Introduction
AI systems today make decisions that matter. They help doctors document patient visits, assist banks in reviewing customer interactions and support vehicles in understanding their surroundings. Yet when something goes wrong, the same question keeps surfacing across industries: Where did this behavior come from?
Too often, teams discover that they can’t answer it clearly. Not because the model is mysterious, but because the data behind it is. The training dataset passed through multiple hands, tools, and transformations. Consent details live in one place, annotations in another and dataset versions are poorly documented. When auditors, legal teams, or regulators ask for proof, all anyone can offer are assumptions.
This is where AI traceability stops being a theoretical idea and becomes a practical necessity. Traceability is not about opening up model internals or publishing algorithms. It is about being able to follow a dataset’s journey end to end and defend every step along the way. In regulated, multilingual, real-world AI systems, that ability is often the difference between trust and risk.
Why AI Feels Like a Black Box Today
When people talk about AI being a “black box,” they often point to complex models or opaque decision-making. In practice, the bigger problem usually appears much earlier. It starts when someone asks a simple operational question, and no one can answer it confidently.
Imagine a compliance review where a legal team asks which audio samples were used to train a clinical speech model, who contributed them, and under what consent. The engineering team knows the model performs well. The dataset team knows the data was collected ethically. But the exact linkage between contributors, annotations, dataset versions, and the final model snapshot is scattered across systems.
That gap creates the black box feeling. Not because the technology is unknowable, but because the data lineage is fragmented. Without traceability, teams cannot reconstruct how a dataset was built, modified, and reused over time. Governance breaks down not at the model layer, but at the data layer, where visibility quietly disappeared.
Traceability enters the picture as the missing connective tissue. It restores continuity between data collection, processing, and use, making AI systems explainable in operational terms, even before anyone inspects a model.
What Traceability Really Means in AI Data Pipelines
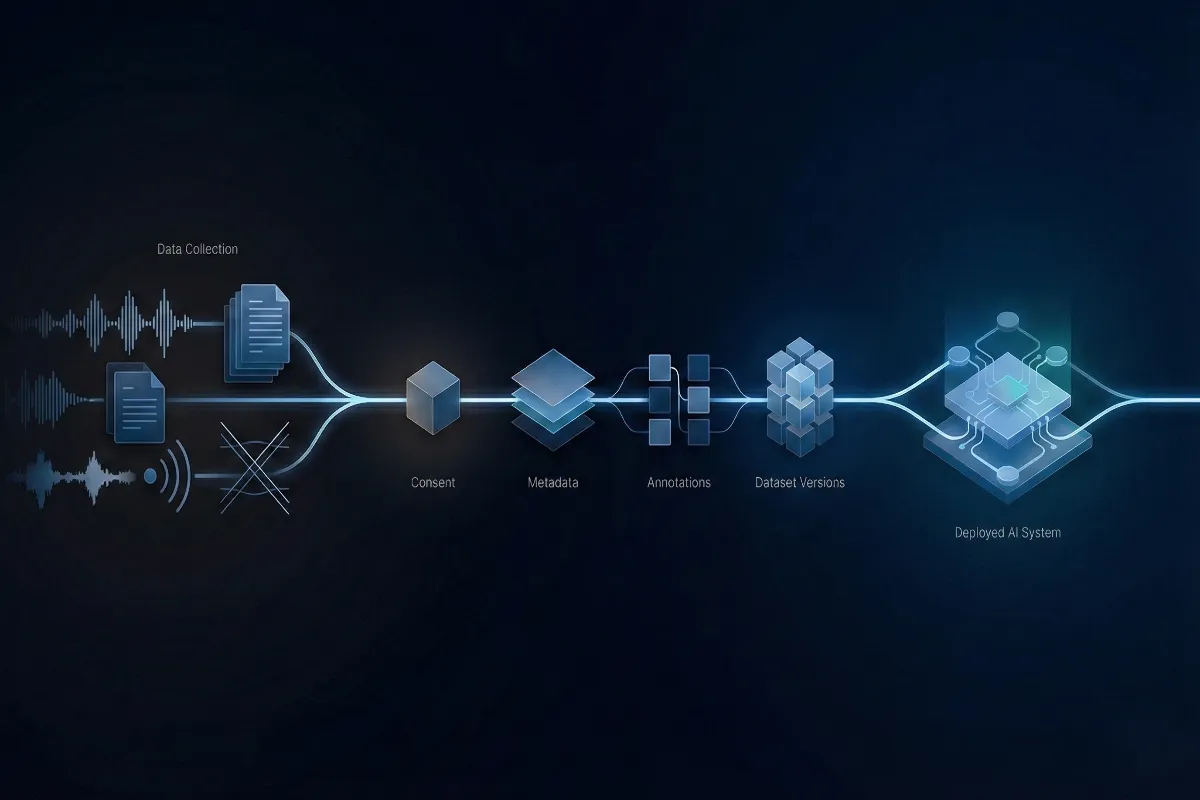
At its simplest, traceability means being able to answer one question clearly: How did this data get here? In AI pipelines, that question spans far more than raw files. It includes who contributed the data, how it was collected, how it was labeled, what transformations were applied, and which version ultimately fed into a model.
AI traceability is therefore best understood at the dataset level. It is the end-to-end visibility that allows teams to reconstruct how data was sourced, processed, annotated, and versioned over time. This visibility matters because models are not static artifacts. They are trained, retrained, evaluated, and audited repeatedly. Without a reliable data chain-of-custody, even accurate models become hard to defend.
Importantly, traceability is not about collecting everything indiscriminately. It is about capturing the right artifacts at the right moments, so that when questions arise, teams have evidence rather than assumptions.
Traceability vs Transparency vs Explainability
 These terms are often used interchangeably, but they serve different purposes. Transparency is about openness, often at a high level, such as documenting system behavior or intended use. Explainability focuses on interpreting how a model arrives at a specific output. To explore more about transparency check out our blog on transparency.
These terms are often used interchangeably, but they serve different purposes. Transparency is about openness, often at a high level, such as documenting system behavior or intended use. Explainability focuses on interpreting how a model arrives at a specific output. To explore more about transparency check out our blog on transparency.
Traceability sits underneath both. It ensures that the data feeding the model is well-documented and auditable. Without traceability, explainability answers only part of the story. You might understand how a model made a decision, but not why that data was there in the first place. For governance and compliance, that distinction matters.
The Core Building Blocks of Data Traceability

Traceability becomes tangible when broken into concrete components. Rather than a checklist, it is better thought of as a chain. Each link supports the next, and when one is missing, the entire structure weakens.
Data Provenance and Consent
Provenance answers the question of origin. It captures where data came from, who contributed it, and under what conditions. Consent is inseparable from this layer. For ethical AI systems, consent is captured per contributor and scoped to specific tasks or datasets. This ensures that data is used only in ways contributors agreed to, and that reuse boundaries are respected.
In practice, provenance and consent records allow teams to show that datasets were collected lawfully and responsibly, without exposing contributor identities unnecessarily. This approach aligns closely with strong internal governance practices and published policies and compliance frameworks.
Metadata and Context
Raw data alone rarely tells the full story. Context matters. Metadata such as language, dialect, device type, and environment category help teams understand coverage, bias, and limitations.
For multilingual datasets, especially, metadata is what allows teams to assess whether certain accents, regions, or usage contexts are underrepresented. It also plays a critical role during audits, where fairness and representativeness are often scrutinized alongside performance.
Annotation Lineage and Dataset Versioning
Annotations are not static truths. Guidelines evolve, edge cases are clarified, and quality controls improve over time. Annotation lineage tracks how labels were produced, reviewed, and updated, along with the guidelines used at each stage.
Dataset versioning ties everything together. By creating immutable dataset snapshots, teams can reproduce results, roll back changes, and clearly map which dataset version trained which model. This linkage is foundational for model auditability and long-term governance.
What Breaks When Traceability Is Missing
When traceability is weak, failures rarely appear dramatic at first. They show up as friction, delays, and uncertainty.
In healthcare contexts, misaligned annotations or unclear consent scopes can raise red flags during clinical reviews, even if the model performs well. In BFSI environments, the inability to prove lawful data use can stall audits or force costly revalidation. In automotive settings, investigation teams may struggle to determine which data informed a specific system behavior, complicating accountability.
Across these scenarios, the common thread is not poor modeling, but missing documentation and lineage. Without traceability, teams cannot isolate issues, demonstrate due diligence, or respond confidently when scrutiny arises.
Why Governance and Compliance Depend on Traceability
Regulatory frameworks increasingly emphasize accountability over performance alone. Laws and guidelines such as GDPR, HIPAA and the EU AI Act all point toward the same expectation: organizations must understand and document how personal or sensitive data is used.
Traceability supports compliance efforts by making that documentation operational. Instead of retroactively assembling evidence, teams can rely on built-in records that show data lineage, consent scope, and dataset usage. This approach reduces risk not by guaranteeing compliance, but by enabling defensible processes.
In governance discussions, traceability often becomes the practical bridge between ethical intent and real-world enforcement. It allows organizations to demonstrate that responsible AI principles are not just policies, but practices embedded in their data pipelines.
How Traceability Plays Out Across High-Risk Industries
 Traceability takes on different nuances depending on the domain, but its value becomes most apparent in high-risk environments.
Traceability takes on different nuances depending on the domain, but its value becomes most apparent in high-risk environments.
These requirements are not theoretical, they surface repeatedly in real-world deployments, where traceability determines whether systems can be audited, defended, and scaled responsibly, as seen across multiple case studies.
In healthcare, clinical speech datasets demand careful consent handling and high annotation quality. Traceability ensures that each recording can be linked back to its collection context and labeling process, supporting patient safety and regulatory reviews within healthcare AI systems.
In BFSI, customer support and call analysis datasets often intersect with KYC and privacy obligations. Here, traceability enables teams to show how data was sourced and restricted, supporting audit readiness in BFSI-focused AI deployments without overexposing sensitive information.
In automotive applications, in-car data introduces questions of environment, device context, and liability. Traceability helps map training data back to specific conditions, supporting investigations and continuous improvement in automotive AI systems.
Across all three, multilingual dataset traceability adds another layer of complexity, as consent language, regional norms, and data expectations vary widely. Clear lineage becomes essential.
How FutureBeeAI Implements Traceability in Practice

At FutureBeeAI, traceability is treated as an operational system rather than a documentation afterthought. Through our workflows, traceability is built into how datasets are created and managed.
Contributor onboarding captures demographic and contextual metadata upfront, alongside consent scoped to specific tasks or datasets. Annotation processes are guided by documented guidelines, with quality checks recorded as part of the workflow. Dataset versions are created as immutable snapshots, allowing teams to track changes and reproduce results.
TheYugo AI data platform supports these processes by connecting consent logs, metadata capture, annotation tracking, and secure delivery into a coherent system. The emphasis is not on showcasing a platform, but on ensuring that every dataset can be explained, evaluated, and defended when needed.
Traceability Is Not Paperwork. It’s the Backbone of Trustworthy AI
It is tempting to see traceability as overhead, something added to satisfy auditors or regulators. In reality, it is an enabler. Traceability makes AI systems easier to debug, safer to deploy, and more resilient over time.
By focusing on dataset-level responsibility, organizations gain clarity into their AI pipelines long before issues arise. They can evaluate vendors more effectively, design stronger governance processes, and build trust with stakeholders who increasingly demand evidence, not assurances.
In the end, trustworthy AI does not emerge from better explanations alone. It starts with data that can be traced, understood, and defended. When that foundation is in place, the black box begins to open, not through theory, but through practice.
If you’re evaluating AI datasets or building systems that need to stand up to real scrutiny, traceability shouldn’t be an afterthought. It’s something to ask about early, examine closely and design from the start. And if you’re looking for datasets where consent, metadata, and lineage are treated as first-class requirements rather than paperwork, then contact FutureBeeAI for working closely with teams to make that level of traceability practical.