Introduction
Car commercials make in-car voice control look effortless. A driver says, “Play my playlist,” and the system responds instantly. But anyone who has worked on speech recognition for vehicles knows the reality is very different. Inside a moving car, the audio channel is messy, unpredictable, and full of surprises that break most models.
The failures rarely come from model architecture alone. More often, the problem lies in the dataset. Clean, scripted speech corpora simply do not reflect what happens in a real vehicle. In this blog, we will explore why cars are among the hardest environments for speech recognition, why generic datasets consistently fail, and what it takes to design speech data that actually works in practice.
Two Core Challenges in the Car
Vehicle acoustics are harsh and unpredictable
Step into a moving car and you instantly hear why speech recognition struggles. On a highway, tire friction and wind roar compete directly with the driver’s voice. In city traffic, horns, sirens, and braking noises cut across commands. Even in a parked car, the hum of the engine, the push of the AC fan, or the sweep of wipers keep the cabin far from quiet.
Microphones add another layer of complexity. A phone has one mic near your mouth. A car may have several scattered across the cabin, in the dashboard, steering wheel, headliner or headrests. Each placement “hears” speech differently. A navigation request that sounds crisp to a dashboard mic may arrive muffled at the headrest mic, where it blends with road noise.
Generic datasets rarely capture this. They assume speech is dominant and noise is background. But in a car, noise often rivals speech in the same frequency band. Models trained on clean corpora perform well in the lab, then break down once exposed to real driving conditions.
Human speech in cars is messy and inconsistent
Even if we solved acoustics, the way people actually talk inside cars adds another layer of difficulty. Drivers rarely use long, scripted prompts. They give clipped commands like “AC low” or “Call home.” These short utterances are natural when focus is on the road, but they are absent in most corpora.
Multilingual drivers switch languages without pause. An Indian driver might say, “Navigate to Connaught Place and stop near the mandir,” mixing English and Hindi. A Filipino driver could blend Tagalog and English in a single request. Even within one language, the accent shifts from Australian English to Nigerian English to American English which creates more variation than a generic “English” dataset can cover.
Then there’s human unpredictability. A calm driver may politely say, “Navigate to the office.” The same driver, running late, may snap, “Route to work now.” In emergencies, commands are often shouted, breaking prosody completely. And drivers are rarely alone, passengers interrupt, kids talk over adults and overlapping voices reach the mic together.
Why Generic Datasets Fail
Cars expose every blind spot in generic datasets. Most corpora are collected in quiet rooms, with long scripted prompts and single speakers. They simply do not prepare models for the reality of in-car speech.
The consequences show up quickly:
- False triggers: Wake words fire because bursts of road noise mimic the energy profile of “Hey.”
- Misrecognitions: Short commands like “AC low” are misclassified because the model expects longer phrasing.
- Code-switching breakdowns: Multilingual drivers confuse models trained on one language at a time.
- Uneven performance: One demographic or accent performs well, while another struggles.
These failures erode driver trust. After a few mistakes, people stop using voice altogether. Teams often try to patch the issues with model tweaks or filters, but without the right dataset foundation, those fixes only go so far.
So what would a dataset look like if it were intentionally built for cars?
Principles of Intentional Dataset Design
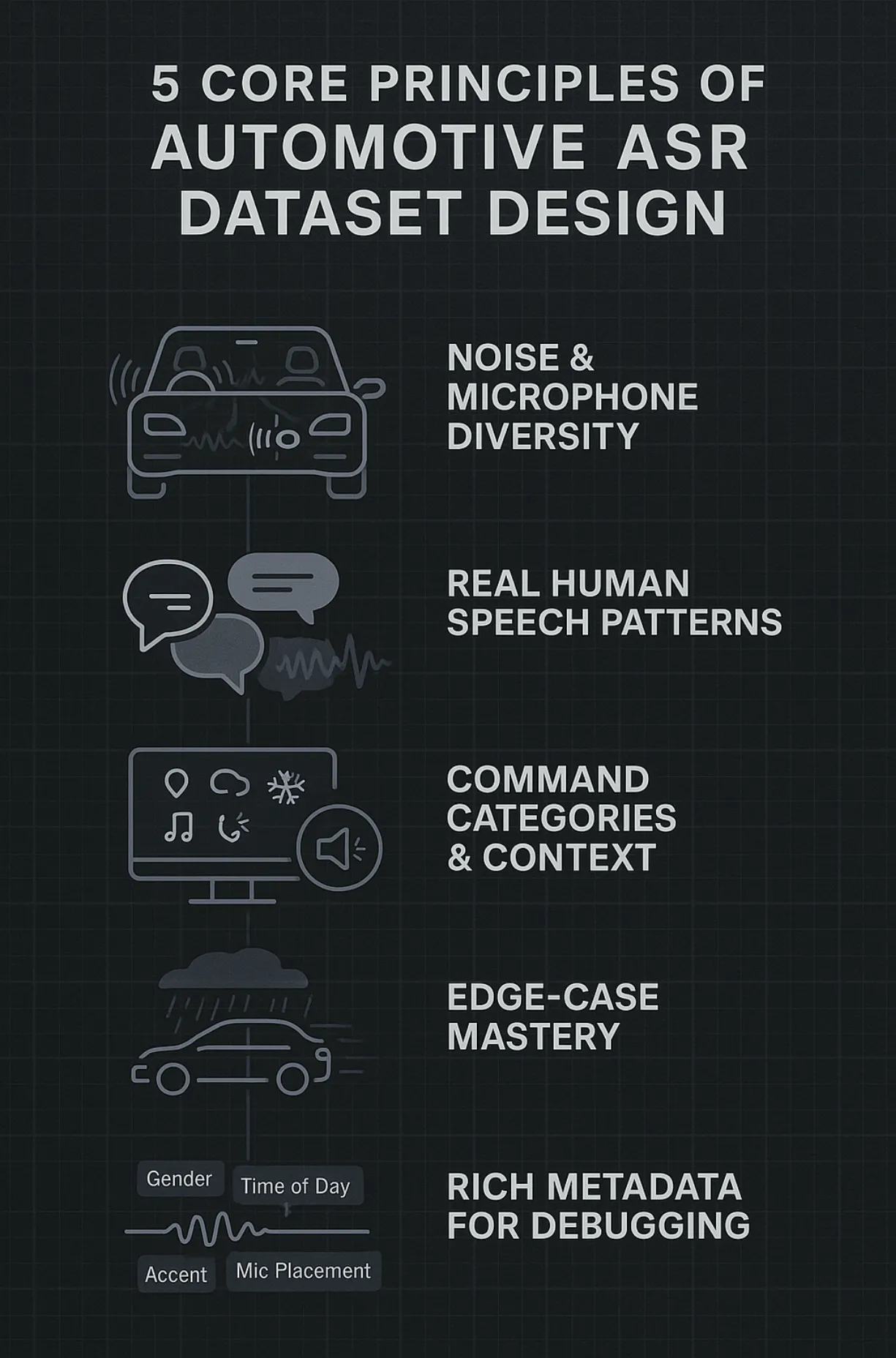 The answer is not “more hours of speech.” It is a smarter, more intentional collection. An automotive dataset must be engineered to reflect the acoustic, linguistic, and behavioral realities of driving.
The answer is not “more hours of speech.” It is a smarter, more intentional collection. An automotive dataset must be engineered to reflect the acoustic, linguistic, and behavioral realities of driving.
Key principles include:
- Noise and microphone diversity: Record across road types, weather conditions, and cabin states (windows up/down, AC on/off, engine idling or revving). Use multiple mic placements like on dashboard, steering wheel, headrest, since each captures audio differently.
- Real human speech: Include clipped commands, multilingual code-switching, stressed and calm speech, and overlapping voices. These are not outliers, they are daily reality in cars.
- Command categories and context: Capture the actual use cases: navigation, infotainment, climate, emergency, and mobile control. Represent both full sentences and clipped prompts like “Call home.”
- Edge-case mastery: Collect rare but impactful scenarios: heavy rain on the roof, shouted commands during sudden braking, children’s voices accidentally triggering wake words.
- Rich metadata: Tag every recording with speaker demographics, accent, mic placement, time of day, environment (moving vs stationary), and QA flags. Metadata transforms recordings into actionable data for debugging.
Designing data this way takes more effort, but it is the only path to building ASR systems drivers can trust.
Deep Dive into Linguistic and Demographic Coverage

Cars are global products. That means datasets cannot stop at “English” or “Mandarin”, they must reflect both major language groups and critical long-tail coverage.
- Macro groups: Asian, African, European, and Middle Eastern languages provide a broad foundation.
- Long-tail coverage: Specific languages and dialects like German, Spanish, Arabic, Tagalog, Igbo, Chichewa, Hindi, Tamil, Telugu, Malayalam, Punjabi, Marathi, Bengali, Korean, Chinese, Dutch, Portuguese, and multiple English accents ensure regional adoption.
- Code-switching: Drivers naturally mix languages like Hindi-English, Arabic-English, Tagalog-English and datasets must capture this to prevent breakdowns.
By building this diversity up front, teams avoid costly retraining when expanding to new markets.
Yet diversity alone is not enough; without metadata to contextualize each recording, performance issues remain invisible and hard to diagnose.
Learn more about our multilingual datasets designed to enhance ASR models across different languages and dialects.
Without metadata, failures look random. With metadata, patterns become clear. A spike in word error rate might appear mysterious until you see it happens only in “window open, highway” recordings.
That is why rich metadata is non-negotiable. It allows engineers to slice results, pinpoint weaknesses, and fix dataset gaps instead of overhauling entire models. In-car speech is too variable to debug without this layer of visibility.
Design principles and metadata show what an ideal dataset should look like, but the real challenge is building it at scale with consistency and control.
The FutureBeeAI Approach
At FutureBeeAI, we treat datasets as designed systems, not raw collections. Two pillars define our approach:
- A trained global community: Our contributors span continents, bringing linguistic and demographic variety. More importantly, they are trained to follow structured tasks. When the prompt says “navigation command, evening drive, windows down,” the recording reflects that condition.
- The Yugo platform: Yugo enforces structured collection, validates audio automatically, and applies multi-layer QA. At the same time, it keeps all recordings inside a secure, consent-driven pipeline with no personally identifiable data.
This combination of global expertise and platform discipline ensures datasets that are diverse, controlled, and enterprise-safe. It is how we translate the philosophy of intentional dataset design into practice.
Evaluation and Stress Testing
Even the best dataset must prove itself under evaluation. For in-car ASR, testing cannot rely on one clean benchmark. It must reflect the same diversity built into the training data.
That means creating splits by noise level, mic placement, demographic group, and command type. It means running stress tests with overlapping voices or shouted prompts. And it means tracking not just word error rate, but also false trigger rate and response latency because safety and trust depend on precision and speed.
Evaluation closes the loop between dataset design and model performance. Without it, blind spots remain hidden until drivers discover them on the road.
Building Trust in the Car Begins with Data
In-car speech recognition is not broken because models are weak. It is broken because datasets are blind. Cars combine harsh acoustics with messy human behavior, and generic corpora were never built for that reality.
The solution is intentional design. Datasets that capture real conditions, real voices, real languages and the metadata to debug them. At FutureBeeAI, this is how we approach in-car ASR: through global contributors, the Yugo platform, and a process that treats data as a system, not just a collection.
As cars evolve toward multimodal AI where voice works alongside gesture, gaze and touch. Speech will remain a cornerstone of safe, hands-free interaction. But the voice will only play that role if it is reliable. And reliability begins not with model tweaks, but with the data they learn from.
If your team is working on automotive ASR and wants to explore dataset design strategies for robust performance, contact FutureBeeAI to learn more.






