establishes accountability when standards fall short and signals to contributors that their work is subject to ongoing evaluation rather than one-time screening. Vendors without this layer are relying entirely on onboarding filters, and onboarding filters degrade in effectiveness as contributor pools scale and task complexity increases. What was screened for at entry does not guarantee consistent performance across extended, high-volume collection workflows.
Layer 2: Task Design as Upstream Quality Assurance
This is the layer most vendor QA conversations never reach, and it is the one most responsible for the category of failure described in the opening scenario. Ambiguous task instructions generate inconsistent data regardless of how thorough the downstream review is. When annotators can interpret the same task in legitimately different ways, each individual annotation can be defensible while the dataset as a whole carries structural inconsistency that review cannot correct, because review evaluates individual outputs against the instructions, not the instructions themselves.
Task design is upstream QA. It requires genuine collaboration with the client, a review process for ambiguity before collection begins, and the willingness to iterate based on early sample review before full-volume collection proceeds. A vendor applying fixed task templates uniformly across different domains and use cases is passing the cost of that design shortcut downstream to the client's model.
Layer 3: Crowd Diversity as a Built-In Quality Control Mechanism
Contributor diversity is not an ethical consideration that runs parallel to QA. It is a direct quality mechanism, and treating it as separate from QA produces data gaps that surface only in production. A homogeneous contributor pool generates data that reflects a narrow slice of human variation. The gaps this creates are not visible in accuracy rates. They emerge when the model encounters the demographic, linguistic, or cultural cohort that was underrepresented in training data and produces outputs that fail in ways the evaluation dataset did not predict.
For speech models, homogeneous contributor pools create accent and prosody blind spots that degrade recognition performance for specific speaker communities. For NLP models, they create idiomatic and register gaps that affect semantic accuracy across different text registers and cultural contexts. For computer vision models, they create representation failures in edge detection and classification that only appear when the model is deployed into environments that differ from the training distribution. Diversity built into the collection methodology prevents these gaps at the source. Diversity added as a reporting metric after collection cannot repair them. This dynamic is especially pronounced in multilingual data collection, where low-resource language communities require contributor pools with genuine linguistic depth across dialects, registers, and demographic variation, not volume throughput applied uniformly across all language categories.
Layer 4: Human-in-the-Loop Validation During Collection
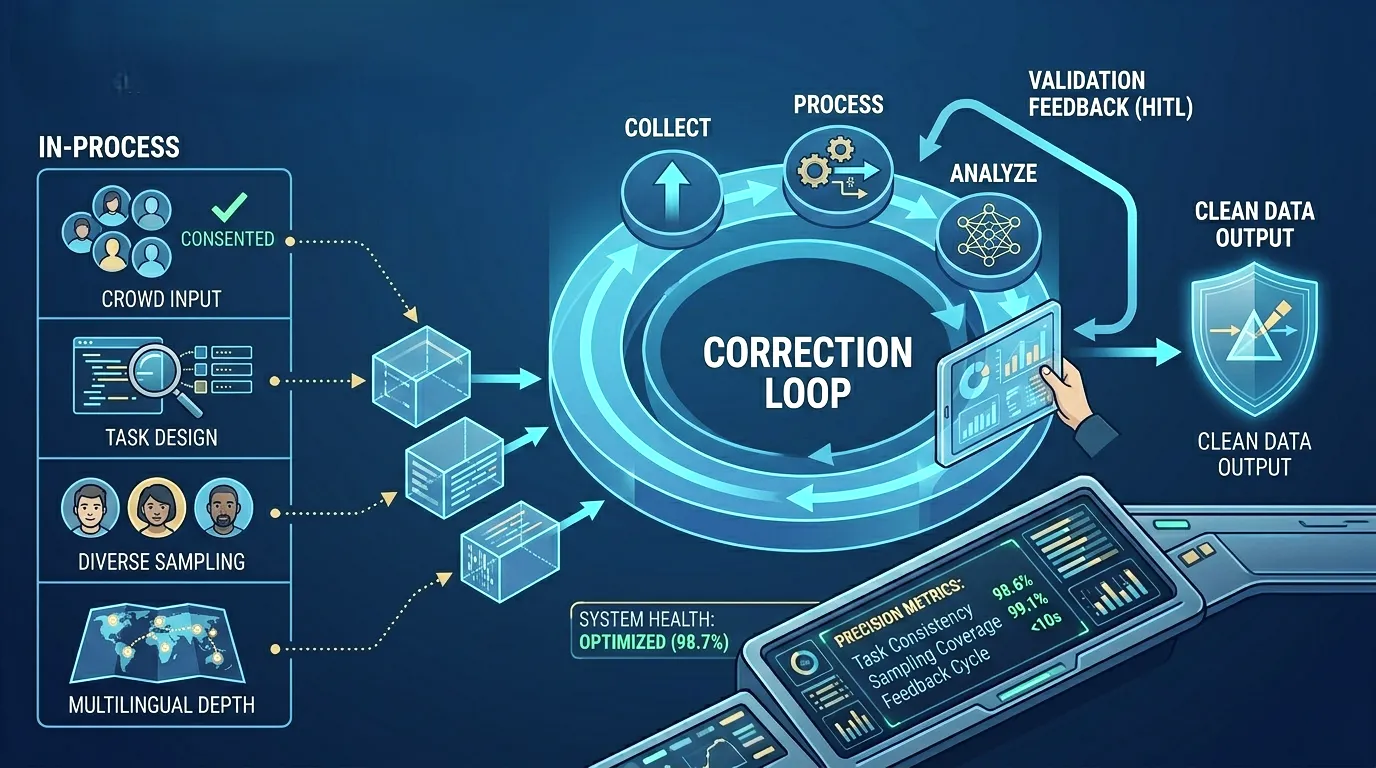
Human-in-the-Loop (HITL) validation embedded during collection catches problems while correction is still possible at a reasonable cost. Post-collection HITL is better than no HITL, but it is still a review layer operating after the fact. When structural issues are identified at the post-collection stage, the remediation options are limited: re-collect, rework at scale, or accept known quality limitations and manage them at the model level.
In-process HITL checkpoints, where human reviewers validate samples mid-collection and surface task or contributor issues in real time, allow the workflow to self-correct before errors propagate across the full dataset. The difference in remediation cost between catching a task design problem at sample 200 versus sample 20,000 is not incremental. It is categorical, and the enterprises most exposed to this cost difference are those in regulated industries where re-collection requires not just time and budget but compliance review of the new collection process.
The Downstream Cost: How Weak QA Layers Produce Specific Model Failures
Understanding the four layers matters because each one, when absent or compromised, produces a specific class of model failure. These failures carry a particular cost beyond model degradation: they are almost always diagnosed as model problems before they are traced to data origin, which means teams invest in the wrong interventions across multiple iteration cycles before the root cause is identified.
Weak contributor qualification generates label noise. Label noise degrades classifier confidence in edge cases, which are precisely the inputs that matter most in regulated applications. A healthcare model that performs well on common cases but produces unreliable outputs on edge-case clinical scenarios has a label noise problem, not necessarily an architecture problem. Weak task design generates structural annotation inconsistency that produces models which perform well on evaluation sets but fail on real-world input variation, because the evaluation set was generated by the same inconsistent process as the training data and mirrors its structural patterns. Weak crowd diversity generates representation gaps that produce biased model behavior appearing only when the model encounters underrepresented cohorts in production, at which point the training data composition that caused it is often no longer accessible for audit.
Weak in-process HITL validation generates late detection, which multiplies remediation cost. For enterprises in regulated industries, the cost of discovering data quality issues at model evaluation is not just measured in retraining cycles. It is measured in compliance review timelines, procurement cycle resets, and in healthcare or financial services contexts, the regulatory exposure of deploying a model trained on data whose quality provenance cannot be fully documented. The misdiagnosis problem is real: model teams iterate on architecture and training configuration to fix what is fundamentally a data quality issue, and the average time between initial deployment and root cause identification in this pattern is long enough to make the original collection investment largely unrecoverable.
If you are currently scoping a custom data collection engagement and want to understand how QA can be designed around your specific domain and compliance requirements, the FutureBeeAI team can walk you through their approach in detail.
Custom vs. Off-the-Shelf: Why QA Evaluation Is Not One-Size-Fits-All
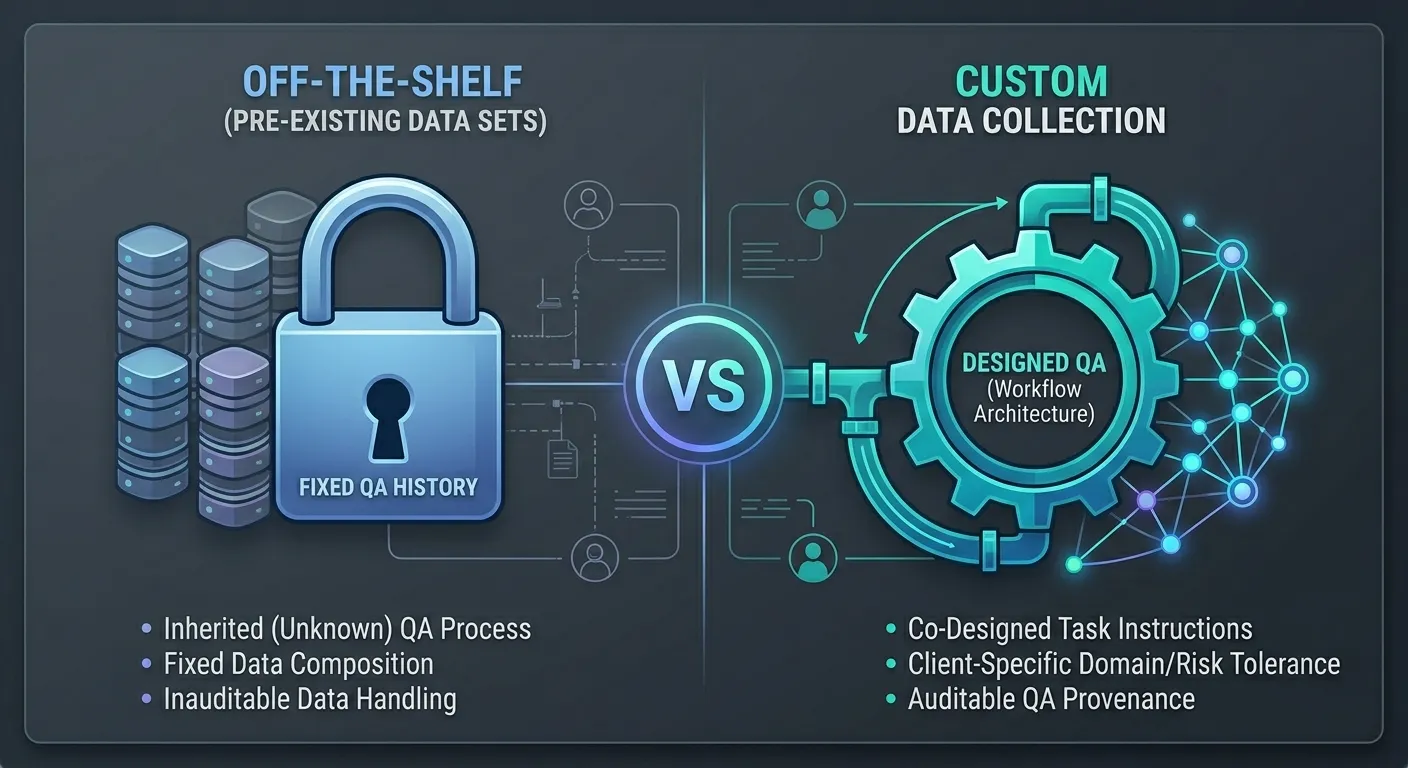
Most vendor QA conversations treat all datasets as equivalent objects subject to the same evaluation criteria. They are not. Off-the-shelf datasets come with fixed QA history. The client inherits whatever collection process governed the original data, often without full visibility into what that process was, which task design decisions were made, which contributor cohorts were used, and what the in-process validation looked like. For general-purpose applications this may be acceptable. For domain-specific or regulated applications, inheriting unknown QA history is a documented risk that most procurement processes do not adequately account for.
Custom data collection, when designed with genuine investment, inverts this risk profile. QA is not inherited but designed, and designed specifically around the client's domain requirements, acceptable error rate, compliance obligations, and downstream model use case. Task instructions are developed collaboratively. Contributor selection is calibrated to the domain. HITL checkpoints are positioned where the specific application's failure classes are most likely to originate. Compliance requirements are embedded from the start rather than retrofitted after collection. The result is not just better data. It is data with auditable QA provenance that a client can document to a regulator, a legal team, or an internal model governance process.
Compliance frameworks are a direct part of this QA infrastructure, not supplementary credentials. A vendor operating under HIPAA compliance has a documented, auditable process for healthcare data handling that reduces quality risk in regulated pipelines, not because the certification itself guarantees data quality but because the processes required to achieve and maintain that certification create structural constraints on how data is handled throughout collection. ISO, GDPR, HIPAA, and DPDPA compliance represent different but overlapping sets of process requirements, each of which, when genuinely implemented rather than nominally claimed, reduces the categories of quality risk most relevant to enterprise AI pipelines in regulated sectors.
There is also a dimension of QA that most vendor conversations skip because it sounds like an ethical rather than a quality argument: the sourcing methodology itself. Contributor-consented data collection, where contributors understand the purpose of their contribution and operate within a documented accountability framework, produces more intentional and consistent outputs than data sourced through passive collection or scraped from existing content. A contributor who understands what the data will be used for, who operates under a Crowd Code of Ethics with enforcement mechanisms, and whose performance is tracked continuously across the engagement is structurally more likely to produce consistent, high-quality outputs than an anonymous crowdworker with no accountability framework and no understanding of downstream use. Ethical sourcing is a quality argument. The industry's tendency to frame it only as an ethical one obscures a genuine and measurable quality advantage.
Red Flags and Green Flags: How to Evaluate a Vendor's QA in Practice
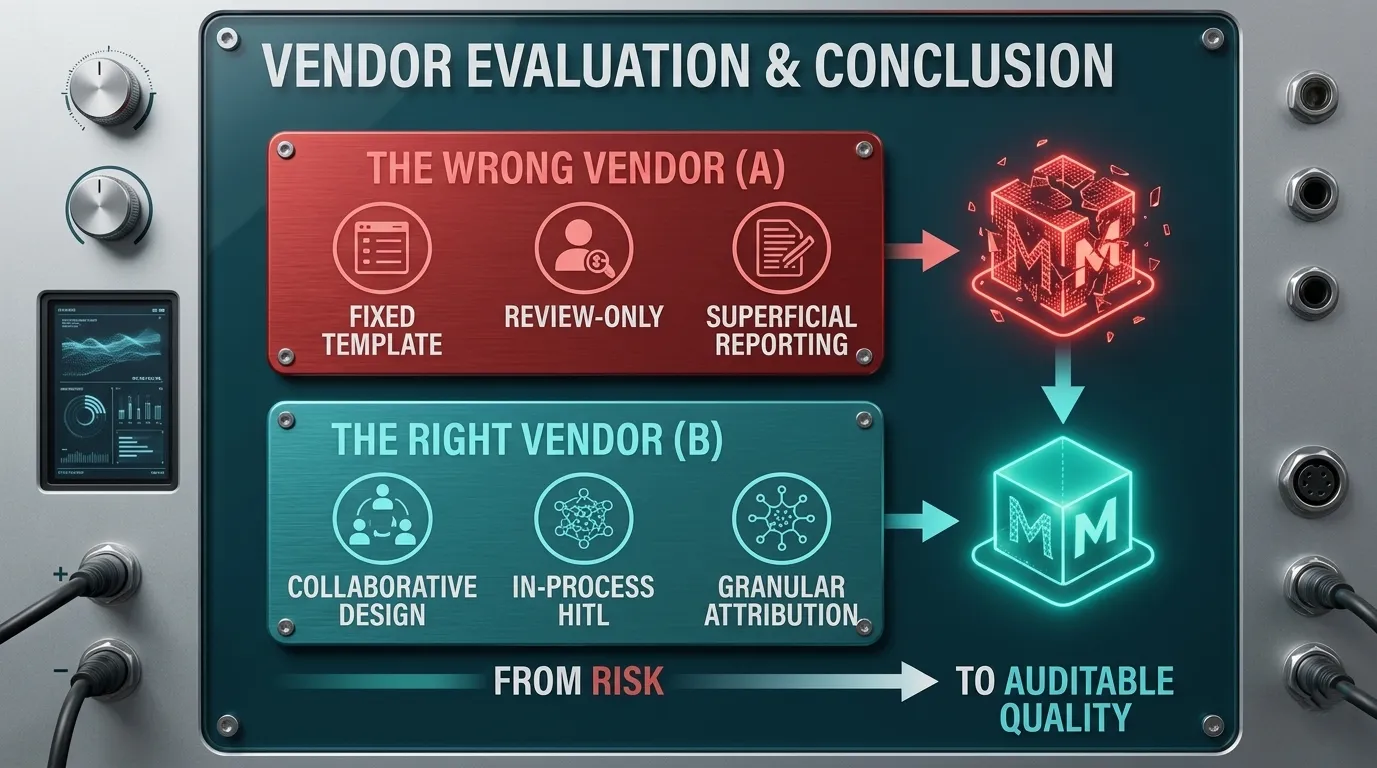
The evaluation questions that separate structural QA from performative QA are rarely asked in vendor conversations because most procurement processes are built around capability checklists rather than process architecture. The following paired flags apply specifically to custom crowd data collection for domain-specific or regulated use cases.
Contributor Standards
✅ Green: Vendor has a published Crowd Code of Ethics with ongoing enforcement mechanisms and contributor-level performance tracking throughout the engagement.
❌ Red: QA is described entirely in terms of onboarding filters, with no mention of continuous contributor monitoring or accountability mechanisms post-screening.
Task Design
✅ Green: Vendor co-designs task instructions with the client, reviews them for ambiguity before collection begins, and iterates based on early sample review before proceeding to full volume.
❌ Red: Fixed task templates are applied across all client engagements regardless of domain, industry, or use case specifics.
In-Process Validation
✅ Green: HITL checkpoints are embedded during collection, with specific descriptions of when they occur, what they are designed to catch, and how findings feed back into the active workflow.
❌ Red: When asked about validation, the vendor's default answer is that QA occurs after collection. No in-process validation is described.
Crowd Diversity
✅ Green: Contributor diversity is described in terms of how it affects data quality for the client's specific use case, including language, demographic, and domain-relevant variation.
❌ Red: Diversity is reported only as a headcount or geographic distribution figure with no connection to domain-specific quality implications or model performance.
QA Reporting
✅ Green: Vendors can attribute quality issues to their origin, including which layer, which contributor cohort, and which task design decision generated them, not only report an overall accuracy rate.
❌ Red: The only QA metric provided is a single accuracy percentage with no granular breakdown by collection phase, contributor cohort, or task type.
The Question Underneath All the Flags
Every AI data vendor will tell you they do QA. The answer to that question is not informative. The question that changes a procurement decision is not whether QA exists but where in the workflow it lives, what failure class each layer is designed to prevent, and what happens operationally when a layer catches a problem mid-collection. A vendor who can answer those questions with specificity has a QA architecture. A vendor who answers with an accuracy rate has a QA metric.
For enterprises building domain-specific models in regulated industries, this distinction is not academic. The failures that follow from weak crowd data QA are expensive not because the data is obviously bad but because it is consistently insufficient in ways that are invisible until the model is in production, at which point the gap between what was promised and what was delivered has already compounded into remediation costs that dwarf the original data investment. QA is not a feature a vendor offers. It is an architecture they either have or do not have, and the only way to evaluate it is to look past the scorecard and into the workflow.
FutureBeeAI approaches custom data collection with QA designed into the workflow from scoping through delivery. Task instructions are developed collaboratively, HITL checkpoints are calibrated to the domain's risk profile and contributor
selection draws from a globally distributed pool spanning 100+ languages with diversity built into the collection methodology.
The Crowd Code of Ethics and compliance with ISO, GDPR, HIPAA and DPDPA standards operate as structural elements of the QA system, not credentials appended after the fact.
Actively evaluating an AI data partner? Talk to the FutureBeeAI team to map the right QA architecture for your specific data pipeline and compliance requirements. futurebeeai.com/contact-us
Frequently Asked Questions
Q. What is the difference between data review and quality assurance in AI data collection?
A. Data review is a single-stage process applied after collection to identify and filter errors. Quality assurance is a multi-layer system embedded throughout the collection workflow, covering contributor standards, task design, in-process validation and post-collection review. Review catches symptoms. Quality assurance is designed to prevent causes at the layer where they originate.
Q. How does Human-in-the-Loop (HITL) improve crowd-sourced data quality?
A. HITL validation improves crowd data quality most effectively when it is embedded during collection rather than applied only after it. In-process HITL checkpoints allow reviewers to identify task design issues or contributor performance problems while the collection is active, enabling real-time corrections before errors propagate across the full dataset. Post-collection HITL can identify problems but cannot prevent the compounding that occurs when issues are caught late.
Q. What should I ask an AI data vendor about their QA process for custom data collection?
A. Ask where in the workflow each QA layer operates, not just whether QA is performed. Specifically: whether task instructions are co-designed with clients or applied from fixed templates, whether HITL validation occurs during or only after collection, how contributor performance is monitored continuously, and whether QA reporting includes granular attribution by collection phase and contributor cohort or only an overall accuracy rate.
Q. Why does crowd contributor diversity affect AI model quality?
A. Contributor diversity directly affects what variation is represented in training data. A homogeneous contributor pool produces data that reflects a narrow range of linguistic, demographic, and cultural variation. Gaps in this representation do not appear in accuracy rates during evaluation but surface in production when the model encounters inputs from communities that were underrepresented in training. For multilingual models and domain-specific applications, these gaps have direct downstream consequences on model reliability.
Q. How does ethical data sourcing connect to AI training data quality?
A. Contributor-consented data collection produces more intentional and consistent outputs than passively sourced or scraped data. Contributors who understand the purpose of their contribution and operate within a documented accountability framework are structurally more likely to produce consistent, high-quality outputs. Ethical sourcing creates an accountability structure that functions as a quality mechanism throughout the collection process, not only as a compliance or reputational consideration.






