Computer vision
Image segmentation
Image Segmentation: A Key Technique in Computer Vision
What is image segmentation? Different types of image segmentation and their use cases.
Computer vision
Image segmentation
What is image segmentation? Different types of image segmentation and their use cases.

When attempting to cross a road, what do you do first? Usually, we scan the road to our left and right, consider the other vehicles, and then decide. In just a few milliseconds, our brain can determine what kind of vehicle—a bike, car, bus, truck, auto, etc.—is approaching us. Can a machine accomplish that?
A few years ago, the answer was "no,” but advancements in computer vision technology have made it possible for machines to detect objects, identify people, determine their shape, and so on.
Computer vision is a field of study that focuses on how computers can be made to interpret and understand visual data from the world, such as images and videos. Computer vision has made it possible for us to develop self-driving cars, facial recognition models, and so on.
Now there are many ways to deal with computer vision models like I said detection of objects in any given image, but what if drawing a bounding box is not enough or if you want to see buildings, or the sky, or the road; you don't want bounding boxes for that. Drawing a bounding box in object detection is not enough for many use cases like self-driving cars. A self-driving car should detect vehicles, roads, people, animals, traffic signals, vehicle direction, shapes, boundaries that separate trees and buildings from roads, etc. All these cannot be done with object detection or image recognition, and to get all these details, we must first analyze each and every class and pixel on the given image.
So, here comes one of the most effective processes: image segmentation, which allows us to understand any given image at a granular level, can separate boundaries and shapes, and can give us the overall context.
Let’s take a deep dive into the image segmentation process and its types.
Image segmentation is a computer vision process that divides a digital image into multiple segments, or subgroups, also known as a set of pixels, where each pixel in the given image is considered an object.
A digital image is made up of millions of pixels, and with the help of image segmentation, we can assign each pixel to the object to which it belongs or we can group together the pixels that have the same attributes.
A digital image has two main parts in image segmentation: things and stuff. In a picture, things correspond to countable items (e.g., people, flowers, birds, animals, etc.). Stuff, in contrast, is an uncountable representation of amorphous regions (or repeated patterns) of comparable substance (e.g., road, sky, and grass).
Image segmentation is very different from image recognition and object detection where we assign one or more labels to an entire image to predict the object, or location of the object in a given image. It is not a great idea to process the entire image at the same time because there may be some regions that do not contain any information for a given use case. Image segmentation gives us a more fine-grained context of a given image.
Let’s understand this with a simple example:
While the term image segmentation refers to the general technique of segmenting an image into Coherent parts, depending on your specific use case, there are a few different ways this can work in practice
Image segmentation tasks can be categorized into main three types:
Semantic segmentation can be defined as grouping the same parts or pixels of any target object in a given image or clustering parts of an image together that belong to the same object class with no other information or context taken into consideration.
Semantic segmentation does not differentiate between stuff and things; it only focuses on the given object class, or we can say that it only focuses on different classes and ignores the numbers and instances.
You can see in the below-given image, all people are assigned the same label “person” and they all have the same color.
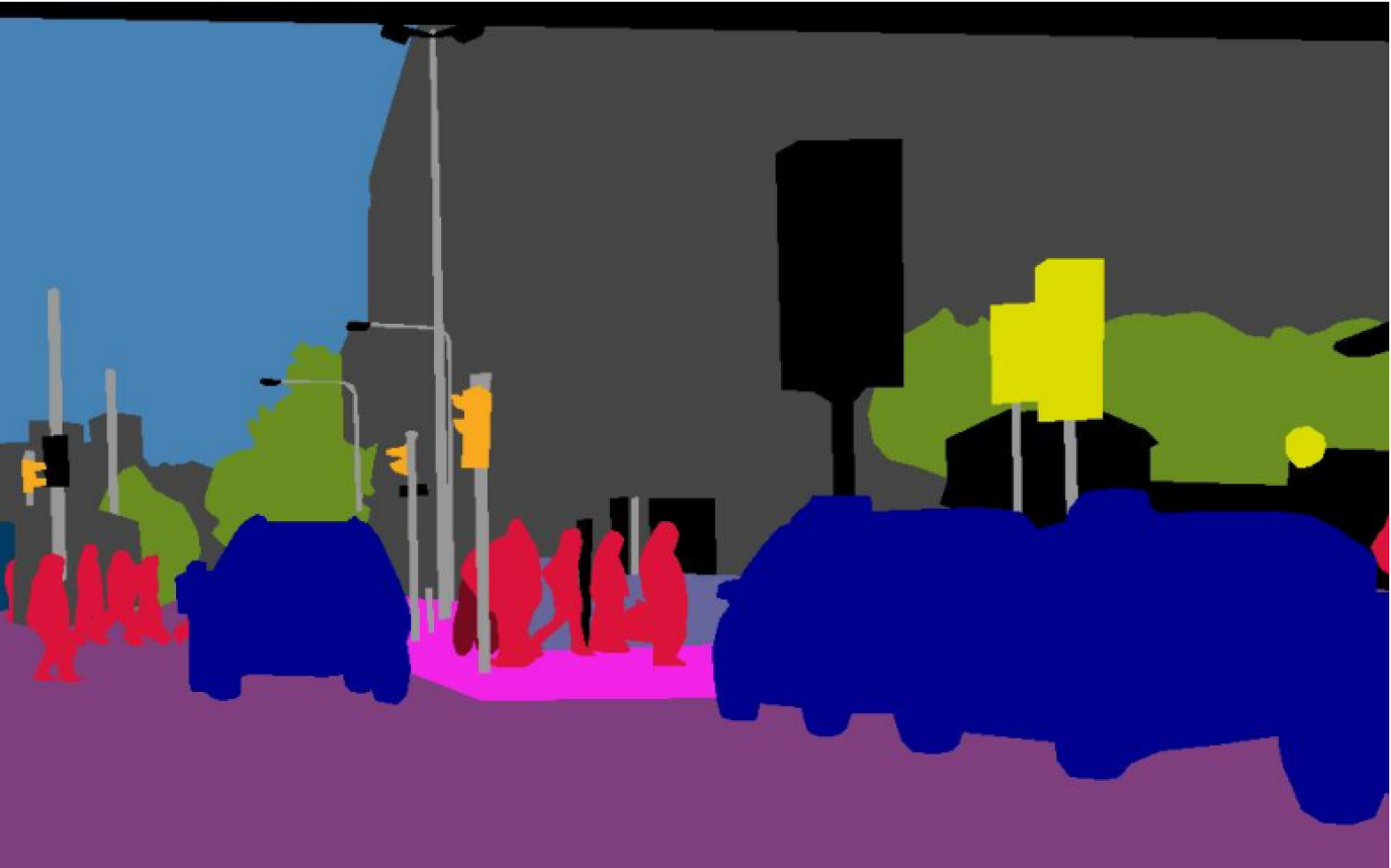 [Image Source - Ground truth Per pixel class labels]
[Image Source - Ground truth Per pixel class labels]
Semantic segmentation can also be known as "non-instance segmentation," as it gives the same pixel value to the same objects at different instances. It is primarily applied when a model needs to know for sure whether or not an image contains an object of interest and which portions of the image do not.
Instead of using classes, instance segmentation models group pixels into categories based on "instances" to segregate overlapping or similar objects based on their boundaries.
Instance segmentation only considers countable things (birds, people, cars, etc.) and does not consider other stuff (eg: sky, road, and grass) or repeated regions.
You can see in the below-given image below that all people are assigned the same label "person,” (we can also give the same label with different values person 1, and person 2) but they all have different colors, and all are separated by their boundaries.
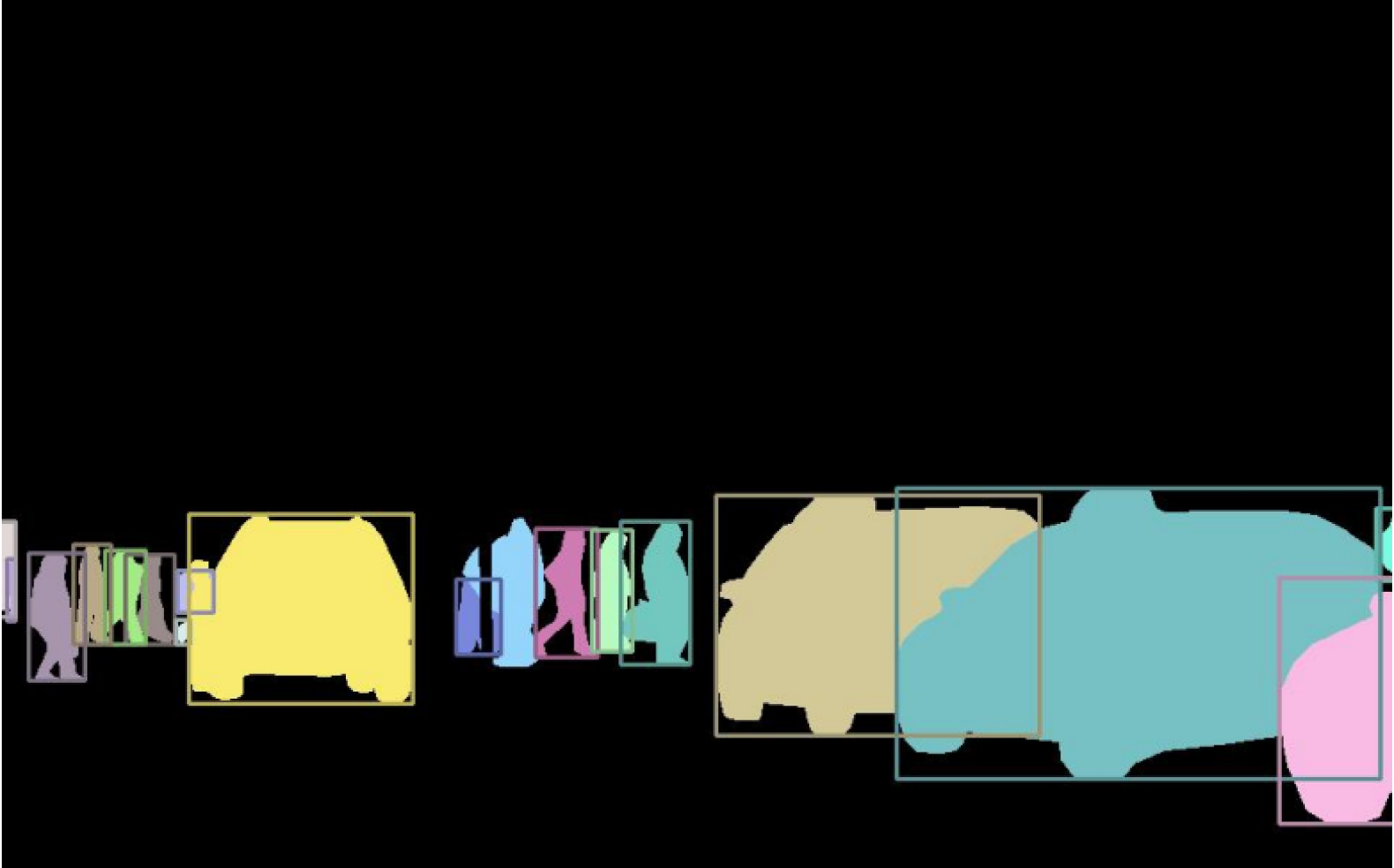 [Image Source - Instance segmentation (per-object mask and class label)]
[Image Source - Instance segmentation (per-object mask and class label)]
It is primarily applied when a model needs to work on countable things.

Panoptic segmentation is a recently developed segmentation task that is far more informative as it combines semantic segmentation (labeling pixels with the class of the item they belong to) and instance segmentation (identifying and segmenting particular object instances) into a single model. The objective is to generate a single, unified output that offers a name for each pixel in the image as well as a segmentation mask for each instance of an object. This makes it possible to comprehend an image scene more precisely and in more depth.
Panoptic segmentation considers things (people, vehicles, birds, “object instances”) the same as instance segmentation and stuff (sky, road grass, background) or repeated regions as semantic segmentation.
 [Image Source - Proposed panoptic segmentation task (per-pixel class+instance labels)]
[Image Source - Proposed panoptic segmentation task (per-pixel class+instance labels)]
Panoptic segmentation is well-suited for tasks that require a detailed understanding of an image scene, such as self-driving cars, where the ability to accurately identify and segment both individual objects and the background is crucial for safe navigation.
There are many different techniques to perform image segmentation tasks.
Let’s understand them one by one:
Threshold segmentation is the simplest method of image segmentation; it divides different pixels into two classes by comparing pixels intensity to a given threshold value. Pixels with values greater than the given threshold are set to 1, while pixels with values less than the threshold are set to 0. It is also called binarization.
 [Image Source - Digital Image Thresholding Techniques…]
[Image Source - Digital Image Thresholding Techniques…]
Threshold segmentation can also be defined as the process of separating the foreground from the background. In short, the threshold will divide a given image into two segments required and not required sections.
For example, considering image pixels ranging from 0 to 100, the threshold is 25. Then all the pixels with values less than or equal to 25 will be provided with a value of 0 (black), and all the pixels with a value greater than 25 will be provided with a value of 100 (white).
The threshold value may have a constant or dynamic value depending on the noise level in a given image. The noise level means unnecessary information and data.
Based on the threshold value, we can further classify threshold segmentation into three types:
Edge segmentation is the task of detecting edges in images, also known as "edge detection." It focuses on identifying the edges of different objects in an image.
It is a very crucial method used to locate features of associated objects in the image, as edges contain a lot of information you can use.
Edge-based segmentation can assist you in removing unwanted and unnecessary information from images. It greatly reduces the size of the image, making image analysis simpler.
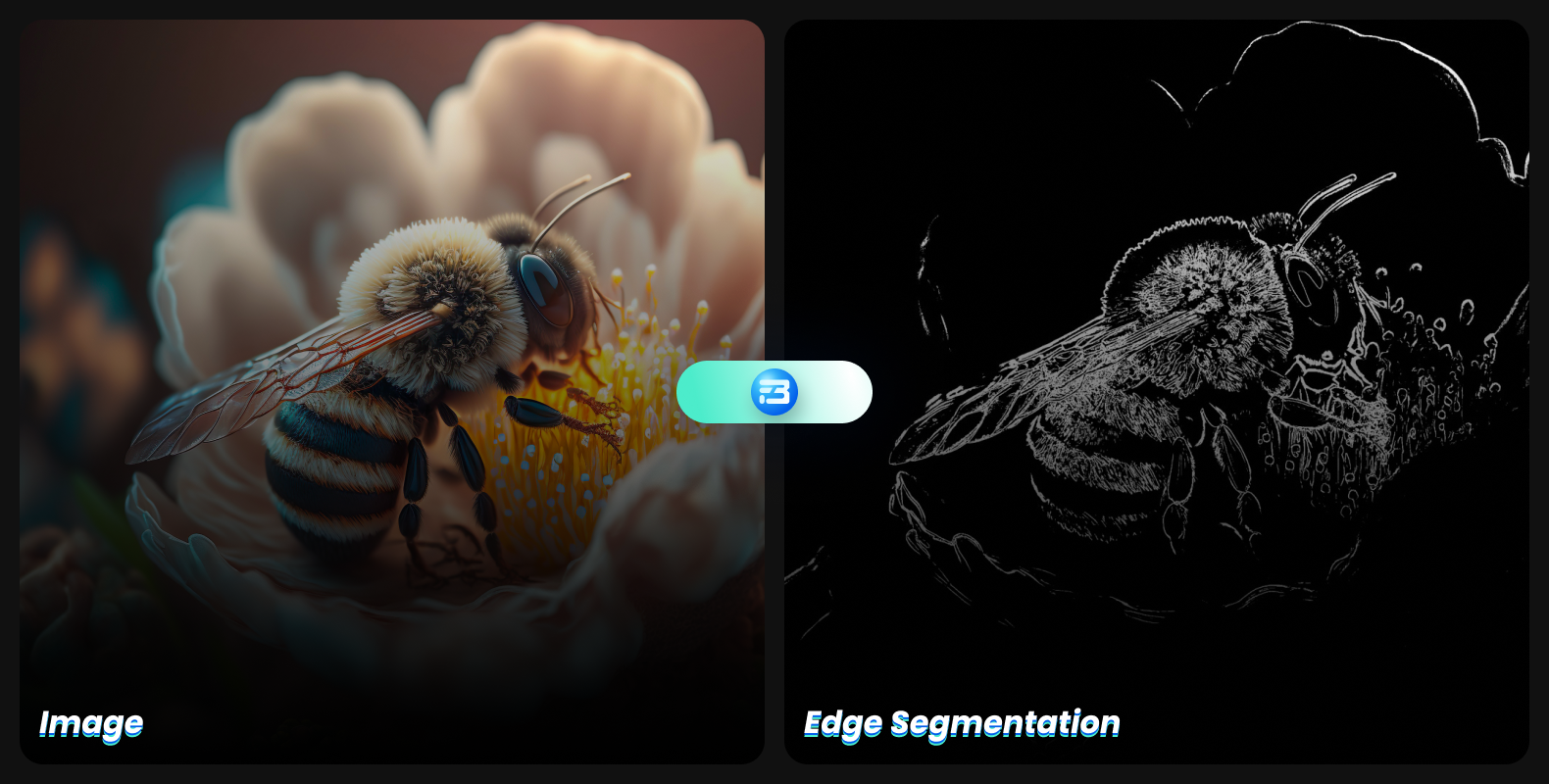 Edge-based segmentation algorithms locate edges in an image based on variations in texture, contrast, gray level, color, saturation, and other attributes. Connecting all the edges into edge chains that more closely resemble the borders of the image will increase the quality of your results.
Edge-based segmentation algorithms locate edges in an image based on variations in texture, contrast, gray level, color, saturation, and other attributes. Connecting all the edges into edge chains that more closely resemble the borders of the image will increase the quality of your results.
Edge-based segmentation can be done in many ways:
Region-based segmentation algorithms divide images into different sections by grouping adjacent pixels having similar features.
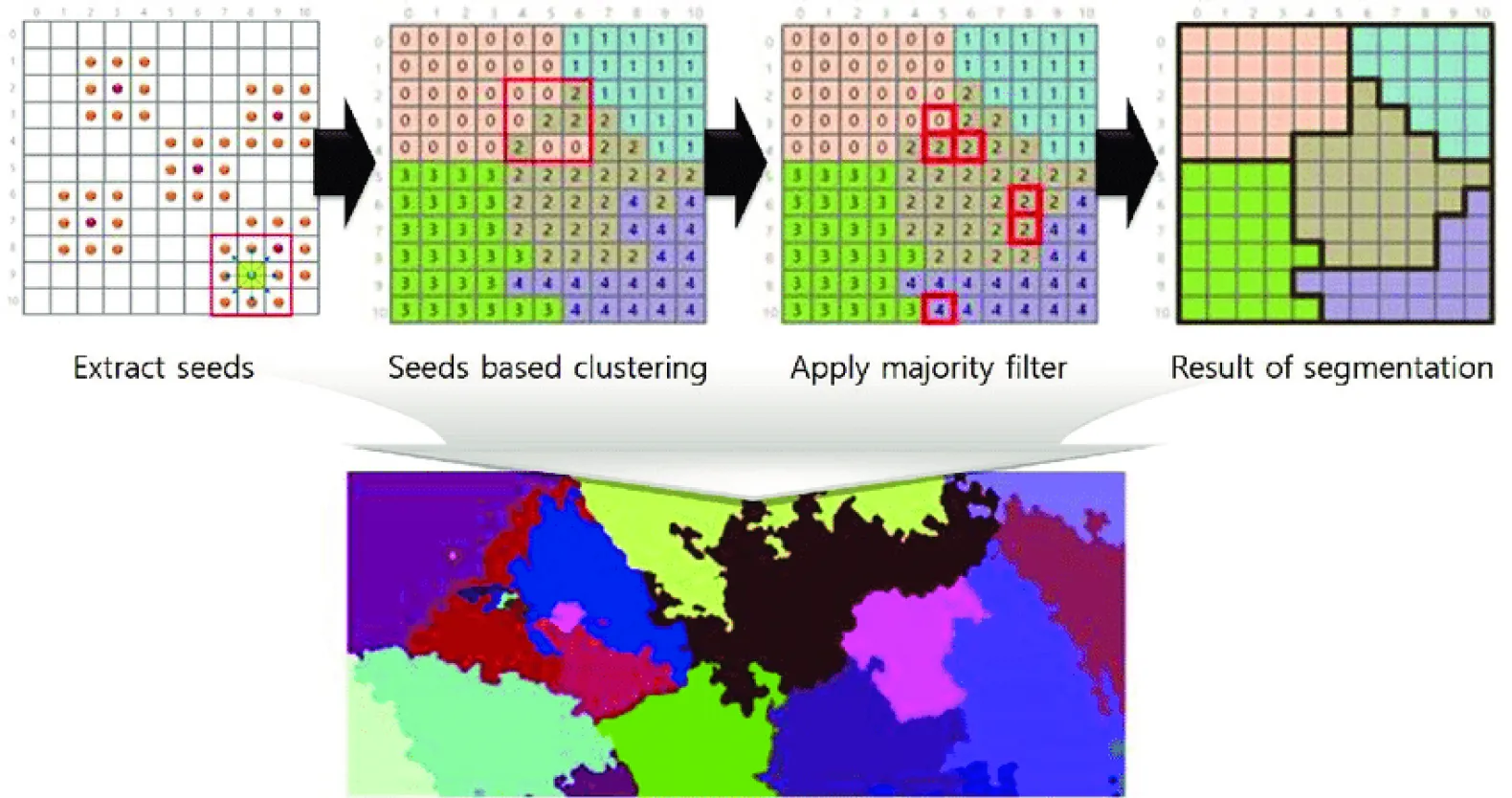 [Image Source - Result of performing the seeded region growing algorithm]
[Image Source - Result of performing the seeded region growing algorithm]
The segmentation starts with some pixels set as seed pixels which could be a small or a large section of a given image. After locating the seed points, the algorithm can expand regions by including more pixels or by contracting and combining them with other points.
Region-based segmentation can be done in two ways:
A "watershed" is a transformation on a grayscale image. Watershed segmentation methods use pixel brightness to determine elevation and treat images like topographic maps. Using this method, the regions between the watershed lines are marked by lines forming ridges and basins. Based on pixel height, it separates images into various zones, grouping pixels with the same gray value.
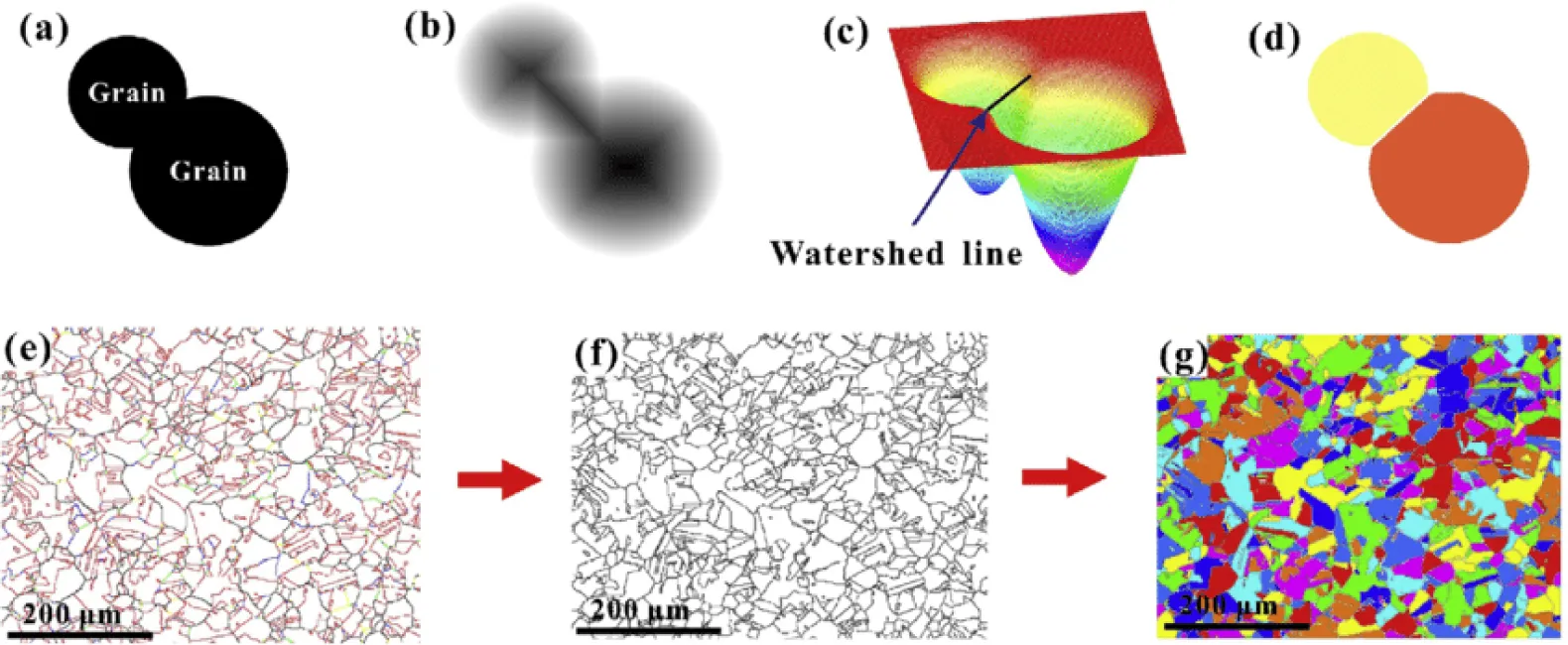 [Image Source - Schematic for watershed segmentation algorithms]
[Image Source - Schematic for watershed segmentation algorithms]
Watershed segmentation can be divided into two parts:
As the name suggests Cluster based segmentation algorithm divides images into clusters of pixels that have the same features. They are unsupervised algorithms that assist you in locating hidden visual data that may not be obvious to the naked eye.
This hidden data includes information such as clusters, structures, shadings, etc.
Clustering algorithms perform better than their counterparts and can provide reasonably good segments in a small amount of time.
Cluster-based segmentation can be divided into two parts:
Deep learning-based image segmentation involves using neural networks, particularly convolutional neural networks (CNNs) to perform the segmentation task. In this approach, the neural network is trained on a large dataset of labeled images to learn the mapping from image pixels to corresponding segmentation masks. During inference, the input image is processed by the trained network, and a segmentation mask is generated, indicating the class or object for each pixel in the image.
A neural network that performs image segmentation particularly uses an encoder-decoder CNN architecture.
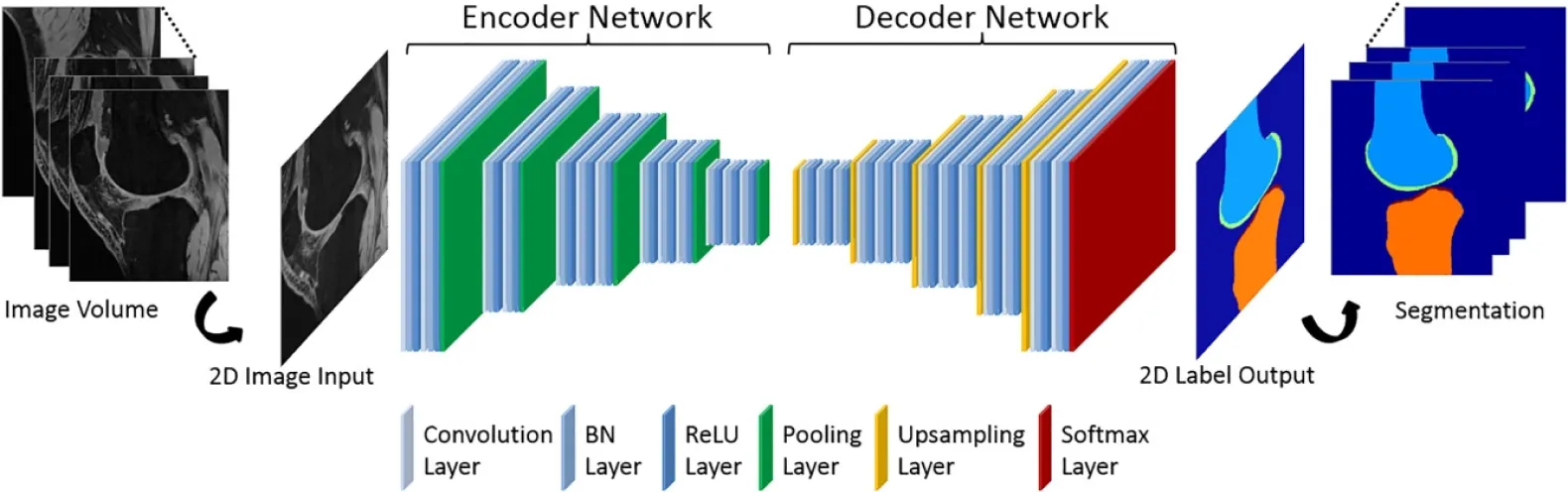 [Image Source - SegNet CNN architecture]
[Image Source - SegNet CNN architecture]
Deep learning-based Image segmentation methods are very popular because
In conclusion, deep learning-based image segmentation is a powerful and widely used technique in computer vision. It enables the automatic and accurate segmentation of images into different objects and parts, which has a wide range of applications in various fields.
In a variety of industries, image segmentation is used for a granular understanding of images.
 [Image Source - Depth-aware video panoptic segmentation]
[Image Source - Depth-aware video panoptic segmentation]
Image segmentation is especially used for self-driving cars as it performs very crucial and complex robotic tasks and needs a deep understanding of the surrounding (road, other vehicles, pedestrians, sidewalks, and other potential obstacles/safety hazards). This implies that for an autonomous vehicle, information about every pixel is critical in order to navigate it safely and efficiently.
Image segmentation can be a useful tool in the early stages of a diagnostic and therapy pipeline for many disorders that need medical pictures, such as CT or MRI scans.
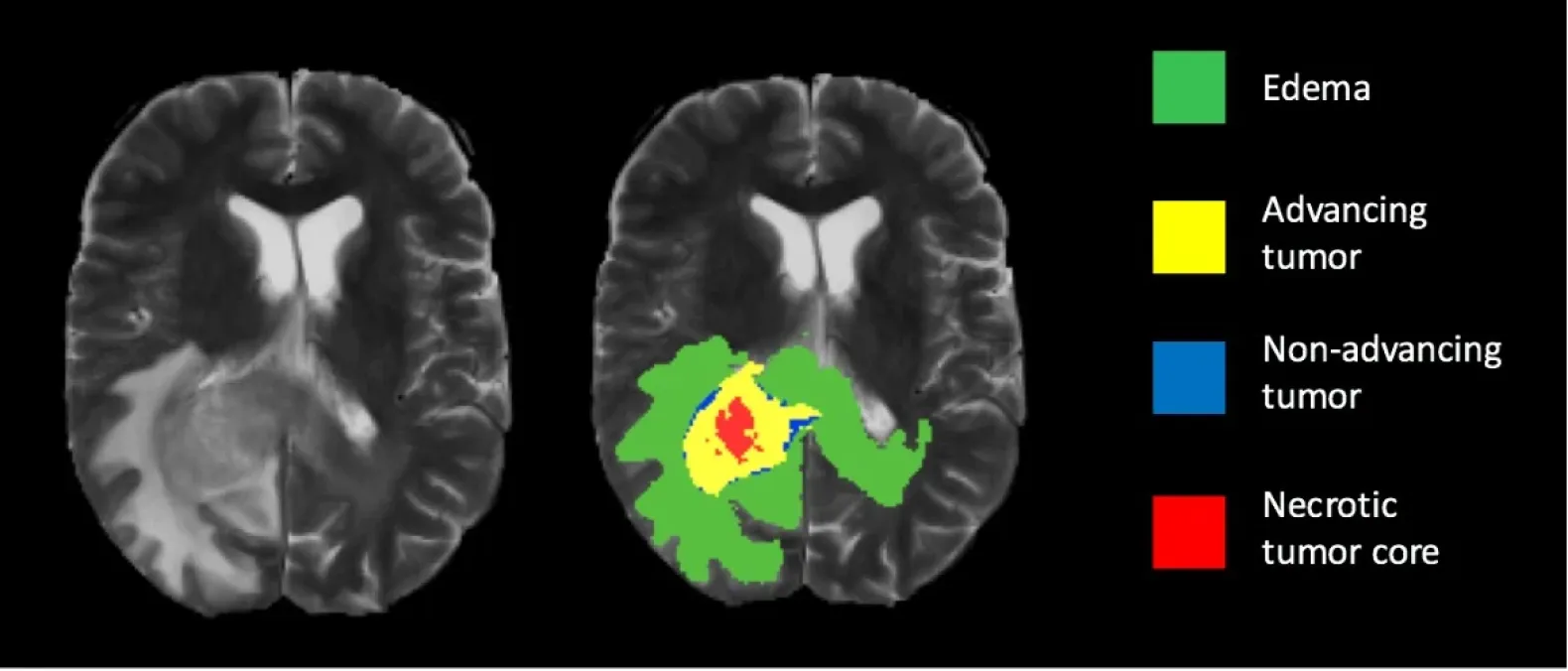 [Image Source - - Brain Tumer Segmentation]
[Image Source - - Brain Tumer Segmentation]
Medical imaging and diagnostic techniques such as X-ray, CT, MRI, and ultrasound generate images that contain a lot of information and can be difficult to interpret. Image segmentation can be used to separate or isolate specific structures or regions of interest in an image. The goal of image segmentation in medical imaging is to make the diagnostic process more efficient, accurate, and reliable, as well as to improve patient outcomes.
For many geospatial applications involving geo-sensing, such as mapping land use through satellite photography, traffic control, city planning, and road monitoring, image segmentation can be used. For numerous applications that track areas of deforestation and urbanization, knowledge of land cover is also essential. Each image pixel is often split and assigned to a particular type of land cover, such as metropolitan regions, agricultural land, aquatic bodies, etc.
Image segmentation is very popular for removing unwanted backgrounds and objects from images and is mostly used in mobile applications. This feature was recently added to Google's Pixel 7 smartphone.
 [Image Source - Background Removal]
[Image Source - Background Removal]
There are some more use cases where image segmentation is gaining popularity: facial recognition, virtual try-on, clothing categorization, and so on.
Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!





